 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKunPeng: A Global Ocean Environmental Model
Apr 07, 2025Inspired by the similarity of the atmosphere-ocean physical coupling mechanism, this study innovatively migrates meteorological large-model techniques to the ocean domain, constructing the KunPeng global ocean environmental prediction model. Aimed at the discontinuous characteristics of marine space, we propose a terrain-adaptive mask constraint mechanism to mitigate effectively training divergence caused by abrupt gradients at land-sea boundaries. To fully integrate far-, medium-, and close-range marine features, a longitude-cyclic deformable convolution network (LC-DCN) is employed to enhance the dynamic receptive field, achieving refined modeling of multi-scale oceanic characteristics. A Deformable Convolution-enhanced Multi-Step Prediction module (DC-MTP) is employed to strengthen temporal dependency feature extraction capabilities. Experimental results demonstrate that this model achieves an average ACC of 0.80 in 15-day global predictions at 0.25$^\circ$ resolution, outperforming comparative models by 0.01-0.08. The average mean squared error (MSE) is 0.41 (representing a 5%-31% reduction) and the average mean absolute error (MAE) is 0.44 (0.6%-21% reduction) compared to other models. Significant improvements are particularly observed in sea surface parameter prediction, deep-sea region characterization, and current velocity field forecasting. Through a horizontal comparison of the applicability of operators at different scales in the marine domain, this study reveals that local operators significantly outperform global operators under slow-varying oceanic processes, demonstrating the effectiveness of dynamic feature pyramid representations in predicting marine physical parameters.
Semantic SLAM with Rolling-Shutter Cameras and Low-Precision INS in Outdoor Environments
Apr 01, 2025Accurate localization and mapping in outdoor environments remains challenging when using consumer-grade hardware, particularly with rolling-shutter cameras and low-precision inertial navigation systems (INS). We present a novel semantic SLAM approach that leverages road elements such as lane boundaries, traffic signs, and road markings to enhance localization accuracy. Our system integrates real-time semantic feature detection with a graph optimization framework, effectively handling both rolling-shutter effects and INS drift. Using a practical hardware setup which consists of a rolling-shutter camera (3840*2160@30fps), IMU (100Hz), and wheel encoder (50Hz), we demonstrate significant improvements over existing methods. Compared to state-of-the-art approaches, our method achieves higher recall (up to 5.35\%) and precision (up to 2.79\%) in semantic element detection, while maintaining mean relative error (MRE) within 10cm and mean absolute error (MAE) around 1m. Extensive experiments in diverse urban environments demonstrate the robust performance of our system under varying lighting conditions and complex traffic scenarios, making it particularly suitable for autonomous driving applications. The proposed approach provides a practical solution for high-precision localization using affordable hardware, bridging the gap between consumer-grade sensors and production-level performance requirements.
A Concise Survey on Lane Topology Reasoning for HD Mapping
Mar 31, 2025



Lane topology reasoning techniques play a crucial role in high-definition (HD) mapping and autonomous driving applications. While recent years have witnessed significant advances in this field, there has been limited effort to consolidate these works into a comprehensive overview. This survey systematically reviews the evolution and current state of lane topology reasoning methods, categorizing them into three major paradigms: procedural modeling-based methods, aerial imagery-based methods, and onboard sensors-based methods. We analyze the progression from early rule-based approaches to modern learning-based solutions utilizing transformers, graph neural networks (GNNs), and other deep learning architectures. The paper examines standardized evaluation metrics, including road-level measures (APLS and TLTS score), and lane-level metrics (DET and TOP score), along with performance comparisons on benchmark datasets such as OpenLane-V2. We identify key technical challenges, including dataset availability and model efficiency, and outline promising directions for future research. This comprehensive review provides researchers and practitioners with insights into the theoretical frameworks, practical implementations, and emerging trends in lane topology reasoning for HD mapping applications.
