 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe-Construct: Redefining Construction Safety Violation Recognition as 3D Multi-View Engagement Task
Apr 15, 2025Recognizing safety violations in construction environments is critical yet remains underexplored in computer vision. Existing models predominantly rely on 2D object detection, which fails to capture the complexities of real-world violations due to: (i) an oversimplified task formulation treating violation recognition merely as object detection, (ii) inadequate validation under realistic conditions, (iii) absence of standardized baselines, and (iv) limited scalability from the unavailability of synthetic dataset generators for diverse construction scenarios. To address these challenges, we introduce Safe-Construct, the first framework that reformulates violation recognition as a 3D multi-view engagement task, leveraging scene-level worker-object context and 3D spatial understanding. We also propose the Synthetic Indoor Construction Site Generator (SICSG) to create diverse, scalable training data, overcoming data limitations. Safe-Construct achieves a 7.6% improvement over state-of-the-art methods across four violation types. We rigorously evaluate our approach in near-realistic settings, incorporating four violations, four workers, 14 objects, and challenging conditions like occlusions (worker-object, worker-worker) and variable illumination (back-lighting, overexposure, sunlight). By integrating 3D multi-view spatial understanding and synthetic data generation, Safe-Construct sets a new benchmark for scalable and robust safety monitoring in high-risk industries. Project Website: https://Safe-Construct.github.io/Safe-Construct
Improving Deep Learning-based Defect Detection on Window Frames with Image Processing Strategies
Sep 13, 2023Detecting subtle defects in window frames, including dents and scratches, is vital for upholding product integrity and sustaining a positive brand perception. Conventional machine vision systems often struggle to identify these defects in challenging environments like construction sites. In contrast, modern vision systems leveraging machine and deep learning (DL) are emerging as potent tools, particularly for cosmetic inspections. However, the promise of DL is yet to be fully realized. A few manufacturers have established a clear strategy for AI integration in quality inspection, hindered mainly by issues like scarce clean datasets and environmental changes that compromise model accuracy. Addressing these challenges, our study presents an innovative approach that amplifies defect detection in DL models, even with constrained data resources. The paper proposes a new defect detection pipeline called InspectNet (IPT-enhanced UNET) that includes the best combination of image enhancement and augmentation techniques for pre-processing the dataset and a Unet model tuned for window frame defect detection and segmentation. Experiments were carried out using a Spot Robot doing window frame inspections . 16 variations of the dataset were constructed using different image augmentation settings. Results of the experiments revealed that, on average, across all proposed evaluation measures, Unet outperformed all other algorithms when IPT-enhanced augmentations were applied. In particular, when using the best dataset, the average Intersection over Union (IoU) values achieved were IPT-enhanced Unet, reaching 0.91 of mIoU.
Component Segmentation of Engineering Drawings Using Graph Convolutional Networks
Dec 01, 2022



We present a data-driven framework to automate the vectorization and machine interpretation of 2D engineering part drawings. In industrial settings, most manufacturing engineers still rely on manual reads to identify the topological and manufacturing requirements from drawings submitted by designers. The interpretation process is laborious and time-consuming, which severely inhibits the efficiency of part quotation and manufacturing tasks. While recent advances in image-based computer vision methods have demonstrated great potential in interpreting natural images through semantic segmentation approaches, the application of such methods in parsing engineering technical drawings into semantically accurate components remains a significant challenge. The severe pixel sparsity in engineering drawings also restricts the effective featurization of image-based data-driven methods. To overcome these challenges, we propose a deep learning based framework that predicts the semantic type of each vectorized component. Taking a raster image as input, we vectorize all components through thinning, stroke tracing, and cubic bezier fitting. Then a graph of such components is generated based on the connectivity between the components. Finally, a graph convolutional neural network is trained on this graph data to identify the semantic type of each component. We test our framework in the context of semantic segmentation of text, dimension and, contour components in engineering drawings. Results show that our method yields the best performance compared to recent image, and graph-based segmentation methods.
