 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Feature Aggregation in Temporal Domain for Re-Identification
Mar 12, 2019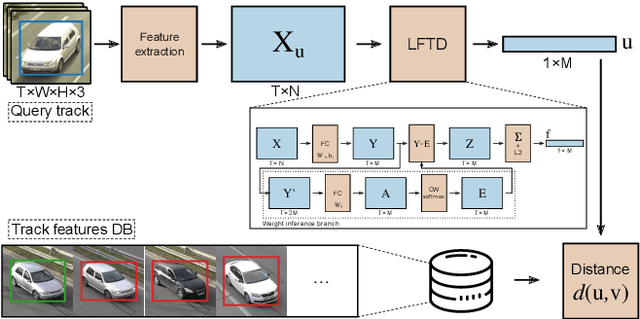

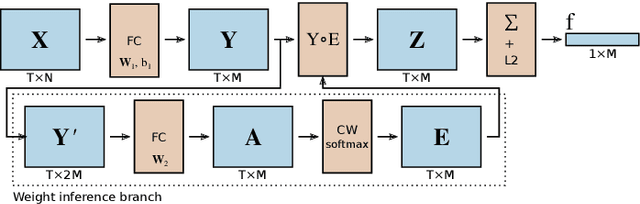

Person re-identification is a standard and established problem in the computer vision community. In recent years, vehicle re-identification is also getting more attention. In this paper, we focus on both these tasks and propose a method for aggregation of features in temporal domain as it is common to have multiple observations of the same object. The aggregation is based on weighting different elements of the feature vectors by different weights and it is trained in an end-to-end manner by a Siamese network. The experimental results show that our method outperforms other existing methods for feature aggregation in temporal domain on both vehicle and person re-identification tasks. Furthermore, to push research in vehicle re-identification further, we introduce a novel dataset CarsReId74k. The dataset is not limited to frontal/rear viewpoints. It contains 17,681 unique vehicles, 73,976 observed tracks, and 277,236 positive pairs. The dataset was captured by 66 cameras from various angles.
Comprehensive Data Set for Automatic Single Camera Visual Speed Measurement
May 09, 2018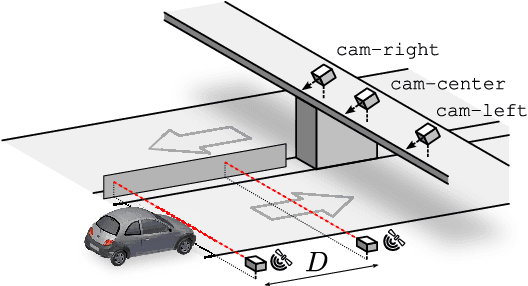
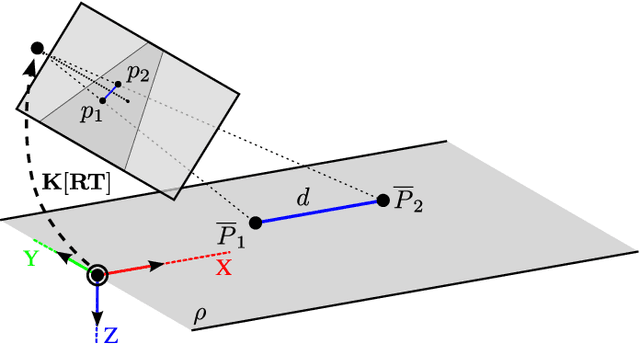


In this paper, we focus on traffic camera calibration and a visual speed measurement from a single monocular camera, which is an important task of visual traffic surveillance. Existing methods addressing this problem are difficult to compare due to a lack of a common data set with reliable ground truth. Therefore, it is not clear how the methods compare in various aspects and what factors are affecting their performance. We captured a new data set of 18 full-HD videos, each around 1 hr long, captured at six different locations. Vehicles in the videos (20865 instances in total) are annotated with the precise speed measurements from optical gates using LiDAR and verified with several reference GPS tracks. We made the data set available for download and it contains the videos and metadata (calibration, lengths of features in image, annotations, and so on) for future comparison and evaluation. Camera calibration is the most crucial part of the speed measurement; therefore, we provide a brief overview of the methods and analyze a recently published method for fully automatic camera calibration and vehicle speed measurement and report the results on this data set in detail.
BoxCars: Improving Fine-Grained Recognition of Vehicles using 3-D Bounding Boxes in Traffic Surveillance
Mar 09, 2018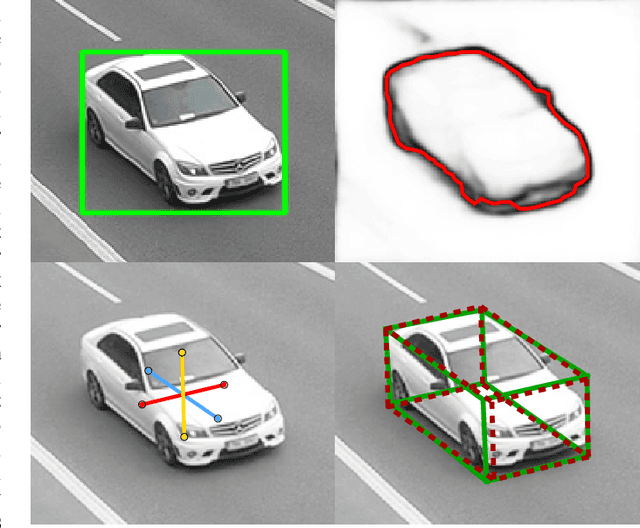



