 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDaily Predictions of F10.7 and F30 Solar Indices with Deep Learning
Apr 11, 2026The F10.7 and F30 solar indices are the solar radio fluxes measured at wavelengths of 10.7 cm and 30 cm, respectively, which are key indicators of solar activity. F10.7 is valuable for explaining the impact of solar ultraviolet (UV) radiation on the upper atmosphere of Earth, while F30 is more sensitive and could improve the reaction of thermospheric density to solar stimulation. In this study, we present a new deep learning model, named the Solar Index Network, or SINet for short, to predict daily values of the F10.7 and F30 solar indices. The SINet model is designed to make medium-term predictions of the index values (1-60 days in advance). The observed data used for SINet training were taken from the National Oceanic and Atmospheric Administration (NOAA) as well as Toyokawa and Nobeyama facilities. Our experimental results show that SINet performs better than five closely related statistical and deep learning methods for the prediction of F10.7. Furthermore, to our knowledge, this is the first time deep learning has been used to predict the F30 solar index.
Prediction of Geoeffective CMEs Using SOHO Images and Deep Learning
Jan 02, 2025The application of machine learning to the study of coronal mass ejections (CMEs) and their impacts on Earth has seen significant growth recently. Understanding and forecasting CME geoeffectiveness is crucial for protecting infrastructure in space and ensuring the resilience of technological systems on Earth. Here we present GeoCME, a deep-learning framework designed to predict, deterministically or probabilistically, whether a CME event that arrives at Earth will cause a geomagnetic storm. A geomagnetic storm is defined as a disturbance of the Earth's magnetosphere during which the minimum Dst index value is less than -50 nT. GeoCME is trained on observations from the instruments including LASCO C2, EIT and MDI on board the Solar and Heliospheric Observatory (SOHO), focusing on a dataset that includes 136 halo/partial halo CMEs in Solar Cycle 23. Using ensemble and transfer learning techniques, GeoCME is capable of extracting features hidden in the SOHO observations and making predictions based on the learned features. Our experimental results demonstrate the good performance of GeoCME, achieving a Matthew's correlation coefficient of 0.807 and a true skill statistics score of 0.714 when the tool is used as a deterministic prediction model. When the tool is used as a probabilistic forecasting model, it achieves a Brier score of 0.094 and a Brier skill score of 0.493. These results are promising, showing that the proposed GeoCME can help enhance our understanding of CME-triggered solar-terrestrial interactions.
FARA: Future-aware Ranking Algorithm for Fairness Optimization
May 26, 2023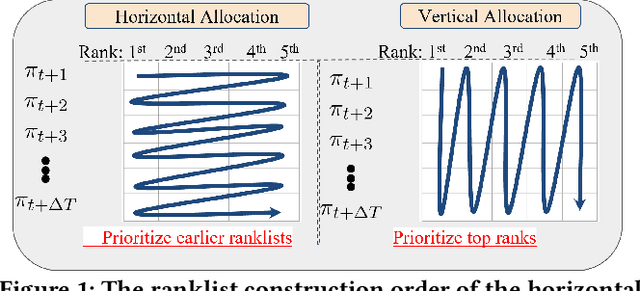

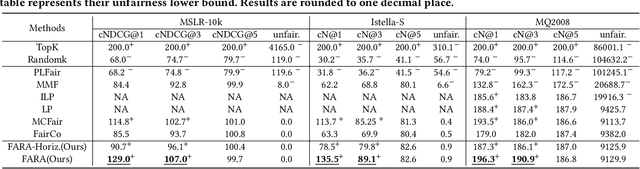
Ranking systems are the key components of modern Information Retrieval (IR) applications, such as search engines and recommender systems. Besides the ranking relevance to users, the exposure fairness to item providers has also been considered an important factor in ranking optimization. Many fair ranking algorithms have been proposed to jointly optimize both ranking relevance and fairness. However, we find that most existing fair ranking methods adopt greedy algorithms that only optimize rankings for the next immediate session or request. As shown in this paper, such a myopic paradigm could limit the upper bound of ranking optimization and lead to suboptimal performance in the long term. To this end, we propose FARA, a novel Future-Aware Ranking Algorithm for ranking relevance and fairness optimization. Instead of greedily optimizing rankings for the next immediate session, FARA plans ahead by jointly optimizing multiple ranklists together and saving them for future sessions. Particularly, FARA first uses the Taylor expansion to investigate how future ranklists will influence the overall fairness of the system. Then, based on the analysis of the Taylor expansion, FARA adopts a two-phase optimization algorithm where we first solve an optimal future exposure planning problem and then construct the optimal ranklists according to the optimal future exposure planning. Theoretically, we show that FARA is optimal for ranking relevance and fairness joint optimization. Empirically, our extensive experiments on three semi-synthesized datasets show that FARA is efficient, effective, and can deliver significantly better ranking performance compared to state-of-the-art fair ranking methods.
