 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Based Active Perception for Humanoid Visual Tasks with Foveal Sensors
Paper and Code
Apr 16, 2024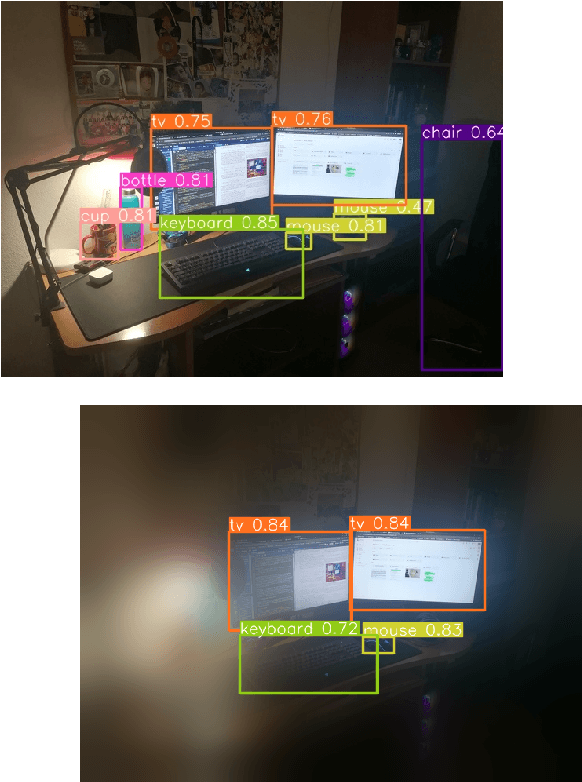
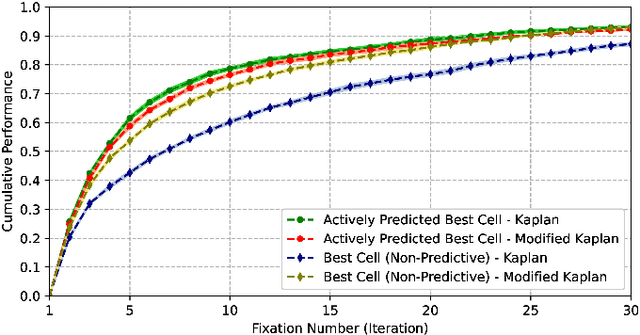
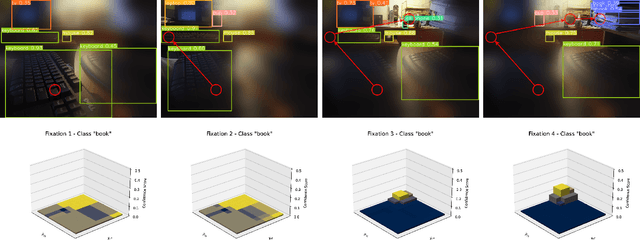
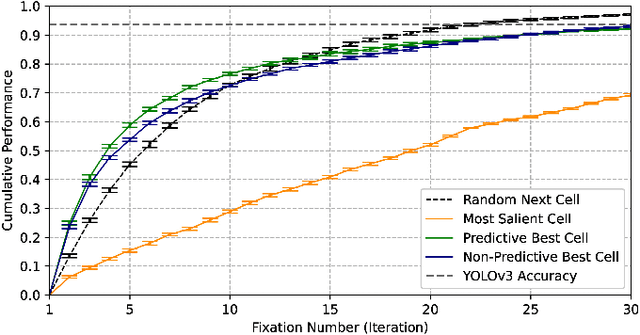
The aim of this work is to establish how accurately a recent semantic-based foveal active perception model is able to complete visual tasks that are regularly performed by humans, namely, scene exploration and visual search. This model exploits the ability of current object detectors to localize and classify a large number of object classes and to update a semantic description of a scene across multiple fixations. It has been used previously in scene exploration tasks. In this paper, we revisit the model and extend its application to visual search tasks. To illustrate the benefits of using semantic information in scene exploration and visual search tasks, we compare its performance against traditional saliency-based models. In the task of scene exploration, the semantic-based method demonstrates superior performance compared to the traditional saliency-based model in accurately representing the semantic information present in the visual scene. In visual search experiments, searching for instances of a target class in a visual field containing multiple distractors shows superior performance compared to the saliency-driven model and a random gaze selection algorithm. Our results demonstrate that semantic information, from the top-down, influences visual exploration and search tasks significantly, suggesting a potential area of research for integrating it with traditional bottom-up cues.