 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulating and Modeling the Risk of Conversational Search
Paper and Code
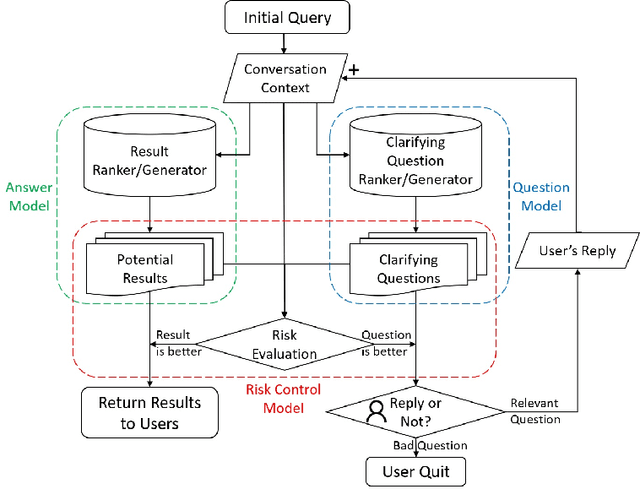
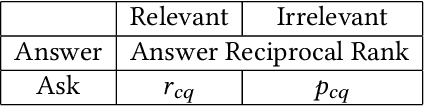
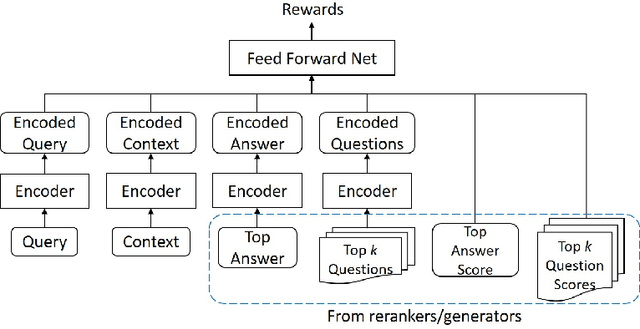
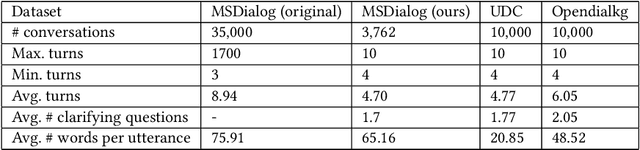
In conversational search, agents can interact with users by asking clarifying questions to increase their chance to find better results. Many recent works and shared tasks in both NLP and IR communities have focused on identifying the need of asking clarifying questions and methodologies of generating them. These works assume asking clarifying questions is a safe alternative to retrieving results. As existing conversational search models are far from perfect, it's possible and common that they could retrieve or generate bad clarifying questions. Asking too many clarifying questions can also drain user's patience when the user prefers searching efficiency over correctness. Hence, these models can get backfired and harm user's search experience because of these risks by asking clarifying questions. In this work, we propose a simulation framework to simulate the risk of asking questions in conversational search and further revise a risk-aware conversational search model to control the risk. We show the model's robustness and effectiveness through extensive experiments on three conversations datasets, including MSDialog, Ubuntu Dialog Corpus, and Opendialkg in which we compare it with multiple baselines. We show that the risk-control module can work with two different re-ranker models and outperform all the baselines in most of our experiments.