 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMGS: Foundation Model Embedded 3D Gaussian Splatting for Holistic 3D Scene Understanding
Jan 03, 2024



Precisely perceiving the geometric and semantic properties of real-world 3D objects is crucial for the continued evolution of augmented reality and robotic applications. To this end, we present \algfull{} (\algname{}), which incorporates vision-language embeddings of foundation models into 3D Gaussian Splatting (GS). The key contribution of this work is an efficient method to reconstruct and represent 3D vision-language models. This is achieved by distilling feature maps generated from image-based foundation models into those rendered from our 3D model. To ensure high-quality rendering and fast training, we introduce a novel scene representation by integrating strengths from both GS and multi-resolution hash encodings (MHE). Our effective training procedure also introduces a pixel alignment loss that makes the rendered feature distance of same semantic entities close, following the pixel-level semantic boundaries. Our results demonstrate remarkable multi-view semantic consistency, facilitating diverse downstream tasks, beating state-of-the-art methods by $\mathbf{10.2}$ percent on open-vocabulary language-based object detection, despite that we are $\mathbf{851\times}$ faster for inference. This research explores the intersection of vision, language, and 3D scene representation, paving the way for enhanced scene understanding in uncontrolled real-world environments. We plan to release the code upon paper acceptance.
Invert and Defend: Model-based Approximate Inversion of Generative Adversarial Networks for Secure Inference
Nov 23, 2019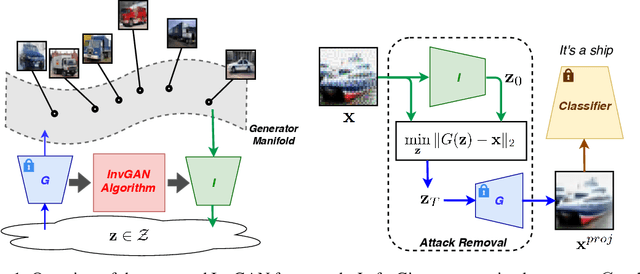
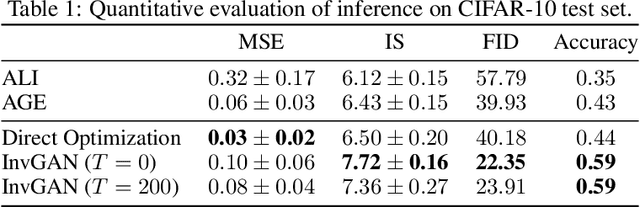
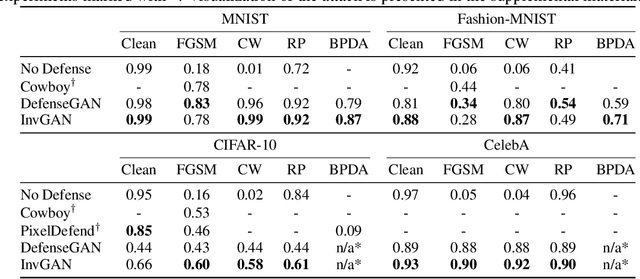
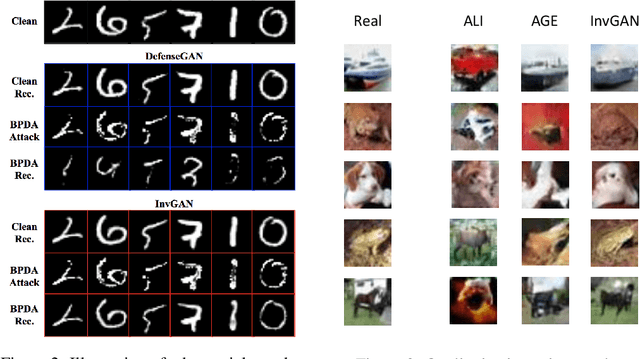
Inferring the latent variable generating a given test sample is a challenging problem in Generative Adversarial Networks (GANs). In this paper, we propose InvGAN - a novel framework for solving the inference problem in GANs, which involves training an encoder network capable of inverting a pre-trained generator network without access to any training data. Under mild assumptions, we theoretically show that using InvGAN, we can approximately invert the generations of any latent code of a trained GAN model. Furthermore, we empirically demonstrate the superiority of our inference scheme by quantitative and qualitative comparisons with other methods that perform a similar task. We also show the effectiveness of our framework in the problem of adversarial defenses where InvGAN can successfully be used as a projection-based defense mechanism. Additionally, we show how InvGAN can be used to implement reparameterization white-box attacks on projection-based defense mechanisms. Experimental validation on several benchmark datasets demonstrate the efficacy of our method in achieving improved performance on several white-box and black-box attacks. Our code is available at https://github.com/yogeshbalaji/InvGAN.
