 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTYLE-ANALYZER: fixing code style inconsistencies with interpretable unsupervised algorithms
Apr 01, 2019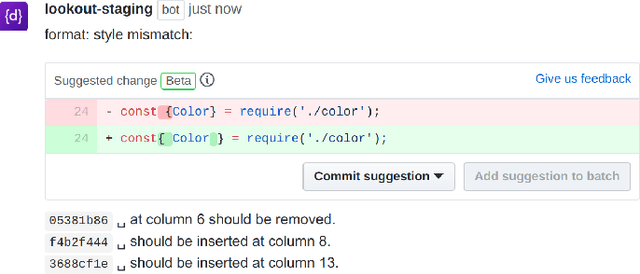
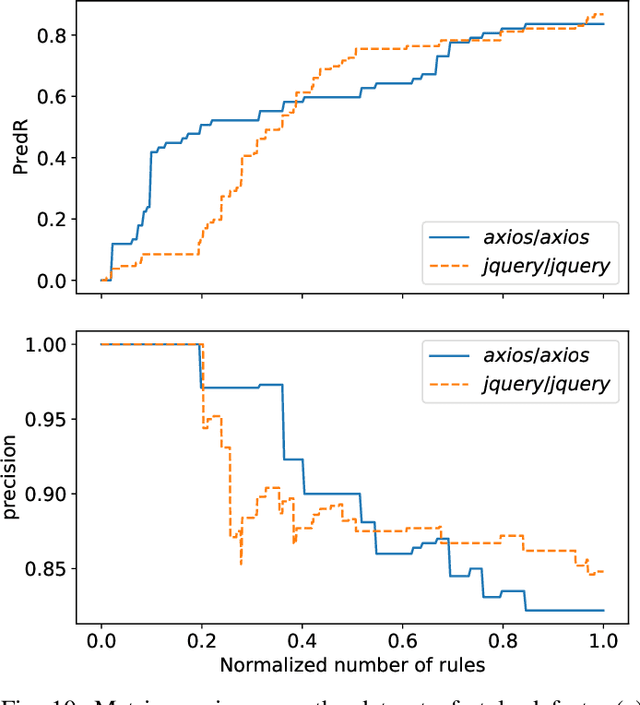
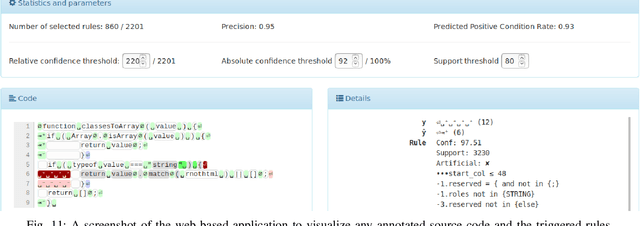
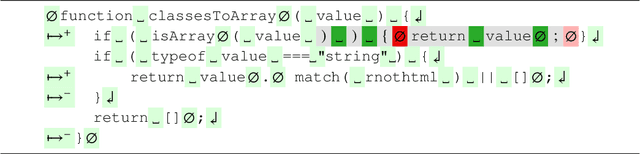
Source code reviews are manual, time-consuming, and expensive. Human involvement should be focused on analyzing the most relevant aspects of the program, such as logic and maintainability, rather than amending style, syntax, or formatting defects. Some tools with linting capabilities can format code automatically and report various stylistic violations for supported programming languages. They are based on rules written by domain experts, hence, their configuration is often tedious, and it is impractical for the given set of rules to cover all possible corner cases. Some machine learning-based solutions exist, but they remain uninterpretable black boxes. This paper introduces STYLE-ANALYZER, a new open source tool to automatically fix code formatting violations using the decision tree forest model which adapts to each codebase and is fully unsupervised. STYLE-ANALYZER is built on top of our novel assisted code review framework, Lookout. It accurately mines the formatting style of each analyzed Git repository and expresses the found format patterns with compact human-readable rules. STYLE-ANALYZER can then suggest style inconsistency fixes in the form of code review comments. We evaluate the output quality and practical relevance of STYLE-ANALYZER by demonstrating that it can reproduce the original style with high precision, measured on 19 popular JavaScript projects, and by showing that it yields promising results in fixing real style mistakes. STYLE-ANALYZER includes a web application to visualize how the rules are triggered. We release STYLE-ANALYZER as a reusable and extendable open source software package on GitHub for the benefit of the community.
Splitting source code identifiers using Bidirectional LSTM Recurrent Neural Network
Jul 19, 2018

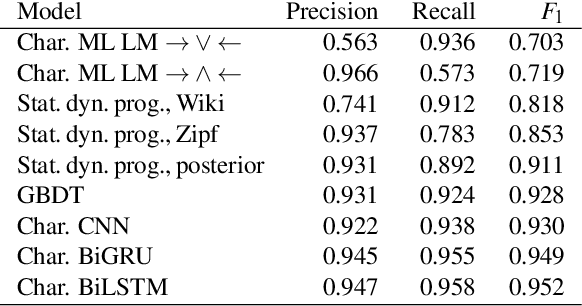

Programmers make rich use of natural language in the source code they write through identifiers and comments. Source code identifiers are selected from a pool of tokens which are strongly related to the meaning, naming conventions, and context. These tokens are often combined to produce more precise and obvious designations. Such multi-part identifiers count for 97% of all naming tokens in the Public Git Archive - the largest dataset of Git repositories to date. We introduce a bidirectional LSTM recurrent neural network to detect subtokens in source code identifiers. We trained that network on 41.7 million distinct splittable identifiers collected from 182,014 open source projects in Public Git Archive, and show that it outperforms several other machine learning models. The proposed network can be used to improve the upstream models which are based on source code identifiers, as well as improving developer experience allowing writing code without switching the keyboard case.