 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContact-Safe Reinforcement Learning with ProMP Reparameterization and Energy Awareness
Nov 17, 2025Reinforcement learning (RL) approaches based on Markov Decision Processes (MDPs) are predominantly applied in the robot joint space, often relying on limited task-specific information and partial awareness of the 3D environment. In contrast, episodic RL has demonstrated advantages over traditional MDP-based methods in terms of trajectory consistency, task awareness, and overall performance in complex robotic tasks. Moreover, traditional step-wise and episodic RL methods often neglect the contact-rich information inherent in task-space manipulation, especially considering the contact-safety and robustness. In this work, contact-rich manipulation tasks are tackled using a task-space, energy-safe framework, where reliable and safe task-space trajectories are generated through the combination of Proximal Policy Optimization (PPO) and movement primitives. Furthermore, an energy-aware Cartesian Impedance Controller objective is incorporated within the proposed framework to ensure safe interactions between the robot and the environment. Our experimental results demonstrate that the proposed framework outperforms existing methods in handling tasks on various types of surfaces in 3D environments, achieving high success rates as well as smooth trajectories and energy-safe interactions.
Learning a Shape-adaptive Assist-as-needed Rehabilitation Policy from Therapist-informed Input
Oct 06, 2025Therapist-in-the-loop robotic rehabilitation has shown great promise in enhancing rehabilitation outcomes by integrating the strengths of therapists and robotic systems. However, its broader adoption remains limited due to insufficient safe interaction and limited adaptation capability. This article proposes a novel telerobotics-mediated framework that enables therapists to intuitively and safely deliver assist-as-needed~(AAN) therapy based on two primary contributions. First, our framework encodes the therapist-informed corrective force into via-points in a latent space, allowing the therapist to provide only minimal assistance while encouraging patient maintaining own motion preferences. Second, a shape-adaptive ANN rehabilitation policy is learned to partially and progressively deform the reference trajectory for movement therapy based on encoded patient motion preferences and therapist-informed via-points. The effectiveness of the proposed shape-adaptive AAN strategy was validated on a telerobotic rehabilitation system using two representative tasks. The results demonstrate its practicality for remote AAN therapy and its superiority over two state-of-the-art methods in reducing corrective force and improving movement smoothness.
Safe-Construct: Redefining Construction Safety Violation Recognition as 3D Multi-View Engagement Task
Apr 15, 2025Recognizing safety violations in construction environments is critical yet remains underexplored in computer vision. Existing models predominantly rely on 2D object detection, which fails to capture the complexities of real-world violations due to: (i) an oversimplified task formulation treating violation recognition merely as object detection, (ii) inadequate validation under realistic conditions, (iii) absence of standardized baselines, and (iv) limited scalability from the unavailability of synthetic dataset generators for diverse construction scenarios. To address these challenges, we introduce Safe-Construct, the first framework that reformulates violation recognition as a 3D multi-view engagement task, leveraging scene-level worker-object context and 3D spatial understanding. We also propose the Synthetic Indoor Construction Site Generator (SICSG) to create diverse, scalable training data, overcoming data limitations. Safe-Construct achieves a 7.6% improvement over state-of-the-art methods across four violation types. We rigorously evaluate our approach in near-realistic settings, incorporating four violations, four workers, 14 objects, and challenging conditions like occlusions (worker-object, worker-worker) and variable illumination (back-lighting, overexposure, sunlight). By integrating 3D multi-view spatial understanding and synthetic data generation, Safe-Construct sets a new benchmark for scalable and robust safety monitoring in high-risk industries. Project Website: https://Safe-Construct.github.io/Safe-Construct
KunPeng: A Global Ocean Environmental Model
Apr 07, 2025Inspired by the similarity of the atmosphere-ocean physical coupling mechanism, this study innovatively migrates meteorological large-model techniques to the ocean domain, constructing the KunPeng global ocean environmental prediction model. Aimed at the discontinuous characteristics of marine space, we propose a terrain-adaptive mask constraint mechanism to mitigate effectively training divergence caused by abrupt gradients at land-sea boundaries. To fully integrate far-, medium-, and close-range marine features, a longitude-cyclic deformable convolution network (LC-DCN) is employed to enhance the dynamic receptive field, achieving refined modeling of multi-scale oceanic characteristics. A Deformable Convolution-enhanced Multi-Step Prediction module (DC-MTP) is employed to strengthen temporal dependency feature extraction capabilities. Experimental results demonstrate that this model achieves an average ACC of 0.80 in 15-day global predictions at 0.25$^\circ$ resolution, outperforming comparative models by 0.01-0.08. The average mean squared error (MSE) is 0.41 (representing a 5%-31% reduction) and the average mean absolute error (MAE) is 0.44 (0.6%-21% reduction) compared to other models. Significant improvements are particularly observed in sea surface parameter prediction, deep-sea region characterization, and current velocity field forecasting. Through a horizontal comparison of the applicability of operators at different scales in the marine domain, this study reveals that local operators significantly outperform global operators under slow-varying oceanic processes, demonstrating the effectiveness of dynamic feature pyramid representations in predicting marine physical parameters.