Defense-GAN: Protecting Classifiers Against Adversarial Attacks Using Generative Models
May 18, 2018
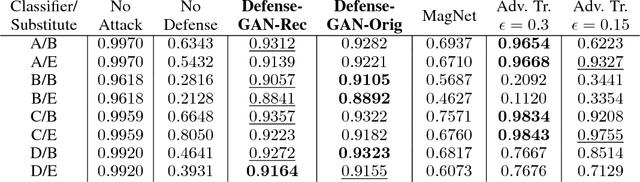
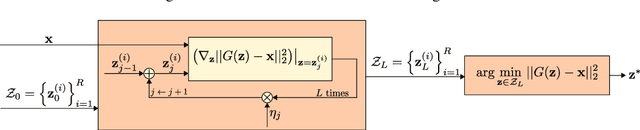
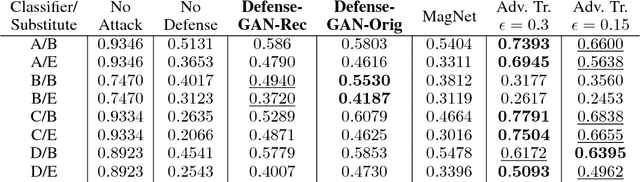
In recent years, deep neural network approaches have been widely adopted for machine learning tasks, including classification. However, they were shown to be vulnerable to adversarial perturbations: carefully crafted small perturbations can cause misclassification of legitimate images. We propose Defense-GAN, a new framework leveraging the expressive capability of generative models to defend deep neural networks against such attacks. Defense-GAN is trained to model the distribution of unperturbed images. At inference time, it finds a close output to a given image which does not contain the adversarial changes. This output is then fed to the classifier. Our proposed method can be used with any classification model and does not modify the classifier structure or training procedure. It can also be used as a defense against any attack as it does not assume knowledge of the process for generating the adversarial examples. We empirically show that Defense-GAN is consistently effective against different attack methods and improves on existing defense strategies. Our code has been made publicly available at https://github.com/kabkabm/defensegan
Face-MagNet: Magnifying Feature Maps to Detect Small Faces
Mar 14, 2018
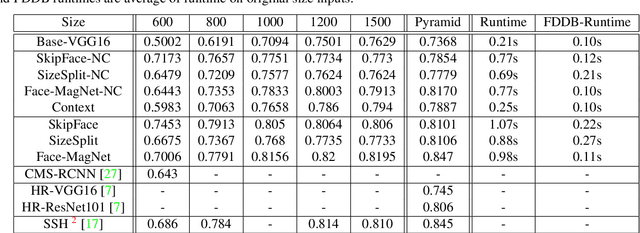
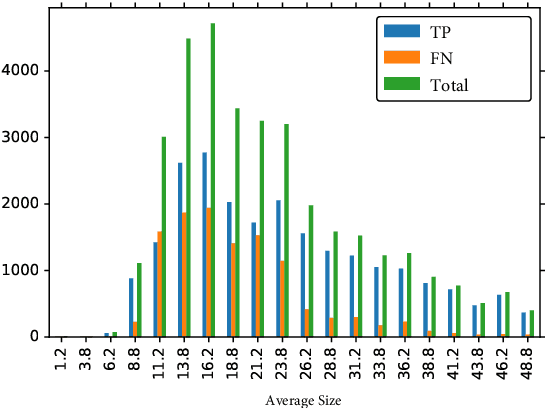
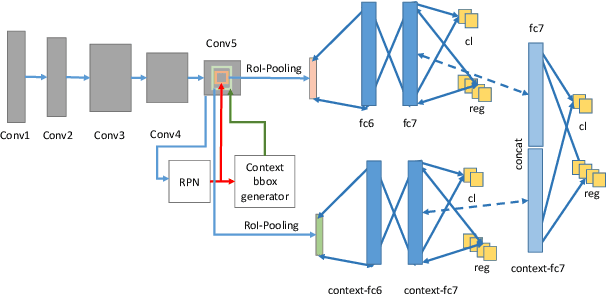
In this paper, we introduce the Face Magnifier Network (Face-MageNet), a face detector based on the Faster-RCNN framework which enables the flow of discriminative information of small scale faces to the classifier without any skip or residual connections. To achieve this, Face-MagNet deploys a set of ConvTranspose, also known as