An In-depth Investigation of User Response Simulation for Conversational Search
Apr 17, 2023Conversational search has seen increased recent attention in both the IR and NLP communities. It seeks to clarify and solve a user's search need through multi-turn natural language interactions. However, most existing systems are trained and demonstrated with recorded or artificial conversation logs. Eventually, conversational search systems should be trained, evaluated, and deployed in an open-ended setting with unseen conversation trajectories. A key challenge is that training and evaluating such systems both require a human-in-the-loop, which is expensive and does not scale. One strategy for this is to simulate users, thereby reducing the scaling costs. However, current user simulators are either limited to only respond to yes-no questions from the conversational search system, or unable to produce high quality responses in general. In this paper, we show that current state-of-the-art user simulation system could be significantly improved by replacing it with a smaller but advanced natural language generation model. But rather than merely reporting this new state-of-the-art, we present an in-depth investigation of the task of simulating user response for conversational search. Our goal is to supplement existing works with an insightful hand-analysis of what challenges are still unsolved by the advanced model, as well as to propose our solutions for them. The challenges we identified include (1) dataset noise, (2) a blind spot that is difficult for existing models to learn, and (3) a specific type of misevaluation in the standard empirical setup. Except for the dataset noise issue, we propose solutions to cover the training blind spot and to avoid the misevaluation. Our proposed solutions lead to further improvements. Our best system improves the previous state-of-the-art significantly.
Reward-free Policy Imitation Learning for Conversational Search
Apr 17, 2023Existing conversational search studies mainly focused on asking better clarifying questions and/or improving search result quality. These works aim at retrieving better responses according to the search context, and their performances are evaluated on either single-turn tasks or multi-turn tasks under naive conversation policy settings. This leaves some questions about their applicability in real-world multi-turn conversations where realistically, each and every action needs to be made by the system itself, and search session efficiency is often an important concern of conversational search systems. While some recent works have identified the need for improving search efficiency in conversational search, they mostly require extensive data annotations and use hand-crafted rewards or heuristics to train systems that can achieve reasonable performance in a restricted number of turns, which has limited generalizability in practice. In this paper, we propose a reward-free conversation policy imitation learning framework, which can train a conversation policy without annotated conversation data or manually designed rewards. The trained conversation policy can be used to guide the conversational retrieval models to balance conversational search quality and efficiency. To evaluate the proposed conversational search system, we propose a new multi-turn-multi-response conversational evaluation metric named Expected Conversational Reciprocal Rank (ECRR). ECRR is designed to evaluate entire multi-turn conversational search sessions towards comprehensively evaluating both search result quality and search efficiency.
Zero-shot Clarifying Question Generation for Conversational Search
Feb 10, 2023A long-standing challenge for search and conversational assistants is query intention detection in ambiguous queries. Asking clarifying questions in conversational search has been widely studied and considered an effective solution to resolve query ambiguity. Existing work have explored various approaches for clarifying question ranking and generation. However, due to the lack of real conversational search data, they have to use artificial datasets for training, which limits their generalizability to real-world search scenarios. As a result, the industry has shown reluctance to implement them in reality, further suspending the availability of real conversational search interaction data. The above dilemma can be formulated as a cold start problem of clarifying question generation and conversational search in general. Furthermore, even if we do have large-scale conversational logs, it is not realistic to gather training data that can comprehensively cover all possible queries and topics in open-domain search scenarios. The risk of fitting bias when training a clarifying question retrieval/generation model on incomprehensive dataset is thus another important challenge. In this work, we innovatively explore generating clarifying questions in a zero-shot setting to overcome the cold start problem and we propose a constrained clarifying question generation system which uses both question templates and query facets to guide the effective and precise question generation. The experiment results show that our method outperforms existing state-of-the-art zero-shot baselines by a large margin. Human annotations to our model outputs also indicate our method generates 25.2\% more natural questions, 18.1\% more useful questions, 6.1\% less unnatural and 4\% less useless questions.
