 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCNNs on a Diet: Sampling Strategies for Reducing the Training Set Size
Paper and Code
Jun 14, 2016


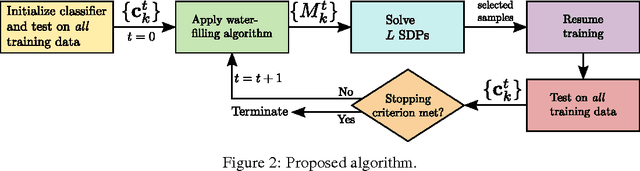
Large-scale supervised classification algorithms, especially those based on deep convolutional neural networks (DCNNs), require vast amounts of training data to achieve state-of-the-art performance. Decreasing this data requirement would significantly speed up the training process and possibly improve generalization. Motivated by this objective, we consider the task of adaptively finding concise training subsets which will be iteratively presented to the learner. We use convex optimization methods, based on an objective criterion and feedback from the current performance of the classifier, to efficiently identify informative samples to train on. We propose an algorithm to decompose the optimization problem into smaller per-class problems, which can be solved in parallel. We test our approach on standard classification tasks and demonstrate its effectiveness in decreasing the training set size without compromising performance. We also show that our approach can make the classifier more robust in the presence of label noise and class imbalance.