deconvolution, layers in the Region Proposal Network (RPN) and another set before the Region of Interest (RoI) pooling layer to facilitate detection of finer faces. In addition, we also design, train, and evaluate three other well-tuned architectures that represent the conventional solutions to the scale problem: context pooling, skip connections, and scale partitioning. Each of these three networks achieves comparable results to the state-of-the-art face detectors. With extensive experiments, we show that Face-MagNet based on a VGG16 architecture achieves better results than the recently proposed ResNet101-based HR method on the task of face detection on WIDER dataset and also achieves similar results on the hard set as our other method SSH.
Task-Aware Compressed Sensing with Generative Adversarial Networks
Feb 05, 2018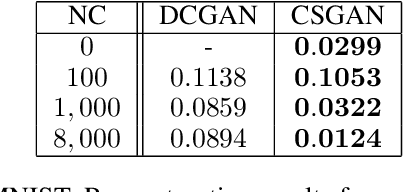
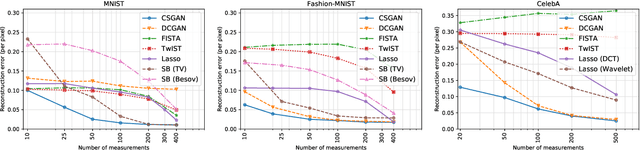
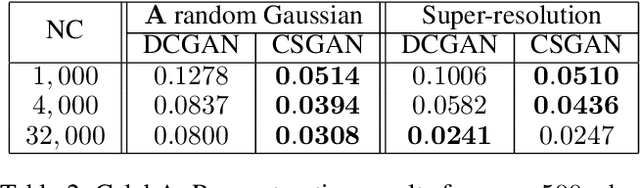
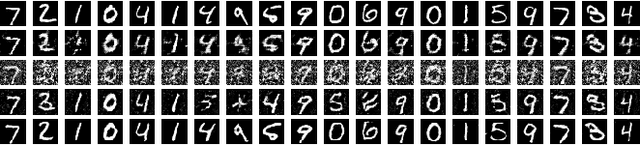
In recent years, neural network approaches have been widely adopted for machine learning tasks, with applications in computer vision. More recently, unsupervised generative models based on neural networks have been successfully applied to model data distributions via low-dimensional latent spaces. In this paper, we use Generative Adversarial Networks (GANs) to impose structure in compressed sensing problems, replacing the usual sparsity constraint. We propose to train the GANs in a task-aware fashion, specifically for reconstruction tasks. We also show that it is possible to train our model without using any (or much) non-compressed data. Finally, we show that the latent space of the GAN carries discriminative information and can further be regularized to generate input features for general inference tasks. We demonstrate the effectiveness of our method on a variety of reconstruction and classification problems.
