 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Labels: Multi-Agent Deep Reinforcement Learning for Point-feature Label Placement
Mar 02, 2023Over the past few years, Reinforcement Learning combined with Deep Learning techniques has successfully proven to solve complex problems in various domains including robotics, self-driving cars, finance, and gaming. In this paper, we are introducing Reinforcement Learning (RL) to another domain - visualization. Our novel point-feature label placement method utilizes Multi-Agent Deep Reinforcement Learning (MADRL) to learn label placement strategy, which is the first machine-learning-driven labeling method in contrast to existing hand-crafted algorithms designed by human experts. To facilitate the RL learning paradigm, we developed an environment where an agent acts as a proxy for a label, a short textual annotation that augments visualizations like geographical maps, illustrations, and technical drawings. Our results demonstrate that the strategy trained by our method significantly outperforms the random strategy of an untrained agent and also performs superior to the compared methods designed by human experts in terms of completeness (i.e., the number of placed labels). The trade-off is increased computation time, making the proposed method slower than compared methods. Nevertheless, our method is ideal for situations where the labeling can be computed in advance, and completeness is essential, such as cartographic maps, technical drawings, and medical atlases. Additionally, we conducted a user study to assess the perceived performance. The outcomes revealed that the participants considered the proposed method to be significantly better than the other examined methods. This indicates that the improved completeness is not just reflected in the quantitative metrics but also in the subjective evaluation of the participants.
Resource Efficient Mountainous Skyline Extraction using Shallow Learning
Jul 23, 2021


Skyline plays a pivotal role in mountainous visual geo-localization and localization/navigation of planetary rovers/UAVs and virtual/augmented reality applications. We present a novel mountainous skyline detection approach where we adapt a shallow learning approach to learn a set of filters to discriminate between edges belonging to sky-mountain boundary and others coming from different regions. Unlike earlier approaches, which either rely on extraction of explicit feature descriptors and their classification, or