 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying collaborators in large codebases
May 07, 2019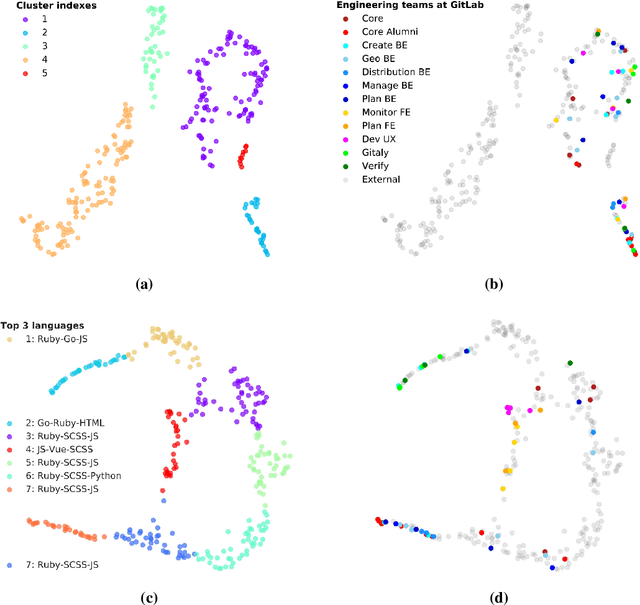
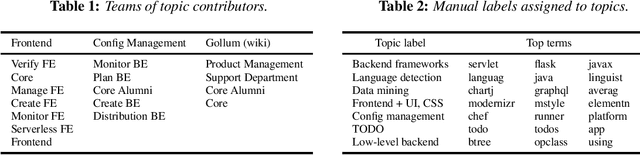
The way developers collaborate inside and particularly across teams often escapes management's attention, despite a formal organization with designated teams being defined. Observability of the actual, organically formed engineering structure provides decision makers invaluable additional tools to manage their talent pool. To identify existing inter and intra-team interactions - and suggest relevant opportunities for suitable collaborations - this paper studies contributors' commit activity, usage of programming languages, and code identifier topics by embedding and clustering them. We evaluate our findings collaborating with the GitLab organization, analyzing 117 of their open source projects. We show that we are able to restore their engineering organization in broad strokes, and also reveal hidden coding collaborations as well as justify in-house technical decisions.
STYLE-ANALYZER: fixing code style inconsistencies with interpretable unsupervised algorithms
Apr 01, 2019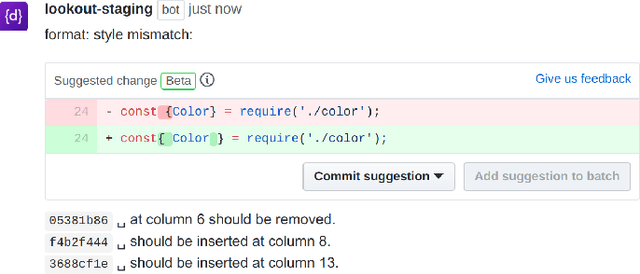
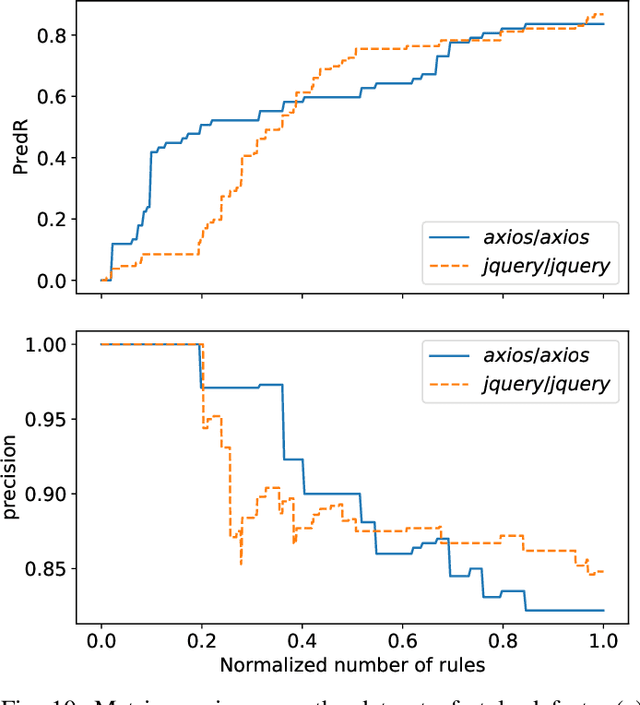
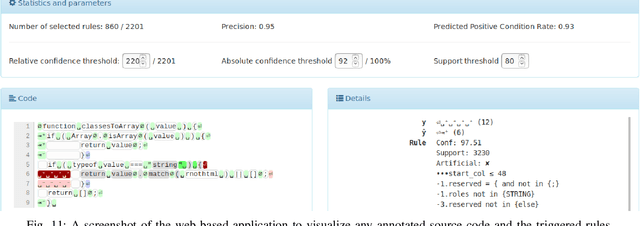
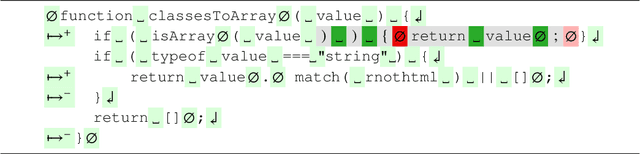
Source code reviews are manual, time-consuming, and expensive. Human involvement should be focused on analyzing the most relevant aspects of the program, such as logic and maintainability, rather than amending style, syntax, or formatting defects. Some tools with linting capabilities can format code automatically and report various stylistic violations for supported programming languages. They are based on rules written by domain experts, hence, their configuration is often tedious, and it is impractical for the given set of rules to cover all possible corner cases. Some machine learning-based solutions exist, but they remain uninterpretable