 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFisheye3R: Adapting Unified 3D Feed-Forward Foundation Models to Fisheye Lenses
Mar 30, 2026Feed-forward foundation models for multi-view 3-dimensional (3D) reconstruction have been trained on large-scale datasets of perspective images; when tested on wide field-of-view images, e.g., from a fisheye camera, their performance degrades. Their error arises from changes in spatial positions of pixels due to a non-linear projection model that maps 3D points onto the 2D image plane. While one may surmise that training on fisheye images would resolve this problem, there are far fewer fisheye images with ground truth than perspective images, which limit generalization. To enable inference on imagery exhibiting high radial distortion, we propose Fisheye3R, a novel adaptation framework that extends these multi-view 3D reconstruction foundation models to natively accommodate fisheye inputs without performance regression on perspective images. To address the scarcity of fisheye images and ground truth, we introduce flexible learning schemes that support self-supervised adaptation using only unlabeled perspective images and supervised adaptation without any fisheye training data. Extensive experiments across three foundation models, including VGGT, $π^3$, and MapAnything, demonstrate that our approach consistently improves camera pose, depth, point map, and field-of-view estimation on fisheye images.
Through the Curved Cover: Synthesizing Cover Aberrated Scenes with Refractive Field
Nov 10, 2024
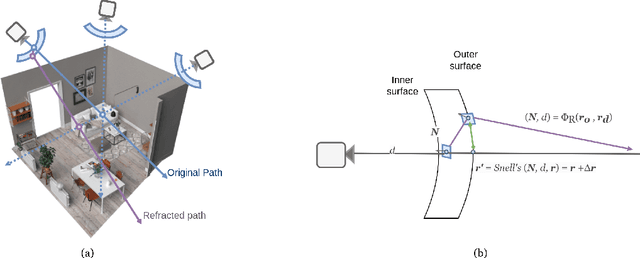


Recent extended reality headsets and field robots have adopted covers to protect the front-facing cameras from environmental hazards and falls. The surface irregularities on the cover can lead to optical aberrations like blurring and non-parametric distortions. Novel view synthesis methods like NeRF and 3D Gaussian Splatting are ill-equipped to synthesize from sequences with optical aberrations. To address this challenge, we introduce SynthCover to enable novel view synthesis through protective covers for downstream extended reality applications. SynthCover employs a Refractive Field that estimates the cover's geometry, enabling precise analytical calculation of refracted rays. Experiments on synthetic and real-world scenes demonstrate our method's ability to accurately model scenes viewed through protective covers, achieving a significant improvement in rendering quality compared to prior methods. We also show that the model can adjust well to various cover geometries with synthetic sequences captured with covers of different surface curvatures. To motivate further studies on this problem, we provide the benchmarked dataset containing real and synthetic walkable scenes captured with protective cover optical aberrations.
FMGS: Foundation Model Embedded 3D Gaussian Splatting for Holistic 3D Scene Understanding
Jan 03, 2024