In this paper, we focus on fine-grained recognition of vehicles mainly in traffic surveillance applications. We propose an approach that is orthogonal to recent advancements in fine-grained recognition (automatic part discovery and bilinear pooling). In addition, in contrast to other methods focused on fine-grained recognition of vehicles, we do not limit ourselves to a frontal/rear viewpoint, but allow the vehicles to be seen from any viewpoint. Our approach is based on 3-D bounding boxes built around the vehicles. The bounding box can be automatically constructed from traffic surveillance data. For scenarios where it is not possible to use precise construction, we propose a method for an estimation of the 3-D bounding box. The 3-D bounding box is used to normalize the image viewpoint by "unpacking" the image into a plane. We also propose to randomly alter the color of the image and add a rectangle with random noise to a random position in the image during the training of convolutional neural networks (CNNs). We have collected a large fine-grained vehicle data set BoxCars116k, with 116k images of vehicles from various viewpoints taken by numerous surveillance cameras. We performed a number of experiments, which show that our proposed method significantly improves CNN classification accuracy (the accuracy is increased by up to 12% points and the error is reduced by up to 50% compared with CNNs without the proposed modifications). We also show that our method outperforms the state-of-the-art methods for fine-grained recognition.
Traffic Surveillance Camera Calibration by 3D Model Bounding Box Alignment for Accurate Vehicle Speed Measurement
Jun 01, 2017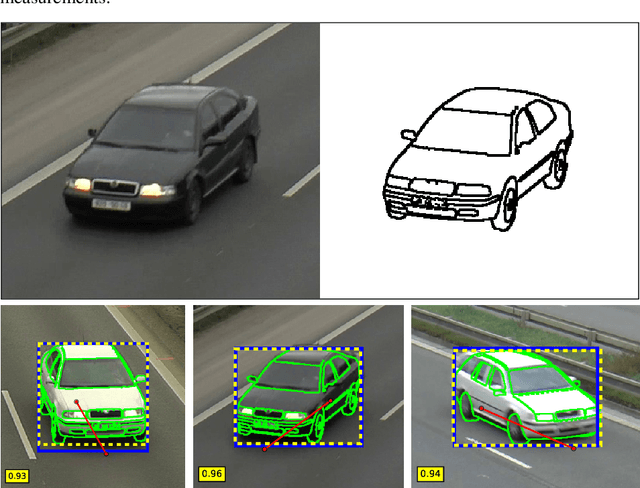
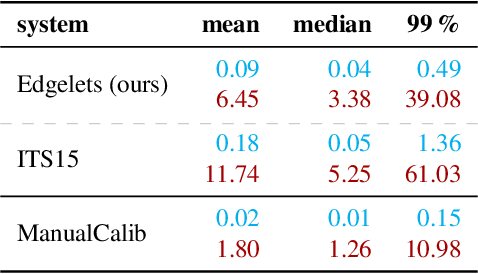


In this paper, we focus on fully automatic traffic surveillance camera calibration, which we use for speed measurement of passing vehicles. We improve over a recent state-of-the-art camera calibration method for traffic surveillance based on two detected vanishing points. More importantly, we propose a novel automatic scene scale inference method. The method is based on matching bounding boxes of rendered 3D models of vehicles with detected bounding boxes in the image. The proposed method can be used from arbitrary viewpoints, since it has no constraints on camera placement. We evaluate our method on the recent comprehensive dataset for speed measurement BrnoCompSpeed. Experiments show that our automatic camera calibration method by detection of two vanishing points reduces error by 50% (mean distance ratio error reduced from 0.18 to 0.09) compared to the previous state-of-the-art method. We also show that our scene scale inference method is more precise, outperforming both state-of-the-art automatic calibration method for speed measurement (error reduction by 86% -- 7.98km/h to 1.10km/h) and manual calibration (error reduction by 19% -- 1.35km/h to 1.10km/h). We also present qualitative results of the proposed automatic camera calibration method on video sequences obtained from real surveillance cameras in various places, and under different lighting conditions (night, dawn, day).