Enhancing Cooperation through Selective Interaction and Long-term Experiences in Multi-Agent Reinforcement Learning
May 04, 2024



The significance of network structures in promoting group cooperation within social dilemmas has been widely recognized. Prior studies attribute this facilitation to the assortment of strategies driven by spatial interactions. Although reinforcement learning has been employed to investigate the impact of dynamic interaction on the evolution of cooperation, there remains a lack of understanding about how agents develop neighbour selection behaviours and the formation of strategic assortment within an explicit interaction structure. To address this, our study introduces a computational framework based on multi-agent reinforcement learning in the spatial Prisoner's Dilemma game. This framework allows agents to select dilemma strategies and interacting neighbours based on their long-term experiences, differing from existing research that relies on preset social norms or external incentives. By modelling each agent using two distinct Q-networks, we disentangle the coevolutionary dynamics between cooperation and interaction. The results indicate that long-term experience enables agents to develop the ability to identify non-cooperative neighbours and exhibit a preference for interaction with cooperative ones. This emergent self-organizing behaviour leads to the clustering of agents with similar strategies, thereby increasing network reciprocity and enhancing group cooperation.
Accelerating Integrated Task and Motion Planning with Neural Feasibility Checking
Mar 20, 2022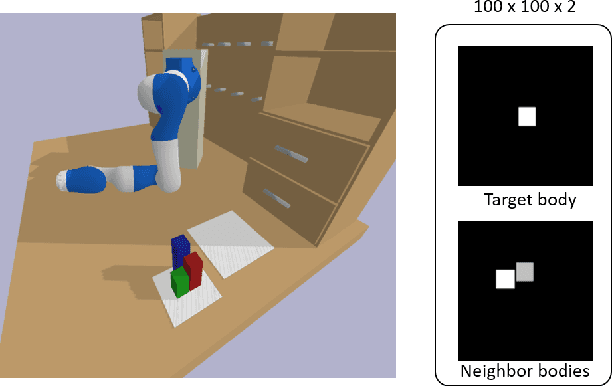
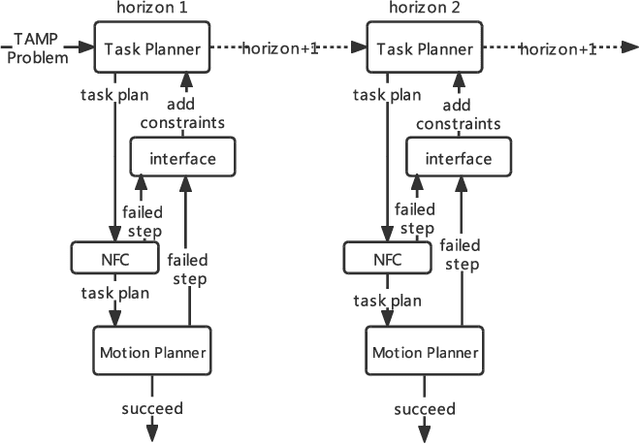

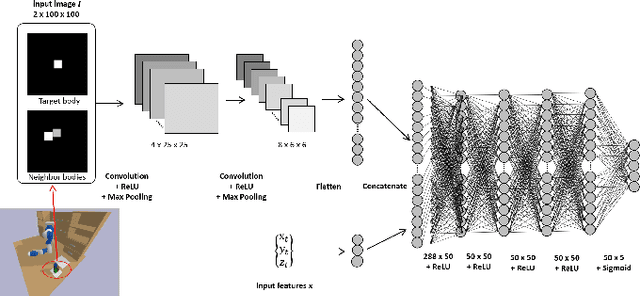
As robots play an increasingly important role in the industrial, the expectations about their applications for everyday living tasks are getting higher. Robots need to perform long-horizon tasks that consist of several sub-tasks that need to be accomplished. Task and Motion Planning (TAMP) provides a hierarchical framework to handle the sequential nature of manipulation tasks by interleaving a symbolic task planner that generates a possible action sequence, with a motion planner that checks the kinematic feasibility in the geometric world, generating robot trajectories if several constraints are satisfied, e.g., a collision-free trajectory from one state to another. Hence, the reasoning about the task plan's geometric grounding is taken over by the motion planner. However, motion planning is computationally intense and is usability as feasibility checker casts TAMP methods inapplicable to real-world scenarios. In this paper, we introduce neural feasibility classifier (NFC), a simple yet effective visual heuristic for classifying the feasibility of proposed actions in TAMP. Namely, NFC will identify infeasible actions of the task planner without the need for costly motion planning, hence reducing planning time in multi-step