Precisely perceiving the geometric and semantic properties of real-world 3D objects is crucial for the continued evolution of augmented reality and robotic applications. To this end, we present \algfull{} (\algname{}), which incorporates vision-language embeddings of foundation models into 3D Gaussian Splatting (GS). The key contribution of this work is an efficient method to reconstruct and represent 3D vision-language models. This is achieved by distilling feature maps generated from image-based foundation models into those rendered from our 3D model. To ensure high-quality rendering and fast training, we introduce a novel scene representation by integrating strengths from both GS and multi-resolution hash encodings (MHE). Our effective training procedure also introduces a pixel alignment loss that makes the rendered feature distance of same semantic entities close, following the pixel-level semantic boundaries. Our results demonstrate remarkable multi-view semantic consistency, facilitating diverse downstream tasks, beating state-of-the-art methods by $\mathbf{10.2}$ percent on open-vocabulary language-based object detection, despite that we are $\mathbf{851\times}$ faster for inference. This research explores the intersection of vision, language, and 3D scene representation, paving the way for enhanced scene understanding in uncontrolled real-world environments. We plan to release the code upon paper acceptance.
Learned Monocular Depth Priors in Visual-Inertial Initialization
Apr 20, 2022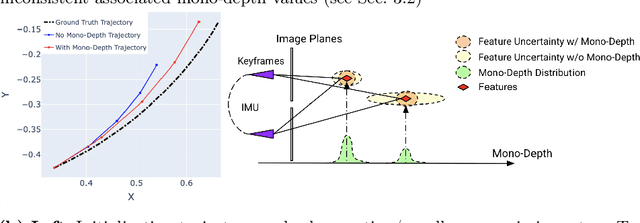
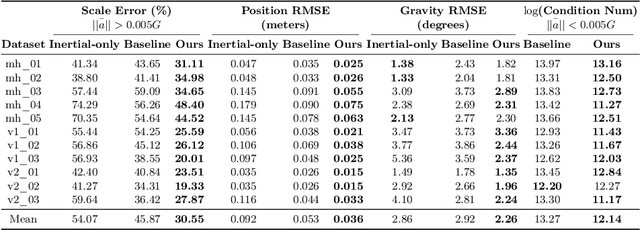
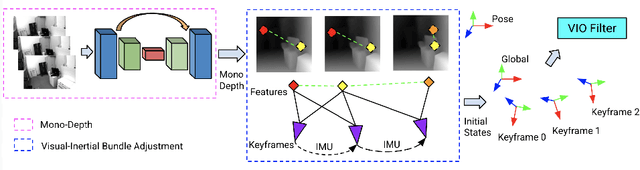
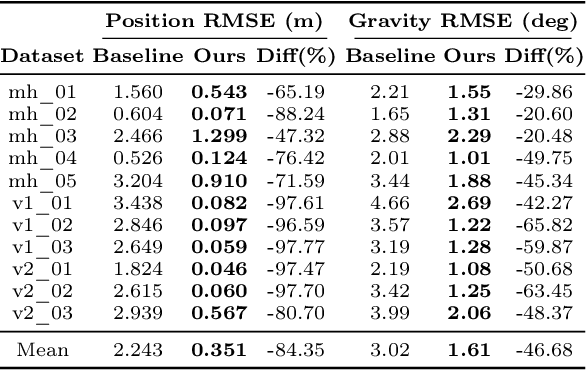
Visual-inertial odometry (VIO) is the pose estimation backbone for most AR/VR and autonomous robotic systems today, in both academia and industry. However, these systems are highly sensitive to the initialization of key parameters such as sensor biases, gravity direction, and metric scale. In practical scenarios where high-parallax or variable acceleration assumptions are rarely met (e.g. hovering aerial robot, smartphone AR user not gesticulating with phone), classical visual-inertial initialization formulations often become ill-conditioned and/or fail to meaningfully converge. In this paper we target visual-inertial initialization specifically for these low-excitation scenarios critical to in-the-wild usage. We propose to circumvent the limitations of classical visual-inertial structure-from-motion (SfM) initialization by incorporating a new learning-based measurement as a higher-level input. We leverage learned monocular depth images (mono-depth) to constrain the relative depth of features, and upgrade the mono-depth to metric scale by jointly optimizing for its scale and shift. Our experiments show a significant improvement in problem conditioning compared to a classical formulation for visual-inertial initialization, and demonstrate significant accuracy and robustness improvements relative to the state-of-the-art on public benchmarks, particularly under motion-restricted scenarios. We further extend this improvement to implementation within an existing odometry system to illustrate the impact of our improved initialization method on resulting tracking trajectories.
Semantic Mapping with Simultaneous Object Detection and Localization
Oct 26, 2018
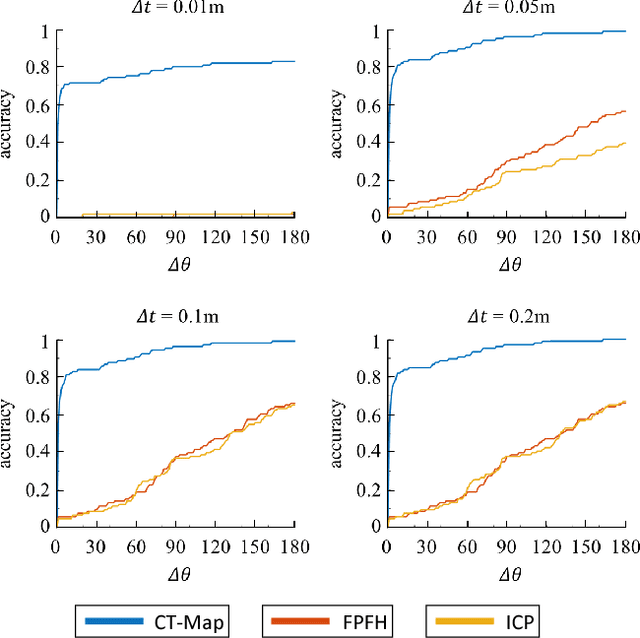


We present a filtering-based method for semantic mapping to simultaneously detect objects and localize their 6 degree-of-freedom pose. For our method, called Contextual Temporal Mapping (or CT-Map), we represent the semantic map as a belief over object classes and poses across an observed scene. Inference for the semantic mapping problem is then modeled in the form of a Conditional Random Field (CRF). CT-Map is a CRF that considers two forms of relationship potentials to account for contextual relations between objects and temporal consistency of object poses, as well as a measurement potential on observations. A particle filtering algorithm is then proposed to perform inference in the CT-Map model. We demonstrate the efficacy of the CT-Map method with a Michigan Progress Fetch robot equipped with a RGB-D sensor. Our results demonstrate that the particle filtering based inference of CT-Map provides improved object detection and pose estimation with respect to baseline methods that treat observations as independent samples of a scene.