Video-based Traffic Light Recognition by Rockchip RV1126 for Autonomous Driving
Mar 31, 2025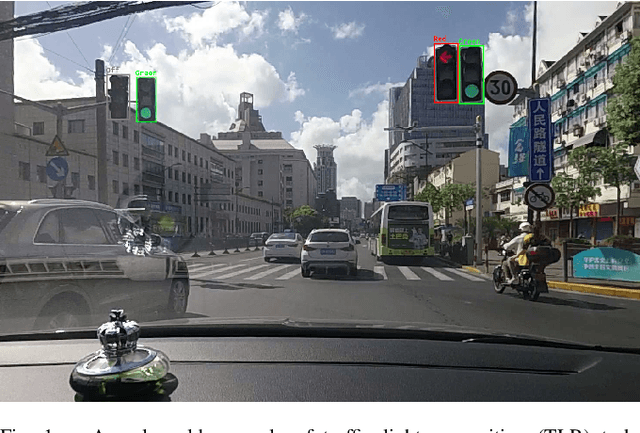
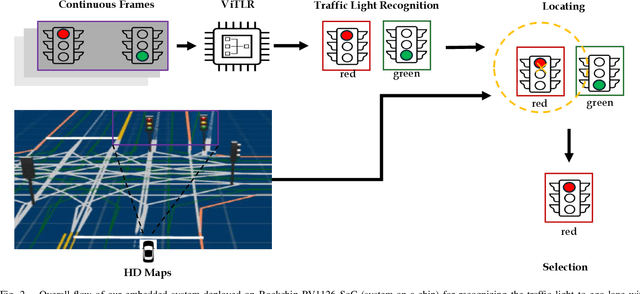
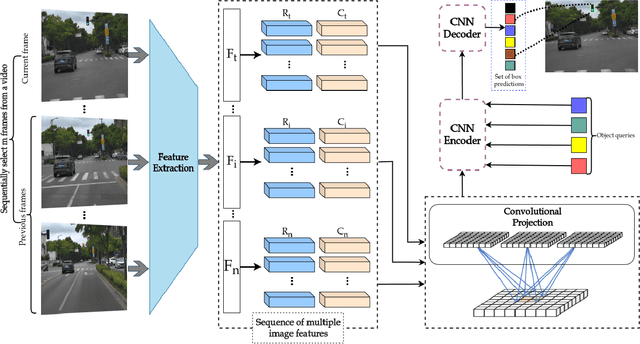
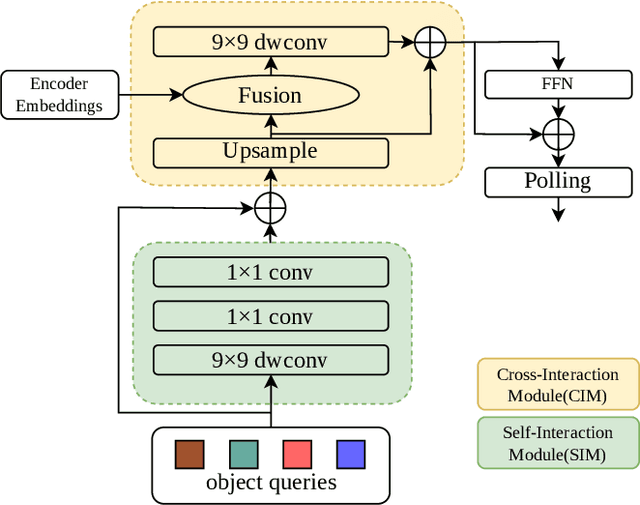
Real-time traffic light recognition is fundamental for autonomous driving safety and navigation in urban environments. While existing approaches rely on single-frame analysis from onboard cameras, they struggle with complex scenarios involving occlusions and adverse lighting conditions. We present \textit{ViTLR}, a novel video-based end-to-end neural network that processes multiple consecutive frames to achieve robust traffic light detection and state classification. The architecture leverages a transformer-like design with convolutional self-attention modules, which is optimized specifically for deployment on the Rockchip RV1126 embedded platform. Extensive evaluations on two real-world datasets demonstrate that \textit{ViTLR} achieves state-of-the-art performance while maintaining real-time processing capabilities (>25 FPS) on RV1126's NPU. The system shows superior robustness across temporal stability, varying target distances, and challenging environmental conditions compared to existing single-frame approaches. We have successfully integrated \textit{ViTLR} into an ego-lane traffic light recognition system using HD maps for autonomous driving applications. The complete implementation, including source code and datasets, is made publicly available to facilitate further research in this domain.
A Benchmark for Vision-Centric HD Mapping by V2I Systems
Mar 31, 2025



Autonomous driving faces safety challenges due to a lack of global perspective and the semantic information of vectorized high-definition (HD) maps. Information from roadside cameras can greatly expand the map perception range through vehicle-to-infrastructure (V2I) communications. However, there is still no dataset from the real world available for the study on map vectorization onboard under the scenario of vehicle-infrastructure cooperation. To prosper the research on online HD mapping for Vehicle-Infrastructure Cooperative Autonomous Driving (VICAD), we release a real-world dataset, which contains collaborative camera frames from both vehicles and roadside infrastructures, and provides human annotations of HD map elements. We also present an end-to-end neural framework (i.e., V2I-HD) leveraging vision-centric V2I systems to construct vectorized maps. To reduce computation costs and further deploy V2I-HD on autonomous vehicles, we introduce a directionally decoupled self-attention mechanism to V2I-HD. Extensive experiments show that V2I-HD has superior performance in real-time inference speed, as tested by our real-world dataset. Abundant qualitative results also demonstrate stable and robust map construction quality with low cost in complex and various driving scenes. As a benchmark, both source codes and the dataset have been released at OneDrive for the purpose of further study.