manipulation tasks. NFC encodes the image of the robot's workspace into a feature map thanks to convolutional neural network (CNN). We train NFC using simulated data from TAMP problems and label the instances based on IK feasibility checking. Our empirical results in different simulated manipulation tasks show that our NFC generalizes to the entire robot workspace and has high prediction accuracy even in scenes with multiple obstructions. When combined with state-of-the-art integrated TAMP, our NFC enhances its performance while reducing its planning time.
Learning Geometric Constraints in Task and Motion Planning
Jan 24, 2022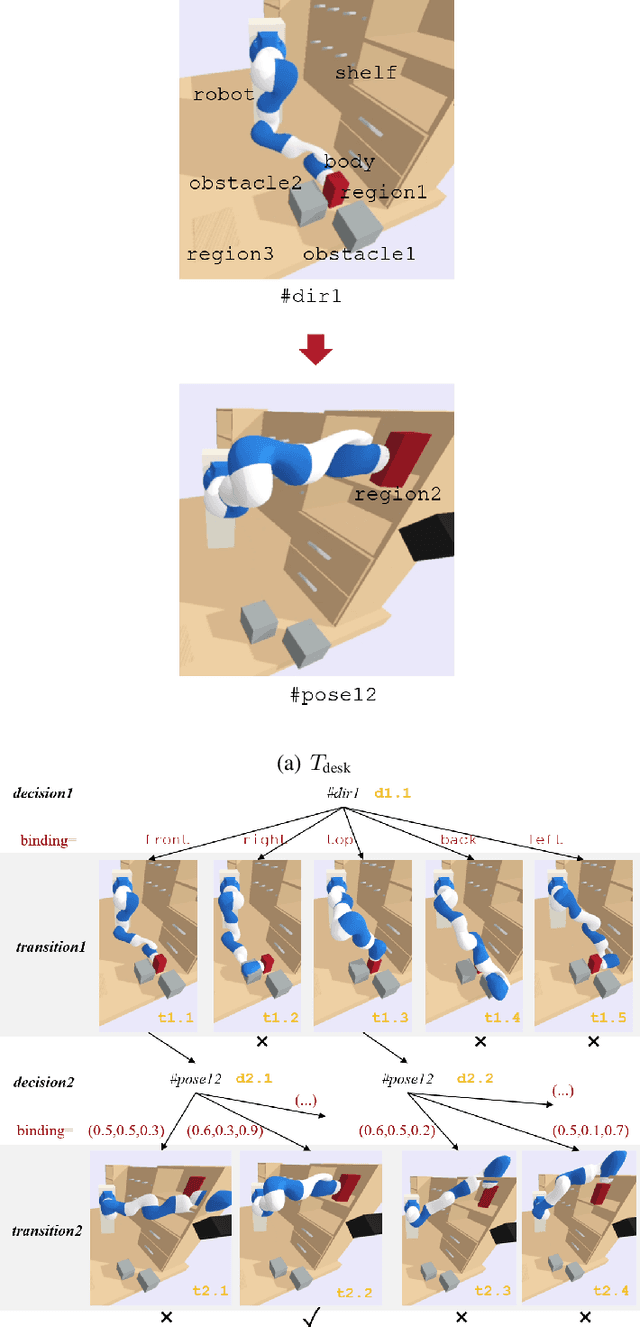
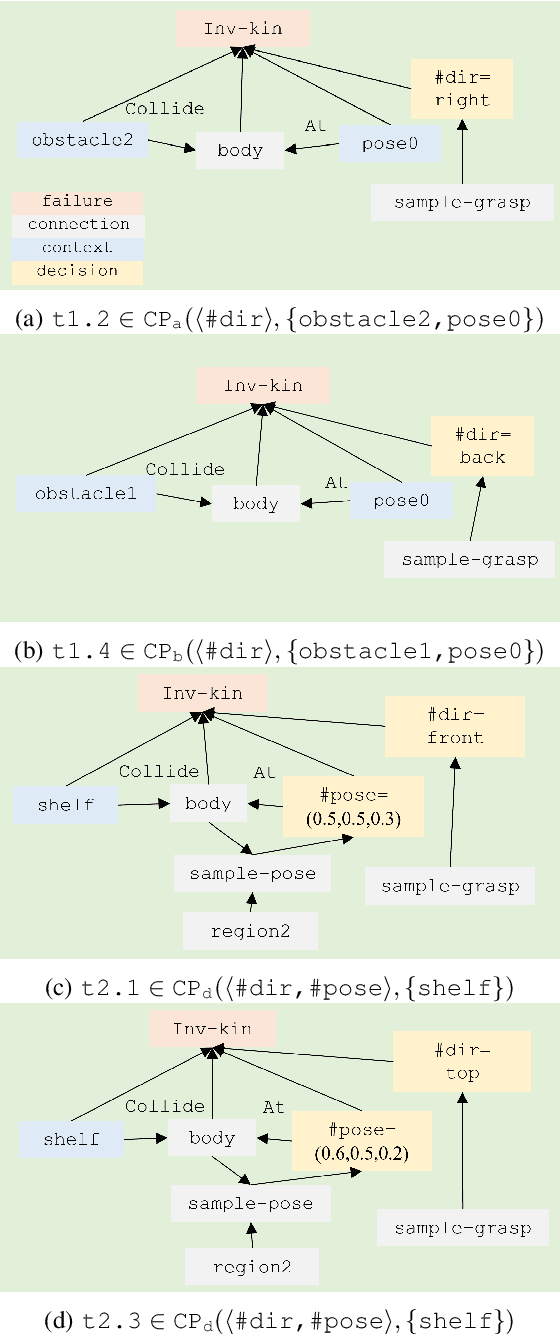
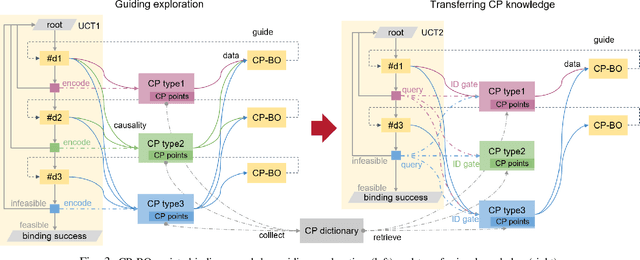
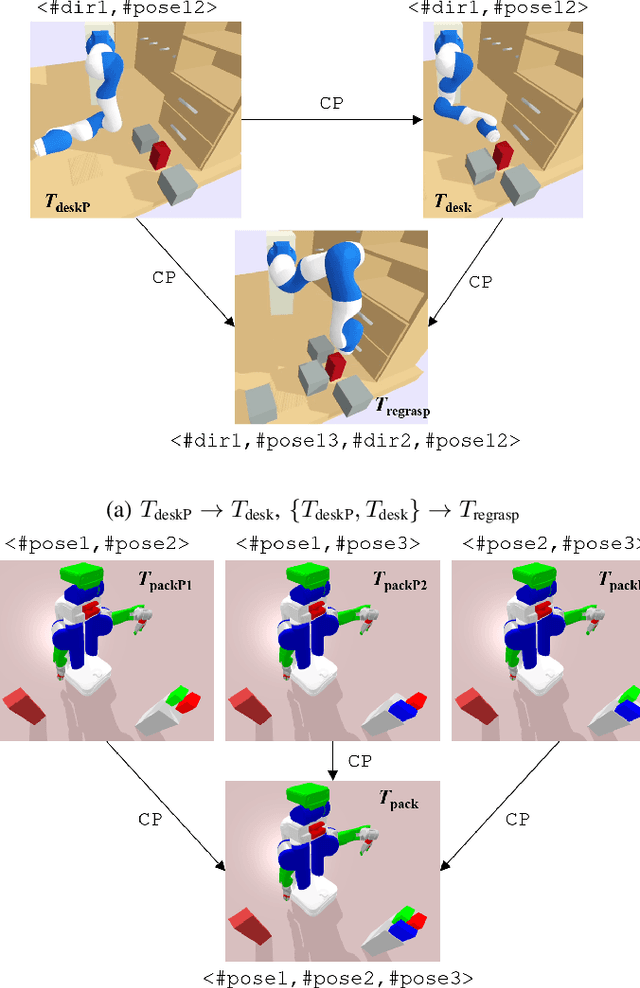
Searching for bindings of geometric parameters in task and motion planning (TAMP) is a finite-horizon stochastic planning problem with high-dimensional decision spaces. A robot manipulator can only move in a subspace of its whole range that is subjected to many geometric constraints. A TAMP solver usually takes many explorations before finding a feasible binding set for each task. It is favorable to learn those constraints once and then transfer them over different tasks within the same workspace. We address this problem by representing constraint knowledge with transferable primitives and using Bayesian optimization (BO) based on these primitives to guide binding search in further tasks. Via