 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Pelage Pattern Unwrapping for Animal Re-identification
Jun 18, 2025Existing individual re-identification methods often struggle with the deformable nature of animal fur or skin patterns which undergo geometric distortions due to body movement and posture changes. In this paper, we propose a geometry-aware texture mapping approach that unwarps pelage patterns, the unique markings found on an animal's skin or fur, into a canonical UV space, enabling more robust feature matching. Our method uses surface normal estimation to guide the unwrapping process while preserving the geometric consistency between the 3D surface and the 2D texture space. We focus on two challenging species: Saimaa ringed seals (Pusa hispida saimensis) and leopards (Panthera pardus). Both species have distinctive yet highly deformable fur patterns. By integrating our pattern-preserving UV mapping with existing re-identification techniques, we demonstrate improved accuracy across diverse poses and viewing angles. Our framework does not require ground truth UV annotations and can be trained in a self-supervised manner. Experiments on seal and leopard datasets show up to a 5.4% improvement in re-identification accuracy.
Multimodal surface defect detection from wooden logs for sawing optimization
Mar 27, 2025We propose a novel, good-quality, and less demanding method for detecting knots on the surface of wooden logs using multimodal data fusion. Knots are a primary factor affecting the quality of sawn timber, making their detection fundamental to any timber grading or cutting optimization system. While X-ray computed tomography provides accurate knot locations and internal structures, it is often too slow or expensive for practical use. An attractive alternative is to use fast and cost-effective log surface measurements, such as laser scanners or RGB cameras, to detect surface knots and estimate the internal structure of wood. However, due to the small size of knots and noise caused by factors, such as bark and other natural variations, detection accuracy often remains low when only one measurement modality is used. In this paper, we demonstrate that by using a data fusion pipeline consisting of separate streams for RGB and point cloud data, combined by a late fusion module, higher knot detection accuracy can be achieved compared to using either modality alone. We further propose a simple yet efficient sawing angle optimization method that utilizes surface knot detections and cross-correlation to minimize the amount of unwanted arris knots, demonstrating its benefits over randomized sawing angles.
Mineral segmentation using electron microscope images and spectral sampling through multimodal graph neural networks
Mar 05, 2025



We propose a novel Graph Neural Network-based method for segmentation based on data fusion of multimodal Scanning Electron Microscope (SEM) images. In most cases, Backscattered Electron (BSE) images obtained using SEM do not contain sufficient information for mineral segmentation. Therefore, imaging is often complemented with point-wise Energy-Dispersive X-ray Spectroscopy (EDS) spectral measurements that provide highly accurate information about the chemical composition but that are time-consuming to acquire. This motivates the use of sparse spectral data in conjunction with BSE images for mineral segmentation. The unstructured nature of the spectral data makes most traditional image fusion techniques unsuitable for BSE-EDS fusion. We propose using graph neural networks to fuse the two modalities and segment the mineral phases simultaneously. Our results demonstrate that providing EDS data for as few as 1% of BSE pixels produces accurate segmentation, enabling rapid analysis of mineral samples. The proposed data fusion pipeline is versatile and can be adapted to other domains that involve image data and point-wise measurements.
Comprehensive Data Set for Automatic Single Camera Visual Speed Measurement
May 09, 2018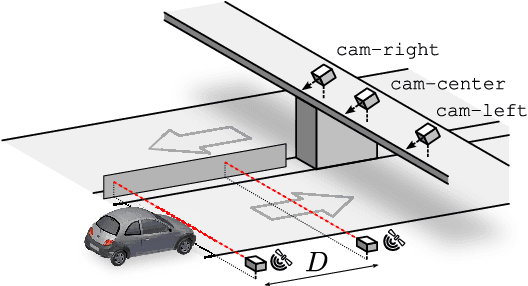
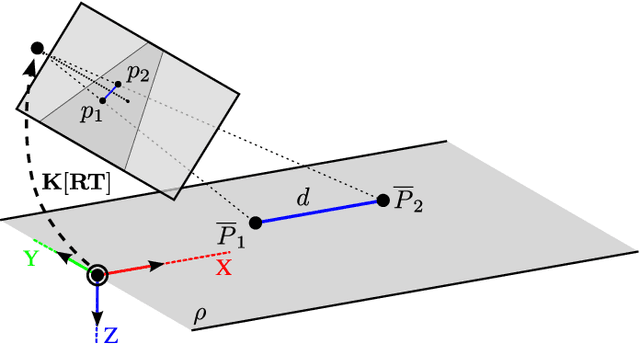