SSH: Single Stage Headless Face Detector
Oct 18, 2017
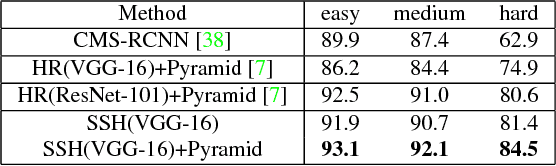
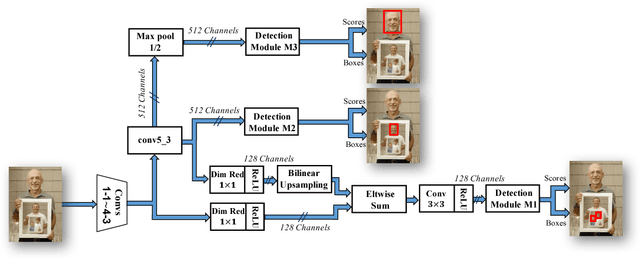

We introduce the Single Stage Headless (SSH) face detector. Unlike two stage proposal-classification detectors, SSH detects faces in a single stage directly from the early convolutional layers in a classification network. SSH is headless. That is, it is able to achieve state-of-the-art results while removing the "head" of its underlying classification network -- i.e. all fully connected layers in the VGG-16 which contains a large number of parameters. Additionally, instead of relying on an image pyramid to detect faces with various scales, SSH is scale-invariant by design. We simultaneously detect faces with different scales in a single forward pass of the network, but from different layers. These properties make SSH fast and light-weight. Surprisingly, with a headless VGG-16, SSH beats the ResNet-101-based state-of-the-art on the WIDER dataset. Even though, unlike the current state-of-the-art, SSH does not use an image pyramid and is 5X faster. Moreover, if an image pyramid is deployed, our light-weight network achieves state-of-the-art on all subsets of the WIDER dataset, improving the AP by 2.5%. SSH also reaches state-of-the-art results on the FDDB and Pascal-Faces datasets while using a small input size, leading to a runtime of 50 ms/image on a GPU. The code is available at https://github.com/mahyarnajibi/SSH.