semantic and geometric backtracking in TAMP, we construct constraint primitives to encode the geometric constraints respectively in a reusable form. Then we devise a BO approach to efficiently utilize the accumulated constraints for guiding node expansion of an MCTS-based binding planner. We further compose a transfer mechanism to enable free knowledge flow between TAMP tasks. Results indicate that our approach reduces the expensive exploration calls in binding search by 43.60to 71.69 when compared to the baseline unguided planner.
Extended Task and Motion Planning of Long-horizon Robot Manipulation
Mar 09, 2021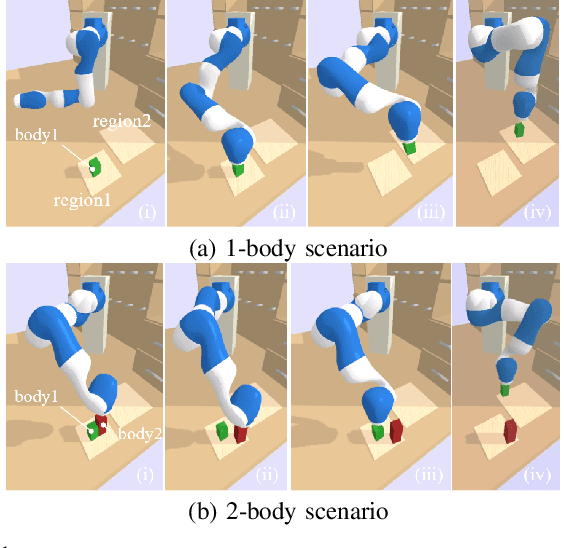
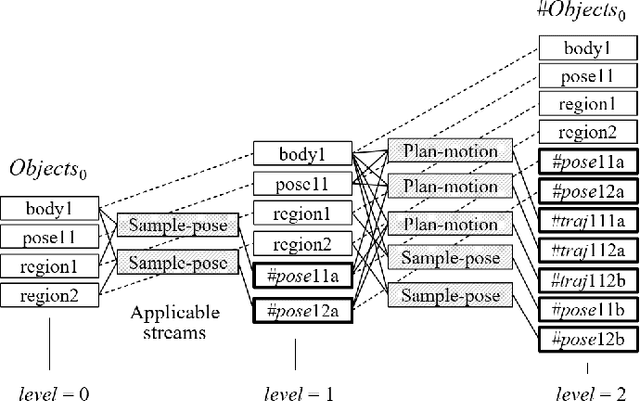
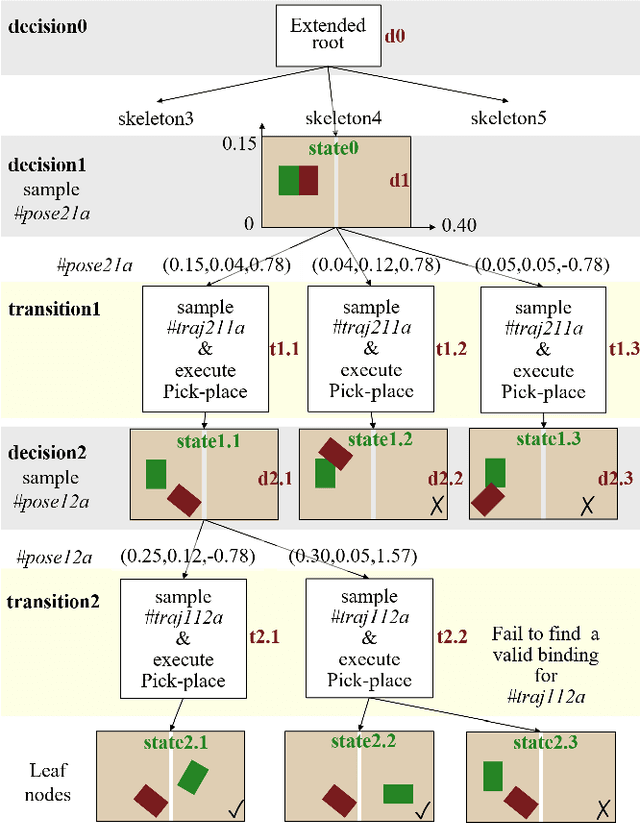
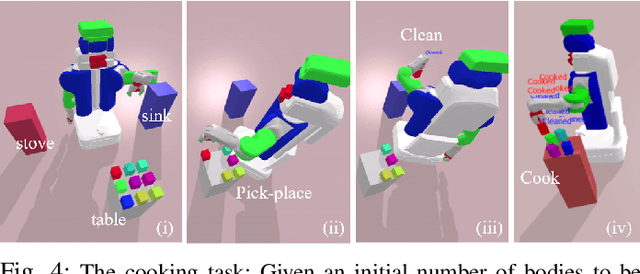
Task and Motion Planning (TAMP) requires the integration of symbolic reasoning with metric motion planning that accounts for the robot's actions' geometric feasibility. This hierarchical structure inevitably prevents the symbolic planners from accessing the environment's low-level geometric description, vital to the problem's solution. Most TAMP approaches fail to provide feasible solutions when there is missing knowledge about the environment at the symbolic level. The incapability of devising alternative high-level plans leads existing planners to a dead end. We propose a novel approach for decision-making on extended decision spaces over plan skeletons and action parameters. We integrate top-k planning