black boxes. This paper introduces STYLE-ANALYZER, a new open source tool to automatically fix code formatting violations using the decision tree forest model which adapts to each codebase and is fully unsupervised. STYLE-ANALYZER is built on top of our novel assisted code review framework, Lookout. It accurately mines the formatting style of each analyzed Git repository and expresses the found format patterns with compact human-readable rules. STYLE-ANALYZER can then suggest style inconsistency fixes in the form of code review comments. We evaluate the output quality and practical relevance of STYLE-ANALYZER by demonstrating that it can reproduce the original style with high precision, measured on 19 popular JavaScript projects, and by showing that it yields promising results in fixing real style mistakes. STYLE-ANALYZER includes a web application to visualize how the rules are triggered. We release STYLE-ANALYZER as a reusable and extendable open source software package on GitHub for the benefit of the community.
How Document Pre-processing affects Keyphrase Extraction Performance
Oct 25, 2016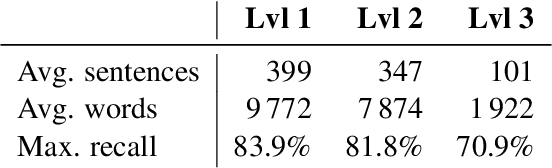
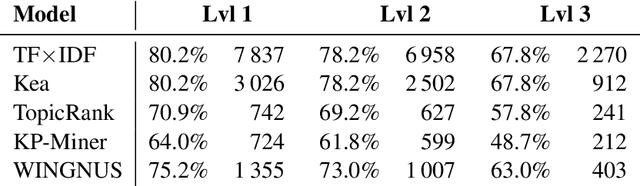
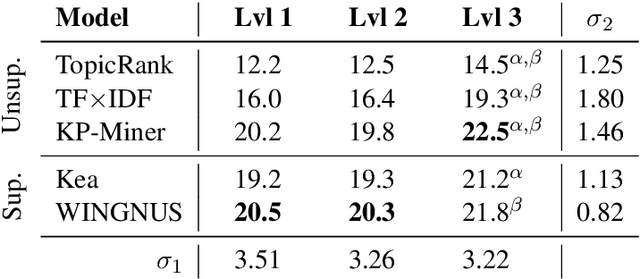
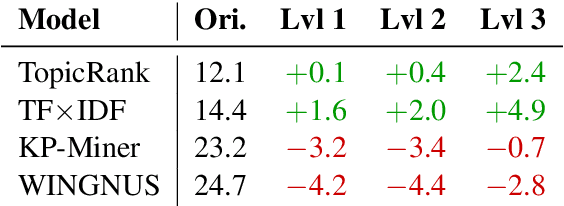
The SemEval-2010 benchmark dataset has brought renewed attention to the task of automatic keyphrase extraction. This dataset is made up of scientific articles that were automatically converted from PDF format to plain text and thus require careful preprocessing so that irrevelant spans of text do not negatively affect keyphrase extraction performance. In previous work, a wide range of document preprocessing techniques were described but their impact on the overall performance of keyphrase extraction models is still unexplored. Here, we re-assess the performance of several keyphrase extraction models and measure their robustness against increasingly sophisticated levels of document preprocessing.