 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Style-based Explicit 3D Face Reconstruction from Single Image
Apr 24, 2023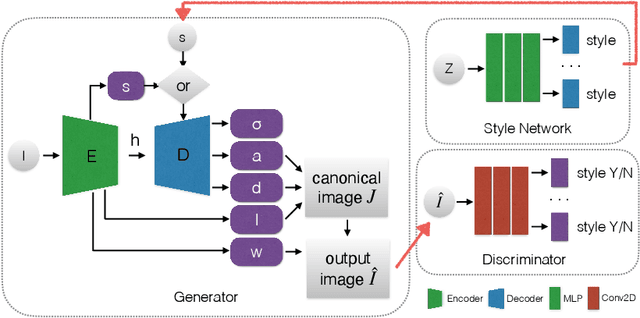
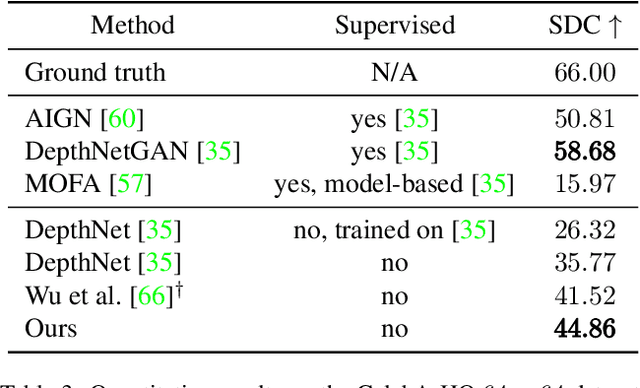
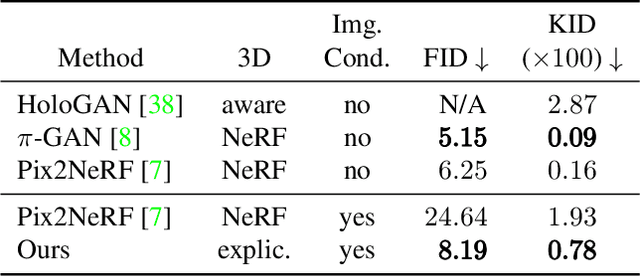

Inferring 3D object structures from a single image is an ill-posed task due to depth ambiguity and occlusion. Typical resolutions in the literature include leveraging 2D or 3D ground truth for supervised learning, as well as imposing hand-crafted symmetry priors or using an implicit representation to hallucinate novel viewpoints for unsupervised methods. In this work, we propose a general adversarial learning framework for solving Unsupervised 2D to Explicit 3D Style Transfer (UE3DST). Specifically, we merge two architectures: the unsupervised explicit 3D reconstruction network of Wu et al.\ and the Generative Adversarial Network (GAN) named StarGAN-v2. We experiment across three facial datasets (Basel Face Model, 3DFAW and CelebA-HQ) and show that our solution is able to outperform well established solutions such as DepthNet in 3D reconstruction and Pix2NeRF in conditional style transfer, while we also justify the individual contributions of our model components via ablation. In contrast to the aforementioned baselines, our scheme produces features for explicit 3D rendering, which can be manipulated and utilized in downstream tasks.
DyLiN: Making Light Field Networks Dynamic
Mar 24, 2023



Light Field Networks, the re-formulations of radiance fields to oriented rays, are magnitudes faster than their coordinate network counterparts, and provide higher fidelity with respect to representing 3D structures from 2D observations. They would be well suited for generic scene representation and manipulation, but suffer from one problem: they are limited to holistic and static scenes. In this paper, we propose the Dynamic Light Field Network (DyLiN) method that can handle non-rigid deformations, including topological changes. We learn a deformation field from input rays to canonical rays, and lift them into a higher dimensional space to handle discontinuities. We further introduce CoDyLiN, which augments DyLiN with controllable attribute inputs. We train both models via knowledge distillation from pretrained dynamic radiance fields. We evaluated DyLiN using both synthetic and real world datasets that include various non-rigid deformations. DyLiN qualitatively outperformed and quantitatively matched state-of-the-art methods in terms of visual fidelity, while being 25 - 71x computationally faster. We also tested CoDyLiN on attribute annotated data and it surpassed its teacher model. Project page: https://dylin2023.github.io .