fine-tuning general scene parsing deep networks for sky segmentation, our approach learns linear filters based on local structure analysis. At test time, for every candidate edge pixel, a single filter is chosen from the set of learned filters based on pixel's structure tensor, and then applied to the patch around it. We then employ dynamic programming to solve the shortest path problem for the resultant multistage graph to get the sky-mountain boundary. The proposed approach is computationally faster than earlier methods while providing comparable performance and is more suitable for resource constrained platforms e.g., mobile devices, planetary rovers and UAVs. We compare our proposed approach against earlier skyline detection methods using four different data sets. Our code is available at \url{https://github.com/TouqeerAhmad/skyline_detection}.
Comparison of Semantic Segmentation Approaches for Horizon/Sky Line Detection
May 21, 2018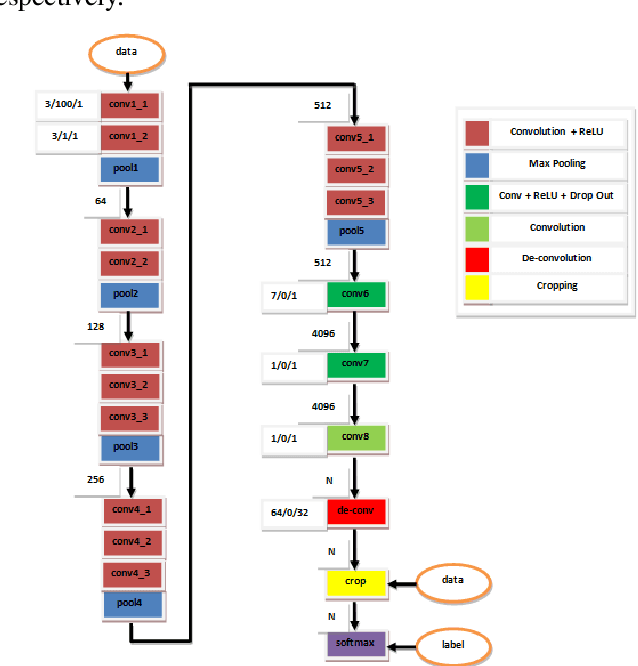
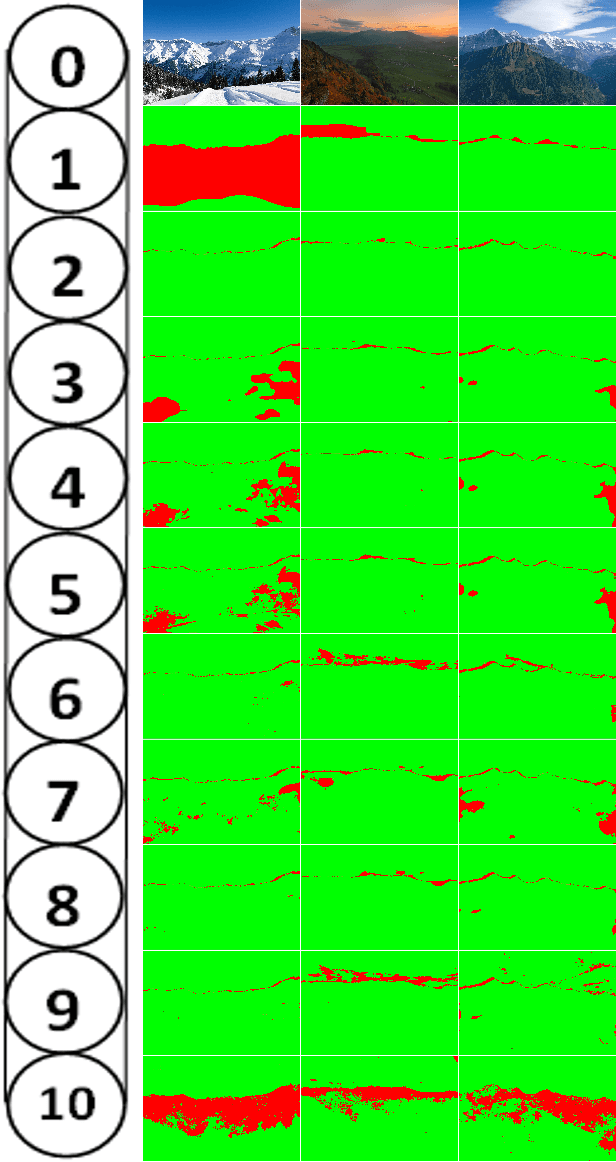
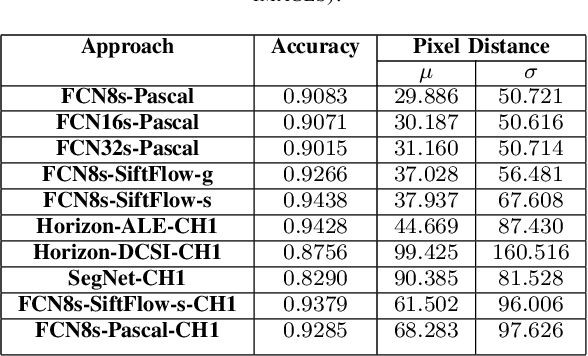
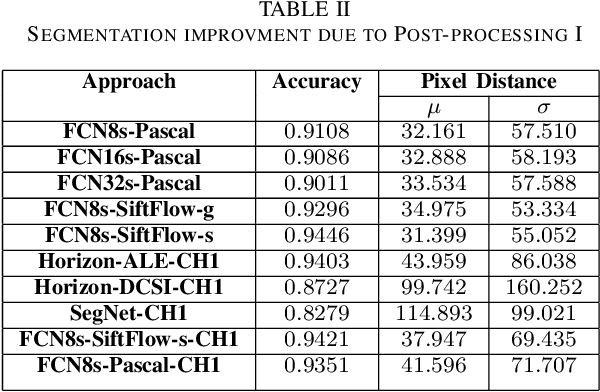
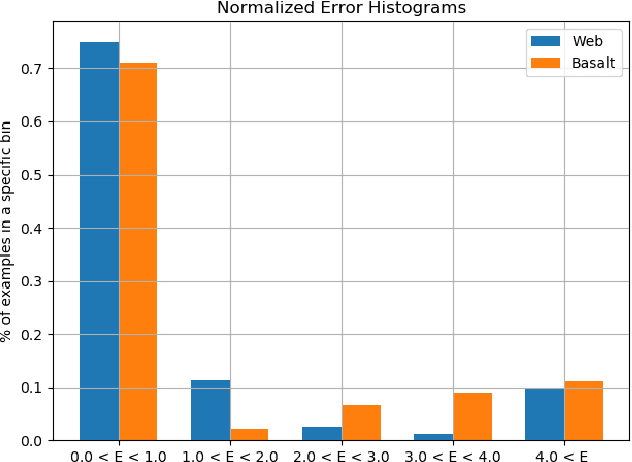
Horizon or skyline detection plays a vital role towards mountainous visual geo-localization, however most of the recently proposed visual geo-localization approaches rely on \textbf{user-in-the-loop} skyline detection methods. Detecting such a segmenting boundary fully autonomously would definitely be a step forward for these localization approaches. This paper provides a quantitative comparison of four such methods for autonomous horizon/sky line detection on an extensive data set. Specifically, we provide the comparison between four recently proposed segmentation methods; one explicitly targeting the problem of horizon detection\cite{Ahmad15}, second focused on visual geo-localization but relying on accurate detection of skyline \cite{Saurer16} and other two proposed for general semantic segmentation -- Fully Convolutional Networks (FCN) \cite{Long15} and SegNet\cite{Badrinarayanan15}. Each of the first two methods is trained on a common training set \cite{Baatz12} comprised of about 200 images while models for the third and fourth method are fine tuned for sky segmentation problem through transfer learning using the same data set. Each of the method is tested on an extensive test set (about 3K images) covering various challenging geographical, weather, illumination and seasonal conditions. We report average accuracy and average absolute pixel error for each of the presented formulation.
