 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Efficient Multi-Scale Fovea for Semantic-Based Visual Search Attention
Apr 04, 2026Semantics are one of the primary sources of top-down preattentive information. Modern deep object detectors excel at extracting such valuable semantic cues from complex visual scenes. However, the size of the visual input to be processed by these detectors can become a bottleneck, particularly in terms of time costs, affecting an artificial attention system's biological plausibility and real-time deployability. Inspired by classical exponential density roll-off topologies, we apply a new artificial foveation module to our novel attention prediction pipeline: the Semantic-based Bayesian Attention (SemBA) framework. We aim at reducing detection-related computational costs without compromising visual task accuracy, thereby making SemBA more biologically plausible. The proposed multi-scale pyramidal field-of-view retains maximum acuity at an innermost level, around a focal point, while gradually increasing distortion for outer levels to mimic peripheral uncertainty via downsampling. In this work we evaluate the performance of our novel Multi-Scale Fovea, incorporated into \textit{SemBA}, on target-present visual search. We also compare it against other artificial foveal systems, and conduct ablation studies with different deep object detection models to assess the impact of the new topology in terms of computational costs. We experimentally demonstrate that including the new Multi-Scale Fovea module effectively reduces inherent processing costs while improving SemBA's scanpath prediction accuracy. Remarkably, we show that SemBA closely approximates human consistency while retaining the actual human fovea's proportions.
Semantic-Based Active Perception for Humanoid Visual Tasks with Foveal Sensors
Apr 16, 2024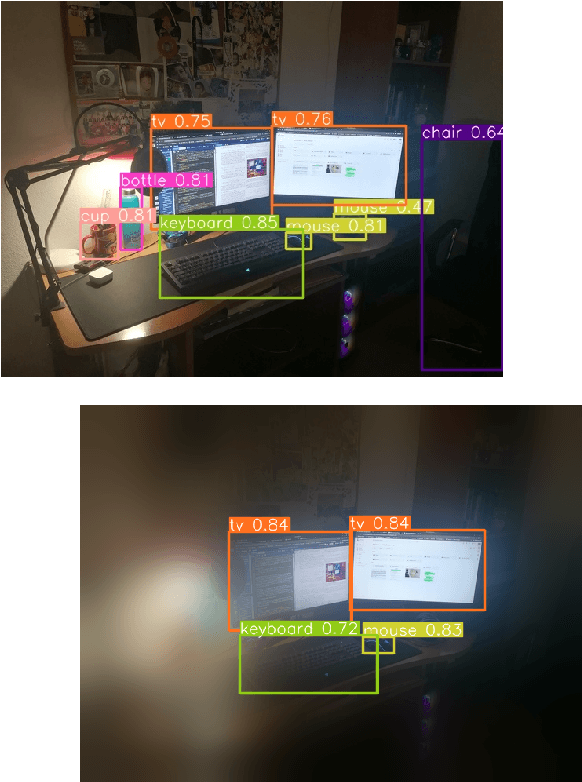
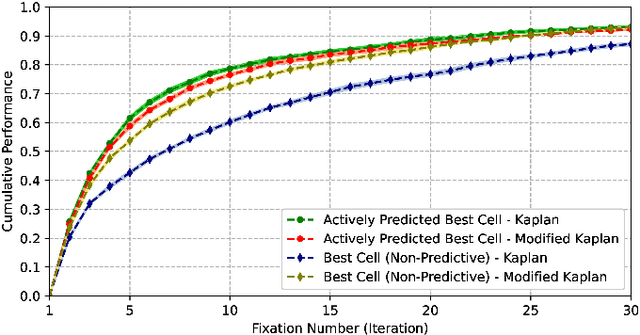
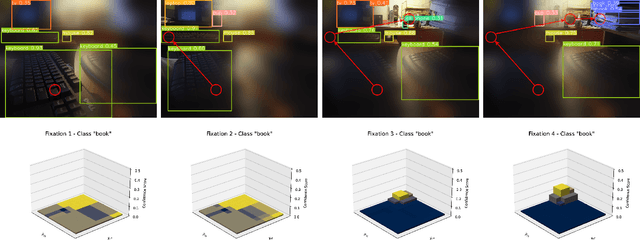
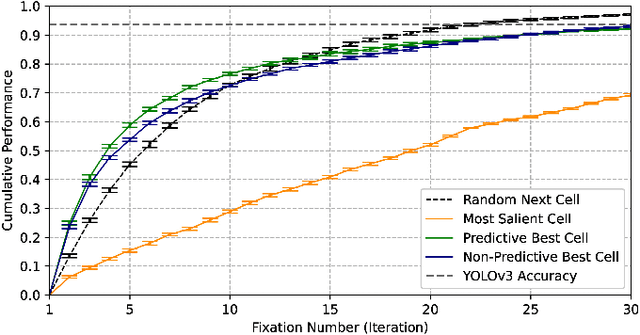
The aim of this work is to establish how accurately a recent semantic-based foveal active perception model is able to complete visual tasks that are regularly performed by humans, namely, scene exploration and visual search. This model exploits the ability of current object detectors to localize and classify a large number of object classes and to update a semantic description of a scene across multiple fixations. It has been used previously in scene exploration tasks. In this paper, we revisit the model and extend its application to visual search tasks. To illustrate the benefits of using semantic information in scene exploration and visual search tasks, we compare its performance against traditional saliency-based models. In the task of scene exploration, the semantic-based method demonstrates superior performance compared to the traditional saliency-based model in accurately representing the semantic information present in the visual scene. In visual search experiments, searching for instances of a target class in a visual field containing multiple distractors shows superior performance compared to the saliency-driven model and a random gaze selection algorithm. Our results demonstrate that semantic information, from the top-down, influences visual exploration and search tasks significantly, suggesting a potential area of research for integrating it with traditional bottom-up cues.