 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Clarifying Question Generation for Conversational Search
Feb 10, 2023A long-standing challenge for search and conversational assistants is query intention detection in ambiguous queries. Asking clarifying questions in conversational search has been widely studied and considered an effective solution to resolve query ambiguity. Existing work have explored various approaches for clarifying question ranking and generation. However, due to the lack of real conversational search data, they have to use artificial datasets for training, which limits their generalizability to real-world search scenarios. As a result, the industry has shown reluctance to implement them in reality, further suspending the availability of real conversational search interaction data. The above dilemma can be formulated as a cold start problem of clarifying question generation and conversational search in general. Furthermore, even if we do have large-scale conversational logs, it is not realistic to gather training data that can comprehensively cover all possible queries and topics in open-domain search scenarios. The risk of fitting bias when training a clarifying question retrieval/generation model on incomprehensive dataset is thus another important challenge. In this work, we innovatively explore generating clarifying questions in a zero-shot setting to overcome the cold start problem and we propose a constrained clarifying question generation system which uses both question templates and query facets to guide the effective and precise question generation. The experiment results show that our method outperforms existing state-of-the-art zero-shot baselines by a large margin. Human annotations to our model outputs also indicate our method generates 25.2\% more natural questions, 18.1\% more useful questions, 6.1\% less unnatural and 4\% less useless questions.
Adaptive Self-training for Few-shot Neural Sequence Labeling
Oct 07, 2020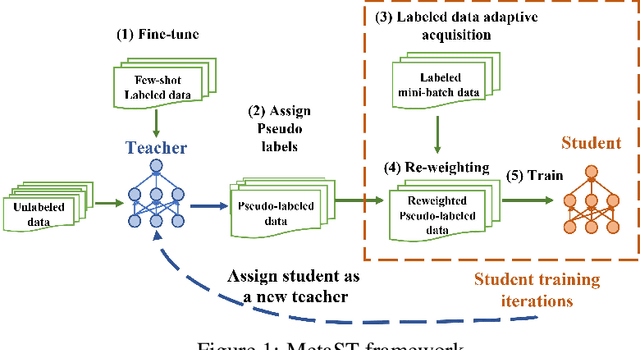
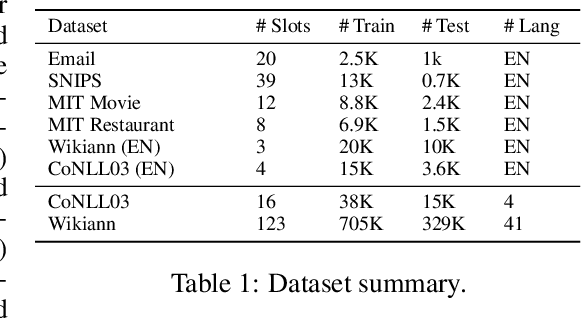
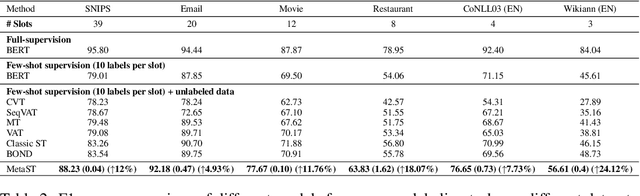
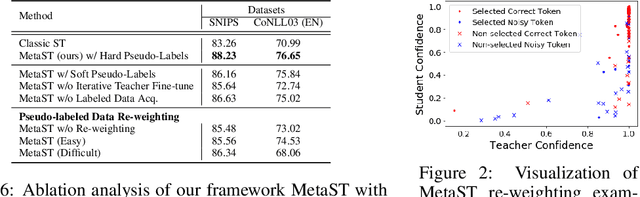
Neural sequence labeling is an important technique employed for many Natural Language Processing (NLP) tasks, such as Named Entity Recognition (NER), slot tagging for dialog systems and semantic parsing. Large-scale pre-trained language models obtain very good performance on these tasks when fine-tuned on large amounts of task-specific labeled data. However, such large-scale labeled datasets are difficult to obtain for several tasks and domains due to the high cost of human annotation as well as privacy and data access constraints for sensitive user applications. This is exacerbated for sequence labeling tasks requiring such annotations at token-level. In this work, we develop techniques to address the label scarcity challenge for neural sequence labeling models. Specifically, we develop self-training and meta-learning techniques for few-shot training of neural sequence taggers, namely MetaST. While self-training serves as an effective mechanism to learn from large amounts of unlabeled data -- meta-learning helps in adaptive sample re-weighting to mitigate error propagation from noisy pseudo-labels. Extensive experiments on six benchmark datasets including two massive multilingual NER datasets and four slot tagging datasets for task-oriented dialog systems demonstrate the effectiveness of our method with around 10% improvement over state-of-the-art systems for the 10-shot setting.