for constructing an explicit skeleton space, where a skeleton planner generates a variety of candidate skeleton plans. Moreover, we effectively combine this skeleton space with the resultant motion parameter spaces into a single extended decision space. Accordingly, we use Monte-Carlo Tree Search (MCTS) to ensure an exploration-exploitation balance at each decision node and optimize globally to produce minimum-cost solutions. The proposed seamless combination of symbolic top-k planning with streams, with the proved optimality of MCTS, leads to a powerful planning algorithm that can handle the combinatorial complexity of long-horizon manipulation tasks. We empirically evaluate our proposed algorithm in challenging manipulation tasks with different domains that require multi-stage decisions and show how our method can overcome dead-ends through its effective alternate plans compared to its most competitive baseline method.
Structured Policy Representation: Imposing Stability in arbitrarily conditioned dynamic systems
Dec 11, 2020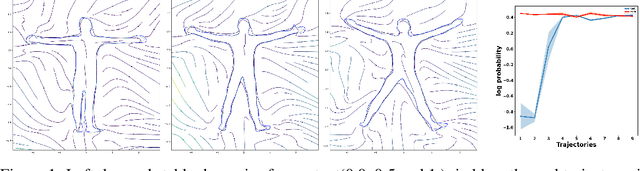
We present a new family of deep neural network-based dynamic systems. The presented dynamics are globally stable and can be conditioned with an arbitrary context state. We show how these dynamics can be used as structured robot policies. Global stability is one of the most important and straightforward inductive biases as it allows us to impose reasonable behaviors outside the region of the demonstrations.
