Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePage Layout Analysis System for Unconstrained Historic Documents
Paper and Code
Feb 23, 2021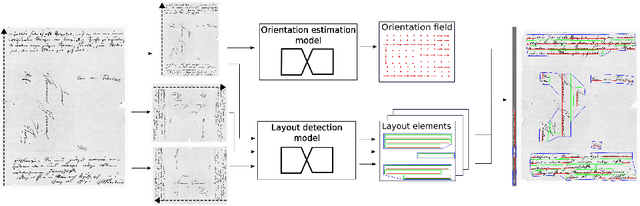
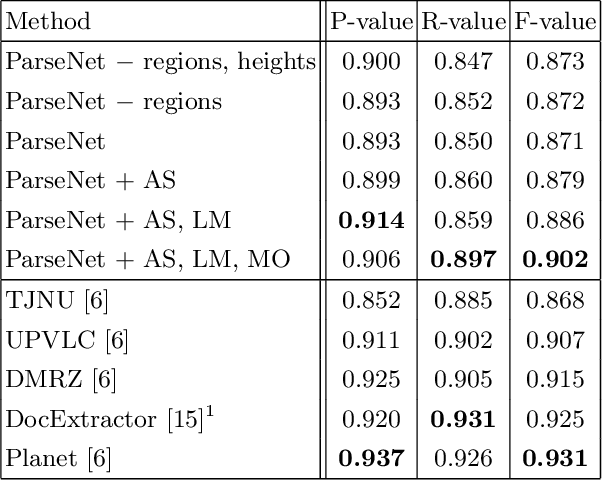

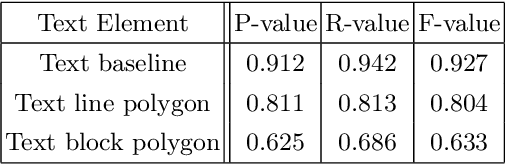
Extraction of text regions and individual text lines from historic documents is necessary for automatic transcription. We propose extending a CNN-based text baseline detection system by adding line height and text block boundary predictions to the model output, allowing the system to extract more comprehensive layout information. We also show that pixel-wise text orientation prediction can be used for processing documents with multiple text orientations. We demonstrate that the proposed method performs well on the cBAD baseline detection dataset. Additionally, we benchmark the method on newly introduced PERO layout dataset which we also make public.
* Submitted to ICDAR2021 conference
View paper on