 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepPresenter: Environment-Grounded Reflection for Agentic Presentation Generation
Feb 26, 2026Presentation generation requires deep content research, coherent visual design, and iterative refinement based on observation. However, existing presentation agents often rely on predefined workflows and fixed templates. To address this, we present DeepPresenter, an agentic framework that adapts to diverse user intents, enables effective feedback-driven refinement, and generalizes beyond a scripted pipeline. Specifically, DeepPresenter autonomously plans, renders, and revises intermediate slide artifacts to support long-horizon refinement with environmental observations. Furthermore, rather than relying on self-reflection over internal signals (e.g., reasoning traces), our environment-grounded reflection conditions the generation process on perceptual artifact states (e.g., rendered slides), enabling the system to identify and correct presentation-specific issues during execution. Results on the evaluation set covering diverse presentation-generation scenarios show that DeepPresenter achieves state-of-the-art performance, and the fine-tuned 9B model remains highly competitive at substantially lower cost. Our project is available at: https://github.com/icip-cas/PPTAgent
RESPER: Computationally Modelling Resisting Strategies in Persuasive Conversations
Jan 26, 2021
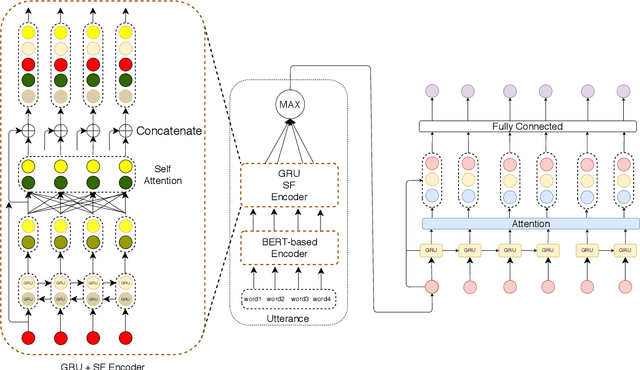

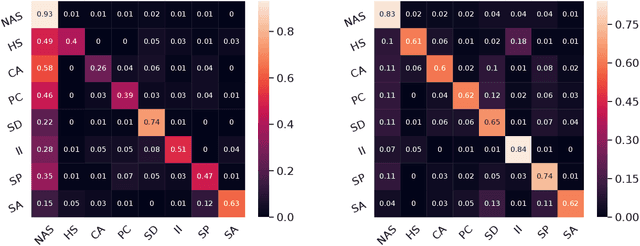
Modelling persuasion strategies as predictors of task outcome has several real-world applications and has received considerable attention from the computational linguistics community. However, previous research has failed to account for the resisting strategies employed by an individual to foil such persuasion attempts. Grounded in prior literature in cognitive and social psychology, we propose a generalised framework for identifying resisting strategies in persuasive conversations. We instantiate our framework on two distinct datasets comprising persuasion and negotiation conversations. We also leverage a hierarchical sequence-labelling neural architecture to infer the aforementioned resisting strategies automatically. Our experiments reveal the asymmetry of power roles in non-collaborative goal-directed conversations and the benefits accrued from incorporating resisting strategies on the final conversation outcome. We also investigate the role of different resisting strategies on the conversation outcome and glean insights that corroborate with past findings. We also make the code and the dataset of this work publicly available at https://github.com/americast/resper.
Multilingual Contextual Affective Analysis of LGBT People Portrayals in Wikipedia
Oct 21, 2020
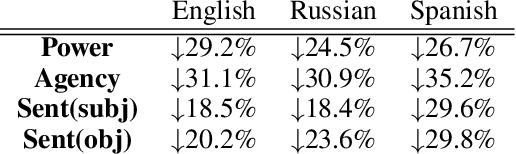

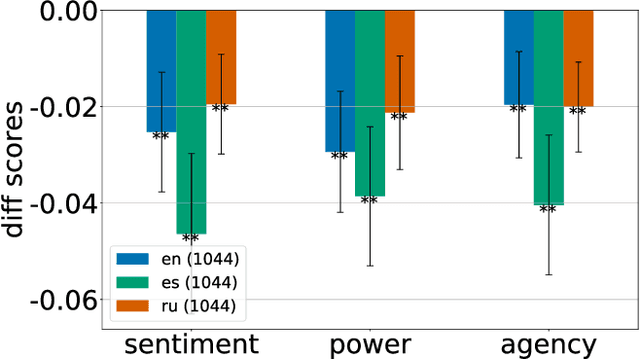
Specific lexical choices in how people are portrayed both reflect the writer's attitudes towards people in the narrative and influence the audience's reactions. Prior work has examined descriptions of people in English using contextual affective analysis, a natural language processing (NLP) technique that seeks to analyze how people are portrayed along dimensions of power, agency, and sentiment. Our work presents an extension of this methodology to multilingual settings, which is enabled by a new corpus that we collect and a new multilingual model. We additionally show how word connotations differ across languages and cultures, which makes existing English datasets and methods difficult to generalize. We then demonstrate the usefulness of our method by analyzing Wikipedia biography pages of members of the LGBT community across three languages: English, Russian, and Spanish. Our results show systematic differences in how the LGBT community is portrayed across languages, surfacing cultural differences in narratives and signs of social biases. Practically, this model can be used to surface Wikipedia articles for further manual analysis---articles that might contain content gaps or an imbalanced representation of particular social groups.
Who's to say what's funny? A computer using Language Models and Deep Learning, That's Who!
May 29, 2017
Humor is a defining characteristic of human beings. Our goal is to develop methods that automatically detect humorous statements and rank them on a continuous scale. In this paper we report on results using a Language Model approach, and outline our plans for using methods from Deep Learning.
Duluth at SemEval-2017 Task 6: Language Models in Humor Detection
Apr 27, 2017


This paper describes the Duluth system that participated in SemEval-2017 Task 6 #HashtagWars: Learning a Sense of Humor. The system participated in Subtasks A and B using N-gram language models, ranking highly in the task evaluation. This paper discusses the results of our system in the development and evaluation stages and from two post-evaluation runs.