 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR4D: Utilizing Reference Objects for Long-Range Distance Estimation
Jun 10, 2022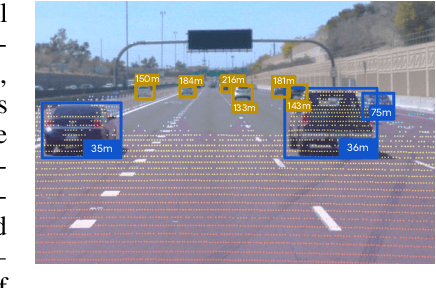

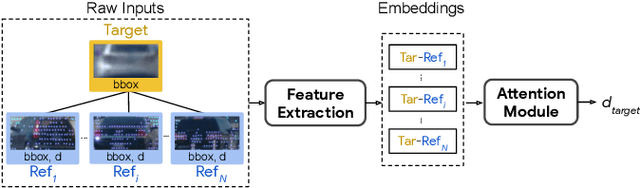
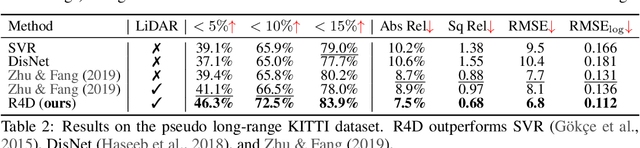
Estimating the distance of objects is a safety-critical task for autonomous driving. Focusing on short-range objects, existing methods and datasets neglect the equally important long-range objects. In this paper, we introduce a challenging and under-explored task, which we refer to as Long-Range Distance Estimation, as well as two datasets to validate new methods developed for this task. We then proposeR4D, the first framework to accurately estimate the distance of long-range objects by using references with known distances in the scene. Drawing inspiration from human perception, R4D builds a graph by connecting a target object to all references. An edge in the graph encodes the relative distance information between a pair of target and reference objects. An attention module is then used to weigh the importance of reference objects and combine them into one target object distance prediction. Experiments on the two proposed datasets demonstrate the effectiveness and robustness of R4D by showing significant improvements compared to existing baselines. We are looking to make the proposed dataset, Waymo OpenDataset - Long-Range Labels, available publicly at waymo.com/open/download.
Defense-GAN: Protecting Classifiers Against Adversarial Attacks Using Generative Models
May 18, 2018
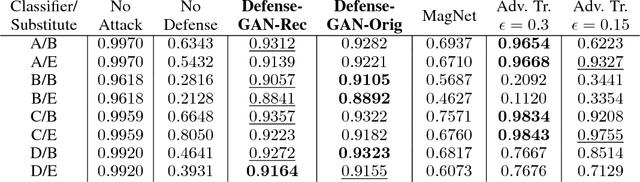
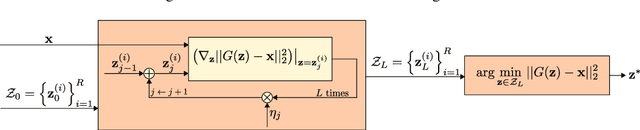
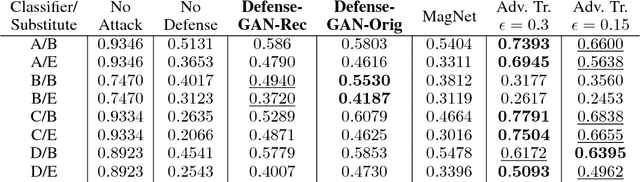
In recent years, deep neural network approaches have been widely adopted for machine learning tasks, including classification. However, they were shown to be vulnerable to adversarial perturbations: carefully crafted small perturbations can cause misclassification of legitimate images. We propose Defense-GAN, a new framework leveraging the expressive capability of generative models to defend deep neural networks against such attacks. Defense-GAN is trained to model the distribution of unperturbed images. At inference time, it finds a close output to a given image which does not contain the adversarial changes. This output is then fed to the classifier. Our proposed method can be used with any classification model and does not modify the classifier structure or training procedure. It can also be used as a defense against any attack as it does not assume knowledge of the process for generating the adversarial examples. We empirically show that Defense-GAN is consistently effective against different attack methods and improves on existing defense strategies. Our code has been made publicly available at https://github.com/kabkabm/defensegan
Task-Aware Compressed Sensing with Generative Adversarial Networks
Feb 05, 2018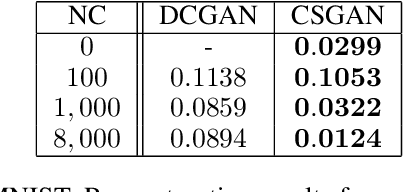
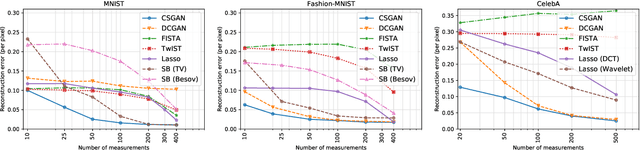
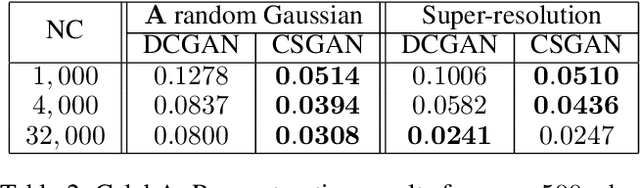
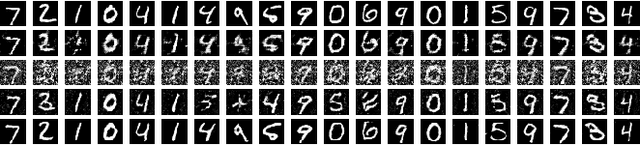
In recent years, neural network approaches have been widely adopted for machine learning tasks, with applications in computer vision. More recently, unsupervised generative models based on neural networks have been successfully applied to model data distributions via low-dimensional latent spaces. In this paper, we use Generative Adversarial Networks (GANs) to impose structure in compressed sensing problems, replacing the usual sparsity constraint. We propose to train the GANs in a task-aware fashion, specifically for reconstruction tasks. We also show that it is possible to train our model without using any (or much) non-compressed data. Finally, we show that the latent space of the GAN carries discriminative information and can further be regularized to generate input features for general inference tasks. We demonstrate the effectiveness of our method on a variety of reconstruction and classification problems.
DCNNs on a Diet: Sampling Strategies for Reducing the Training Set Size
Jun 14, 2016


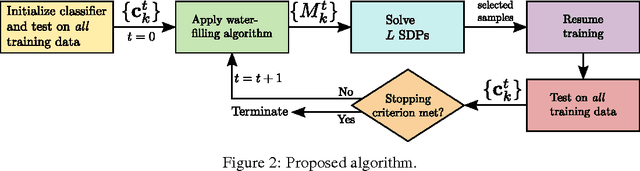
Large-scale supervised classification algorithms, especially those based on deep convolutional neural networks (DCNNs), require vast amounts of training data to achieve state-of-the-art performance. Decreasing this data requirement would significantly speed up the training process and possibly improve generalization. Motivated by this objective, we consider the task of adaptively finding concise training subsets which will be iteratively presented to the learner. We use convex optimization methods, based on an objective criterion and feedback from the current performance of the classifier, to efficiently identify informative samples to train on. We propose an algorithm to decompose the optimization problem into smaller per-class problems, which can be solved in parallel. We test our approach on standard classification tasks and demonstrate its effectiveness in decreasing the training set size without compromising performance. We also show that our approach can make the classifier more robust in the presence of label noise and class imbalance.