Fast Skill Learning for Variable Compliance Robotic Assembly
May 11, 2019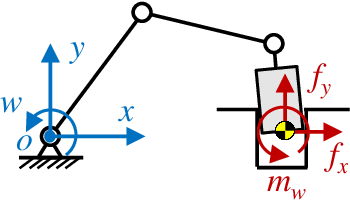
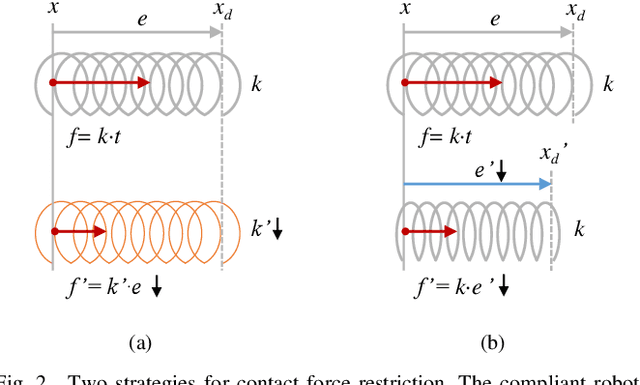
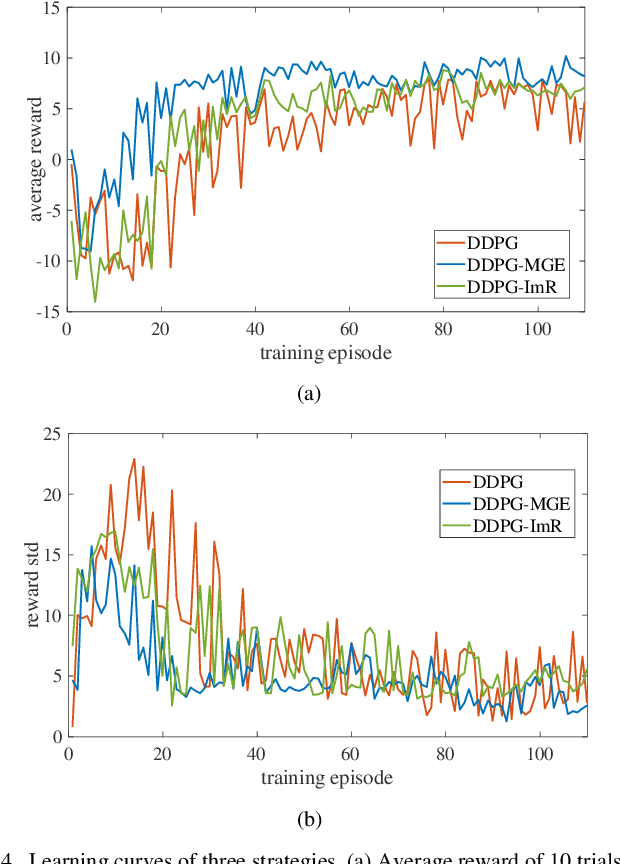
The robotic assembly represents a group of benchmark problems for reinforcement learning and variable compliance control that features sophisticated contact manipulation. One of the key challenges in applying reinforcement learning to physical robot is the sample complexity, the requirement of large amounts of experience for learning. We mitigate this sample complexity problem by incorporating an iteratively refitted model into the learning process through model-guided exploration. Yet, fitting a local model of the physical environment is of major difficulties. In this work, a Kalman filter is used to combine the adaptive linear dynamics with a coarse prior model from analytical description, and proves to give more accurate predictions than the existing method. Experimental results show that the proposed model fitting strategy can be incorporated into a model predictive controller to generate good exploration behaviors for learning acceleration, while preserving the benefits of model-free reinforcement learning for uncertain environments. In addition to the sample complexity, the inevitable robot overloaded during operation also tends to limit the learning efficiency. To address this problem, we present a method to restrict the largest possible potential energy in the compliance control system and therefore keep the contact force within the legitimate range.