Convolutional Neural Networks for Attribute-based Active Authentication on Mobile Devices
Jul 08, 2016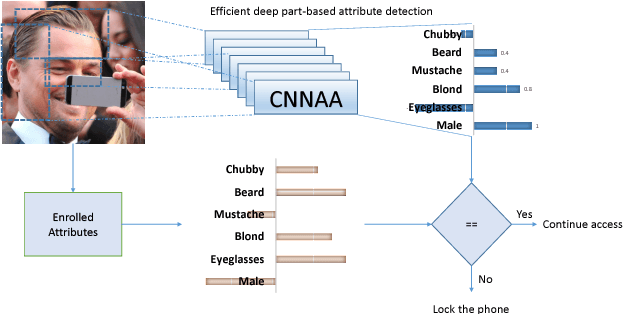
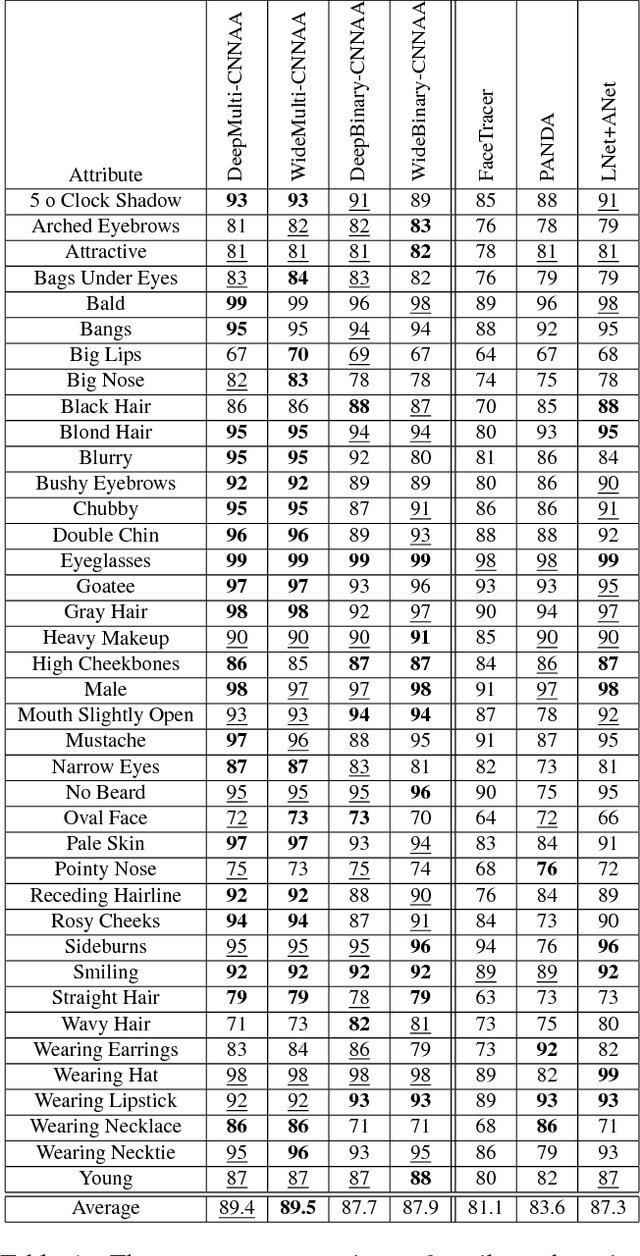
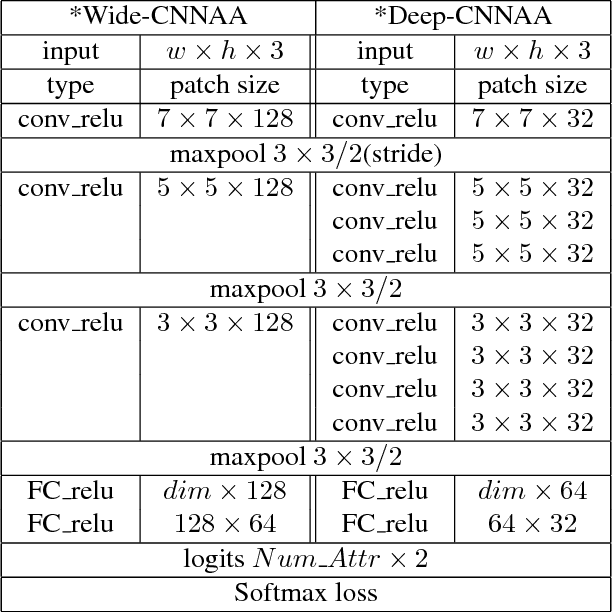

We present a Deep Convolutional Neural Network (DCNN) architecture for the task of continuous authentication on mobile devices. To deal with the limited resources of these devices, we reduce the complexity of the networks by learning intermediate features such as gender and hair color instead of identities. We present a multi-task, part-based DCNN architecture for attribute detection that performs better than the state-of-the-art methods in terms of accuracy. As a byproduct of the proposed architecture, we are able to explore the embedding space of the attributes extracted from different facial parts, such as mouth and eyes, to discover new attributes. Furthermore, through extensive experimentation, we show that the attribute features extracted by our method outperform the previously presented attribute-based method and a baseline LBP method for the task of active authentication. Lastly, we demonstrate the effectiveness of the proposed architecture in terms of speed and power consumption by deploying it on an actual mobile device.