Marginal-Certainty-aware Fair Ranking Algorithm
Dec 18, 2022Ranking systems are ubiquitous in modern Internet services, including online marketplaces, social media, and search engines. Traditionally, ranking systems only focus on how to get better relevance estimation. When relevance estimation is available, they usually adopt a user-centric optimization strategy where ranked lists are generated by sorting items according to their estimated relevance. However, such user-centric optimization ignores the fact that item providers also draw utility from ranking systems. It has been shown in existing research that such user-centric optimization will cause much unfairness to item providers, followed by unfair opportunities and unfair economic gains for item providers. To address ranking fairness, many fair ranking methods have been proposed. However, as we show in this paper, these methods could be suboptimal as they directly rely on the relevance estimation without being aware of the uncertainty (i.e., the variance of the estimated relevance). To address this uncertainty, we propose a novel Marginal-Certainty-aware Fair algorithm named MCFair. MCFair jointly optimizes fairness and user utility, while relevance estimation is constantly updated in an online manner. In MCFair, we first develop a ranking objective that includes uncertainty, fairness, and user utility. Then we directly use the gradient of the ranking objective as the ranking score. We theoretically prove that MCFair based on gradients is optimal for the aforementioned ranking objective. Empirically, we find that on semi-synthesized datasets, MCFair is effective and practical and can deliver superior performance compared to state-of-the-art fair ranking methods. To facilitate reproducibility, we release our code https://github.com/Taosheng-ty/WSDM22-MCFair.
Simulating and Modeling the Risk of Conversational Search
Jan 01, 2022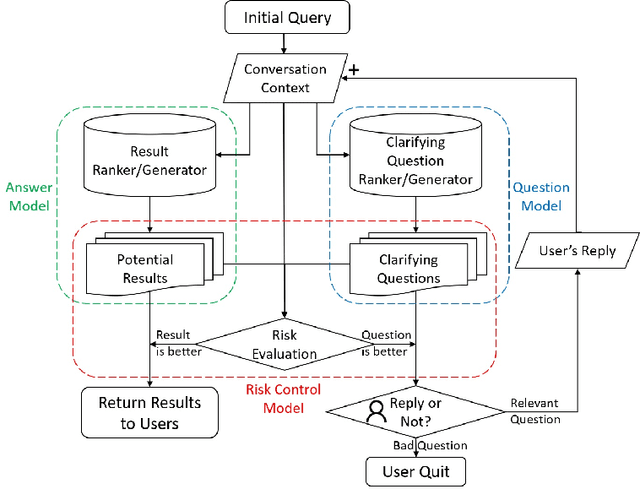
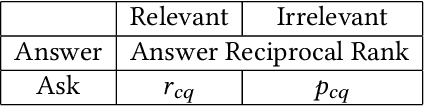
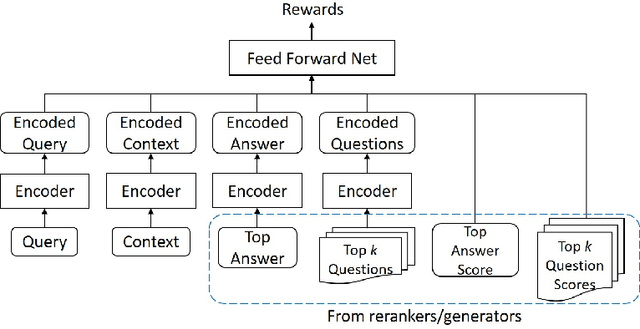
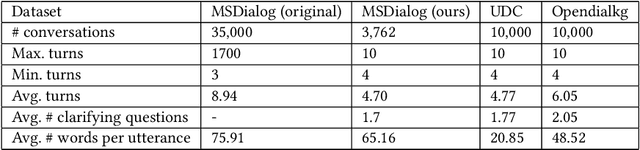
In conversational search, agents can interact with users by asking clarifying questions to increase their chance to find better results. Many recent works and shared tasks in both NLP and IR communities have focused on identifying the need of asking clarifying questions and methodologies of generating them. These works assume asking clarifying questions is a safe alternative to retrieving results. As existing conversational search models are far from perfect, it's possible and common that they could retrieve or generate bad clarifying questions. Asking too many clarifying questions can also drain user's patience when the user prefers searching efficiency over correctness. Hence, these models can get backfired and harm user's search experience because of these risks by asking clarifying questions. In this work, we propose a simulation framework to simulate the risk of asking questions in conversational search and further revise a risk-aware conversational search model to control the risk. We show the model's robustness and effectiveness through extensive experiments on three conversations datasets, including MSDialog, Ubuntu Dialog Corpus, and Opendialkg in which we compare it with multiple baselines. We show that the risk-control module can work with two different re-ranker models and outperform all the baselines in most of our experiments.