In this paper, we focus on traffic camera calibration and a visual speed measurement from a single monocular camera, which is an important task of visual traffic surveillance. Existing methods addressing this problem are difficult to compare due to a lack of a common data set with reliable ground truth. Therefore, it is not clear how the methods compare in various aspects and what factors are affecting their performance. We captured a new data set of 18 full-HD videos, each around 1 hr long, captured at six different locations. Vehicles in the videos (20865 instances in total) are annotated with the precise speed measurements from optical gates using LiDAR and verified with several reference GPS tracks. We made the data set available for download and it contains the videos and metadata (calibration, lengths of features in image, annotations, and so on) for future comparison and evaluation. Camera calibration is the most crucial part of the speed measurement; therefore, we provide a brief overview of the methods and analyze a recently published method for fully automatic camera calibration and vehicle speed measurement and report the results on this data set in detail.
Absolute Pose Estimation from Line Correspondences using Direct Linear Transformation
May 13, 2017



This work is concerned with camera pose estimation from correspondences of 3D/2D lines, i. e. with the Perspective-n-Line (PnL) problem. We focus on large line sets, which can be efficiently solved by methods using linear formulation of PnL. We propose a novel method "DLT-Combined-Lines" based on the Direct Linear Transformation (DLT) algorithm, which benefits from a new combination of two existing DLT methods for pose estimation. The method represents 2D structure by lines, and 3D structure by both points and lines. The redundant 3D information reduces the minimum required line correspondences to 5. A cornerstone of the method is a combined projection matri xestimated by the DLT algorithm. It contains multiple estimates of camera rotation and translation, which can be recovered after enforcing constraints of the matrix. Multiplicity of the estimates is exploited to improve the accuracy of the proposed method. For large line sets (10 and more), the method is comparable to the state-of-theart in accuracy of orientation estimation. It achieves state-of-the-art accuracy in estimation of camera position and it yields the smallest reprojection error under strong image noise. The method achieves top-3 results on real world data. The proposed method is also highly computationally effective, estimating the pose of 1000 lines in 12 ms on a desktop computer.
Camera Pose Estimation from Lines using Plücker Coordinates
Aug 09, 2016



Correspondences between 3D lines and their 2D images captured by a camera are often used to determine position and orientation of the camera in space. In this work, we propose a novel algebraic algorithm to estimate the camera pose. We parameterize 3D lines using Pl\"ucker coordinates that allow linear projection of the lines into the image. A line projection matrix is estimated using Linear Least Squares and the camera pose is then extracted from the matrix. An algebraic approach to handle mismatched line correspondences is also included. The proposed algorithm is an order of magnitude faster yet comparably accurate and robust to the state-of-the-art, it does not require initialization, and it yields only one solution. The described method requires at least 9 lines and is particularly suitable for scenarios with 25 and more lines, as also shown in the results.
Technical Report: Image Captioning with Semantically Similar Images
Jun 12, 2015


This report presents our submission to the MS COCO Captioning Challenge 2015. The method uses Convolutional Neural Network activations as an embedding to find semantically similar images. From these images, the most typical caption is selected based on unigram frequencies. Although the method received low scores with automated evaluation metrics and in human assessed average correctness, it is competitive in the ratio of captions which pass the Turing test and which are assessed as better or equal to human captions.