 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloneMem: Benchmarking Long-Term Memory for AI Clones
Jan 11, 2026AI Clones aim to simulate an individual's thoughts and behaviors to enable long-term, personalized interaction, placing stringent demands on memory systems to model experiences, emotions, and opinions over time. Existing memory benchmarks primarily rely on user-agent conversational histories, which are temporally fragmented and insufficient for capturing continuous life trajectories. We introduce CloneMem, a benchmark for evaluating longterm memory in AI Clone scenarios grounded in non-conversational digital traces, including diaries, social media posts, and emails, spanning one to three years. CloneMem adopts a hierarchical data construction framework to ensure longitudinal coherence and defines tasks that assess an agent's ability to track evolving personal states. Experiments show that current memory mechanisms struggle in this setting, highlighting open challenges for life-grounded personalized AI. Code and dataset are available at https://github.com/AvatarMemory/CloneMemBench
RealMem: Benchmarking LLMs in Real-World Memory-Driven Interaction
Jan 11, 2026As Large Language Models (LLMs) evolve from static dialogue interfaces to autonomous general agents, effective memory is paramount to ensuring long-term consistency. However, existing benchmarks primarily focus on casual conversation or task-oriented dialogue, failing to capture **"long-term project-oriented"** interactions where agents must track evolving goals. To bridge this gap, we introduce **RealMem**, the first benchmark grounded in realistic project scenarios. RealMem comprises over 2,000 cross-session dialogues across eleven scenarios, utilizing natural user queries for evaluation. We propose a synthesis pipeline that integrates Project Foundation Construction, Multi-Agent Dialogue Generation, and Memory and Schedule Management to simulate the dynamic evolution of memory. Experiments reveal that current memory systems face significant challenges in managing the long-term project states and dynamic context dependencies inherent in real-world projects. Our code and datasets are available at [https://github.com/AvatarMemory/RealMemBench](https://github.com/AvatarMemory/RealMemBench).
Does Memory Need Graphs? A Unified Framework and Empirical Analysis for Long-Term Dialog Memory
Jan 07, 2026Graph structures are increasingly used in dialog memory systems, but empirical findings on their effectiveness remain inconsistent, making it unclear which design choices truly matter. We present an experimental, system-oriented analysis of long-term dialog memory architectures. We introduce a unified framework that decomposes dialog memory systems into core components and supports both graph-based and non-graph approaches. Under this framework, we conduct controlled, stage-wise experiments on LongMemEval and HaluMem, comparing common design choices in memory representation, organization, maintenance, and retrieval. Our results show that many performance differences are driven by foundational system settings rather than specific architectural innovations. Based on these findings, we identify stable and reliable strong baselines for future dialog memory research.
Pastiche Novel Generation Creating: Fan Fiction You Love in Your Favorite Author's Style
Feb 21, 2025Great novels create immersive worlds with rich character arcs, well-structured plots, and nuanced writing styles. However, current novel generation methods often rely on brief, simplistic story outlines and generate details using plain, generic language. To bridge this gap, we introduce the task of Pastiche Novel Generation, which requires the generated novels to imitate the distinctive features of the original work, including understanding character profiles, predicting plausible plot developments, and writing concrete details using vivid, expressive language. To achieve this, we propose WriterAgent, a novel generation system designed to master the core aspects of literary pastiche. WriterAgent is trained through a curriculum learning paradigm, progressing from low-level stylistic mastery to high-level narrative coherence. Its key tasks include language style learning, character modeling, plot planning, and stylish writing, ensuring comprehensive narrative control. To support this, WriterAgent leverages the WriterLoRA framework, an extension of LoRA with hierarchical and cumulative task-specific modules, each specializing in a different narrative aspect. We evaluate WriterAgent on multilingual classics like Harry Potter and Dream of the Red Chamber, demonstrating its superiority over baselines in capturing the target author's settings, character dynamics, and writing style to produce coherent, faithful narratives.
A Model-Agnostic Causal Learning Framework for Recommendation using Search Data
Feb 10, 2022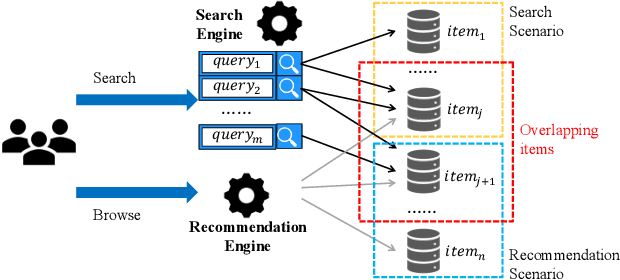
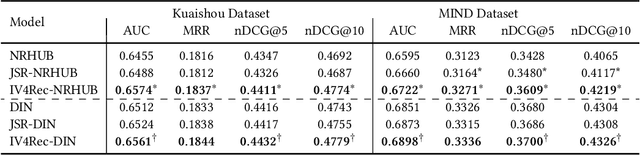
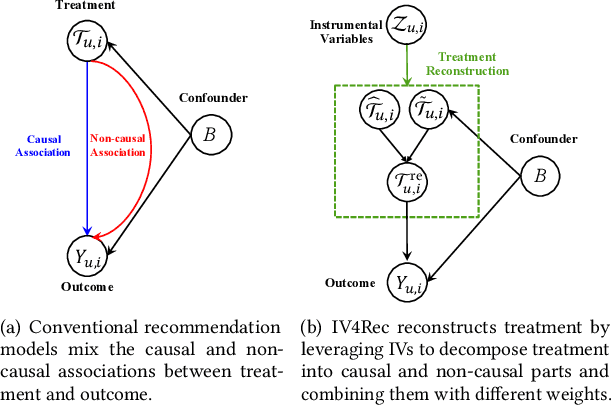

Machine-learning based recommender systems(RSs) has become an effective means to help people automatically discover their interests. Existing models often represent the rich information for recommendation, such as items, users, and contexts, as embedding vectors and leverage them to predict users' feedback. In the view of causal analysis, the associations between these embedding vectors and users' feedback are a mixture of the causal part that describes why an item is preferred by a user, and the non-causal part that merely reflects the statistical dependencies between users and items, for example, the exposure mechanism, public opinions, display position, etc. However, existing RSs mostly ignored the striking differences between the causal parts and non-causal parts when using these embedding vectors. In this paper, we propose a model-agnostic framework named IV4Rec that can effectively decompose the embedding vectors into these two parts, hence enhancing recommendation results. Specifically, we jointly consider users' behaviors in search scenarios and recommendation scenarios. Adopting the concepts in causal analysis, we embed users' search behaviors as instrumental variables (IVs), to help decompose original embedding vectors in recommendation, i.e., treatments. IV4Rec then combines the two parts through deep neural networks and uses the combined results for recommendation. IV4Rec is model-agnostic and can be applied to a number of existing RSs such as DIN and NRHUB. Experimental results on both public and proprietary industrial datasets demonstrate that IV4Rec consistently enhances RSs and outperforms a framework that jointly considers search and recommendation.