Absolute Pose Estimation from Line Correspondences using Direct Linear Transformation
May 13, 2017



This work is concerned with camera pose estimation from correspondences of 3D/2D lines, i. e. with the Perspective-n-Line (PnL) problem. We focus on large line sets, which can be efficiently solved by methods using linear formulation of PnL. We propose a novel method "DLT-Combined-Lines" based on the Direct Linear Transformation (DLT) algorithm, which benefits from a new combination of two existing DLT methods for pose estimation. The method represents 2D structure by lines, and 3D structure by both points and lines. The redundant 3D information reduces the minimum required line correspondences to 5. A cornerstone of the method is a combined projection matri xestimated by the DLT algorithm. It contains multiple estimates of camera rotation and translation, which can be recovered after enforcing constraints of the matrix. Multiplicity of the estimates is exploited to improve the accuracy of the proposed method. For large line sets (10 and more), the method is comparable to the state-of-theart in accuracy of orientation estimation. It achieves state-of-the-art accuracy in estimation of camera position and it yields the smallest reprojection error under strong image noise. The method achieves top-3 results on real world data. The proposed method is also highly computationally effective, estimating the pose of 1000 lines in 12 ms on a desktop computer.
Camera Pose Estimation from Lines using Plücker Coordinates
Aug 09, 2016



Correspondences between 3D lines and their 2D images captured by a camera are often used to determine position and orientation of the camera in space. In this work, we propose a novel algebraic algorithm to estimate the camera pose. We parameterize 3D lines using Pl\"ucker coordinates that allow linear projection of the lines into the image. A line projection matrix is estimated using Linear Least Squares and the camera pose is then extracted from the matrix. An algebraic approach to handle mismatched line correspondences is also included. The proposed algorithm is an order of magnitude faster yet comparably accurate and robust to the state-of-the-art, it does not require initialization, and it yields only one solution. The described method requires at least 9 lines and is particularly suitable for scenarios with 25 and more lines, as also shown in the results.