Multi-Resolution Graph Neural Network for Large-Scale Pointcloud Segmentation
Sep 18, 2020
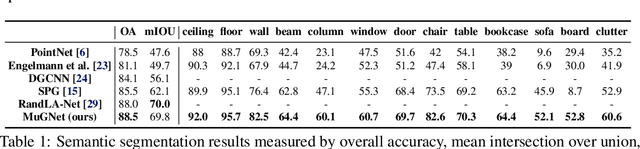
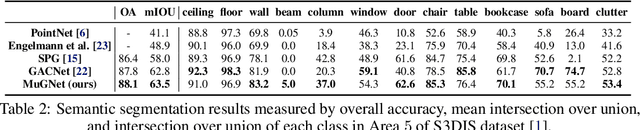
In this paper, we propose a multi-resolution deep-learning architecture to semantically segment dense large-scale pointclouds. Dense pointcloud data require a computationally expensive feature encoding process before semantic segmentation. Previous work has used different approaches to drastically downsample from the original pointcloud so common computing hardware can be utilized. While these approaches can relieve the computation burden to some extent, they are still limited in their processing capability for multiple scans. We present MuGNet, a memory-efficient, end-to-end graph neural network framework to perform semantic segmentation on large-scale pointclouds. We reduce the computation demand by utilizing a graph neural network on the preformed pointcloud graphs and retain the precision of the segmentation with a bidirectional network that fuses feature embedding at different resolutions. Our framework has been validated on benchmark datasets including Stanford Large-Scale 3D Indoor Spaces Dataset(S3DIS) and Virtual KITTI Dataset. We demonstrate that our framework can process up to 45 room scans at once on a single 11 GB GPU while still surpassing other graph-based solutions for segmentation on S3DIS with an 88.5\% (+3\%) overall accuracy and 69.8\% (+7.7\%) mIOU accuracy.
3D Shape Synthesis for Conceptual Design and Optimization Using Variational Autoencoders
Apr 16, 2019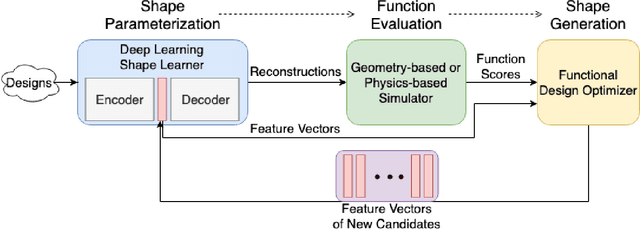

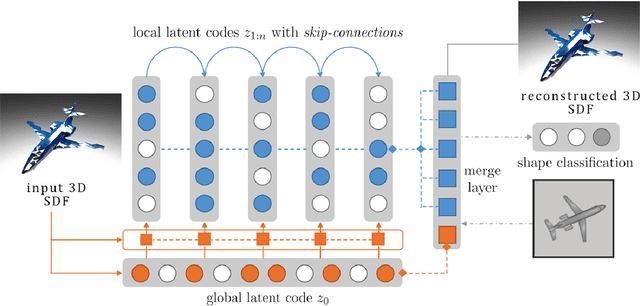
We propose a data-driven 3D shape design method that can learn a generative model from a corpus of existing designs, and use this model to produce a wide range of new designs. The approach learns an encoding of the samples in the training corpus using an unsupervised variational autoencoder-decoder architecture, without the need for an explicit parametric representation of the original designs. To facilitate the generation of smooth final surfaces, we develop a 3D shape representation based on a distance transformation of the original 3D data, rather than using the commonly utilized binary voxel representation. Once established, the generator maps the latent space representations to the high-dimensional distance transformation fields, which are then automatically surfaced to produce 3D representations amenable to physics simulations or other objective function evaluation modules. We demonstrate our approach for the computational design of gliders that are optimized to attain prescribed performance scores. Our results show that when combined with genetic optimization, the proposed approach can generate a rich set of candidate concept designs that achieve prescribed functional goals, even when the original dataset has only a few or no solutions that achieve these goals.