Controlling the Risk of Conversational Search via Reinforcement Learning
Jan 15, 2021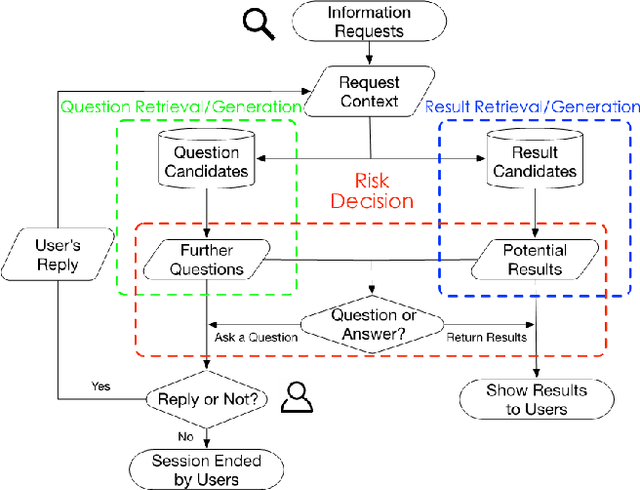



Users often formulate their search queries with immature language without well-developed keywords and complete structures. Such queries fail to express their true information needs and raise ambiguity as fragmental language often yield various interpretations and aspects. This gives search engines a hard time processing and understanding the query, and eventually leads to unsatisfactory retrieval results. An alternative approach to direct answer while facing an ambiguous query is to proactively ask clarifying questions to the user. Recent years have seen many works and shared tasks from both NLP and IR community about identifying the need for asking clarifying question and methodology to generate them. An often neglected fact by these works is that although sometimes the need for clarifying questions is correctly recognized, the clarifying questions these system generate are still off-topic and dissatisfaction provoking to users and may just cause users to leave the conversation. In this work, we propose a risk-aware conversational search agent model to balance the risk of answering user's query and asking clarifying questions. The agent is fully aware that asking clarifying questions can potentially collect more information from user, but it will compare all the choices it has and evaluate the risks. Only after then, it will make decision between answering or asking. To demonstrate that our system is able to retrieve better answers, we conduct experiments on the MSDialog dataset which contains real-world customer service conversations from Microsoft products community. We also purpose a reinforcement learning strategy which allows us to train our model on the original dataset directly and saves us from any further data annotation efforts. Our experiment results show that our risk-aware conversational search agent is able to significantly outperform strong non-risk-aware baselines.
UMDSub at SemEval-2018 Task 2: Multilingual Emoji Prediction Multi-channel Convolutional Neural Network on Subword Embedding
May 25, 2018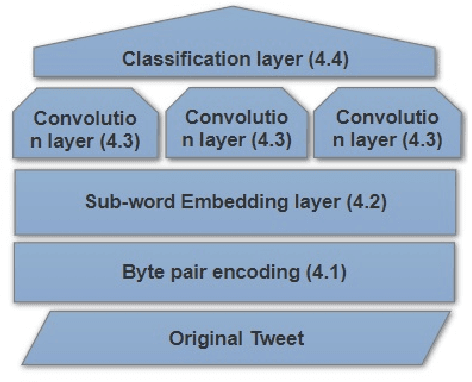
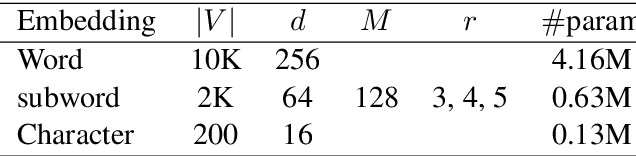
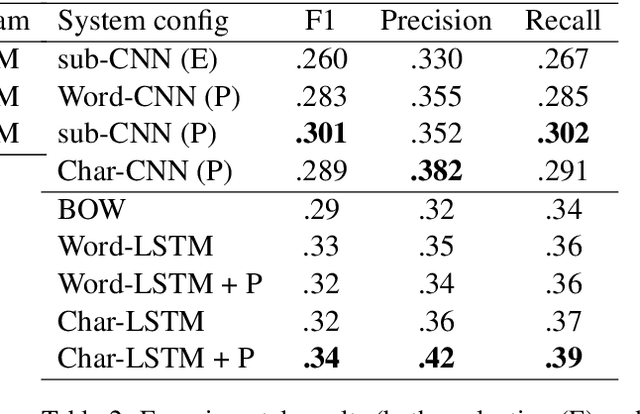
This paper describes the UMDSub system that participated in Task 2 of SemEval-2018. We developed a system that predicts an emoji given the raw text in a English tweet. The system is a Multi-channel Convolutional Neural Network based on subword embeddings for the representation of tweets. This model improves on character or word based methods by about 2\%. Our system placed 21st of 48 participating systems in the official evaluation.