 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNN for Very Fast Ground Segmentation in Velodyne LiDAR Data
Paper and Code
Sep 07, 2017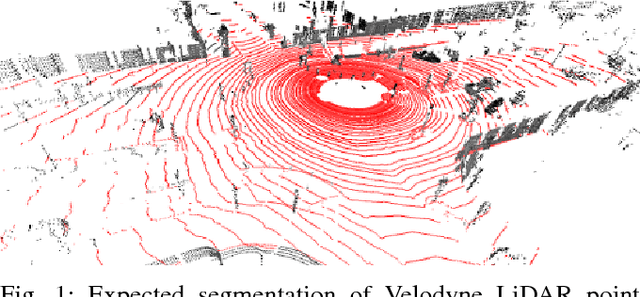

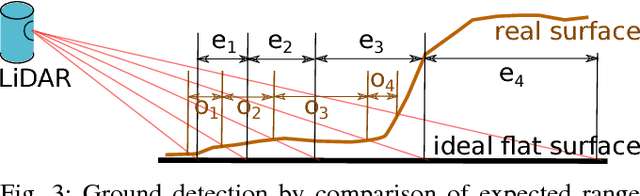
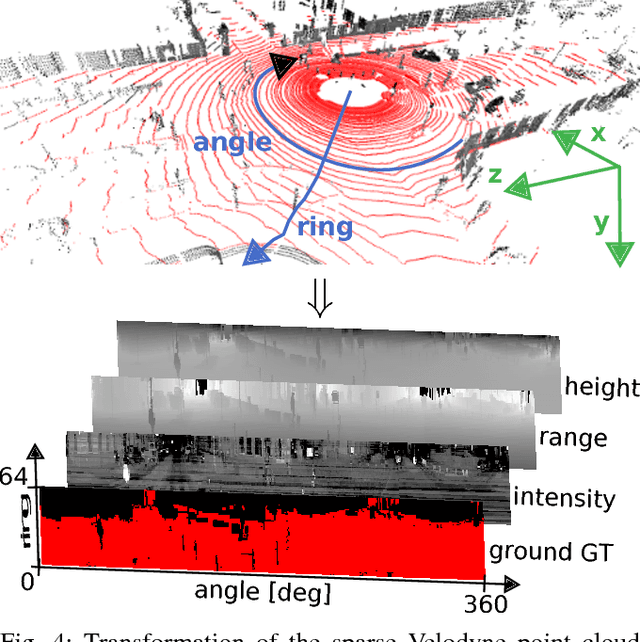
This paper presents a novel method for ground segmentation in Velodyne point clouds. We propose an encoding of sparse 3D data from the Velodyne sensor suitable for training a convolutional neural network (CNN). This general purpose approach is used for segmentation of the sparse point cloud into ground and non-ground points. The LiDAR data are represented as a multi-channel 2D signal where the horizontal axis corresponds to the rotation angle and the vertical axis the indexes channels (i.e. laser beams). Multiple topologies of relatively shallow CNNs (i.e. 3-5 convolutional layers) are trained and evaluated using a manually annotated dataset we prepared. The results show significant improvement of performance over the state-of-the-art method by Zhang et al. in terms of speed and also minor improvements in terms of accuracy.