 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Cascading Effects in Large Adversarial Graph Environments
Apr 12, 2024A significant amount of society's infrastructure can be modeled using graph structures, from electric and communication grids, to traffic networks, to social networks. Each of these domains are also susceptible to the cascading spread of negative impacts, whether this be overloaded devices in the power grid or the reach of a social media post containing misinformation. The potential harm of a cascade is compounded when considering a malicious attack by an adversary that is intended to maximize the cascading impact. However, by exploiting knowledge of the cascading dynamics, targets with the largest cascading impact can be preemptively prioritized for defense, and the damage an adversary can inflict can be mitigated. While game theory provides tools for finding an optimal preemptive defense strategy, existing methods struggle to scale to the context of large graph environments because of the combinatorial explosion of possible actions that occurs when the attacker and defender can each choose multiple targets in the graph simultaneously. The proposed method enables a data-driven deep learning approach that uses multi-node representation learning and counterfactual data augmentation to generalize to the full combinatorial action space by training on a variety of small restricted subsets of the action space. We demonstrate through experiments that the proposed method is capable of identifying defense strategies that are less exploitable than SOTA methods for large graphs, while still being able to produce strategies near the Nash equilibrium for small-scale scenarios for which it can be computed. Moreover, the proposed method demonstrates superior prediction accuracy on a validation set of unseen cascades compared to other deep learning approaches.
Instantaneous Physiological Estimation using Video Transformers
Feb 24, 2022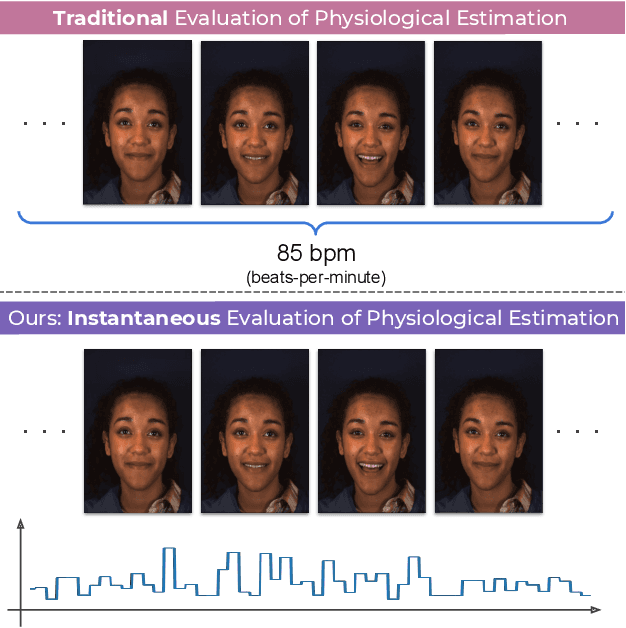
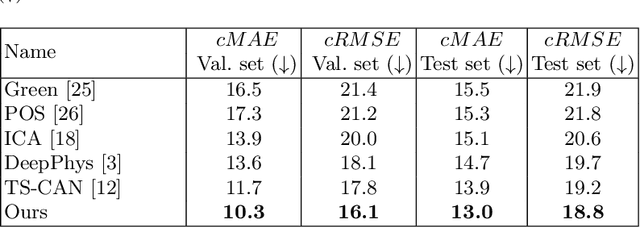
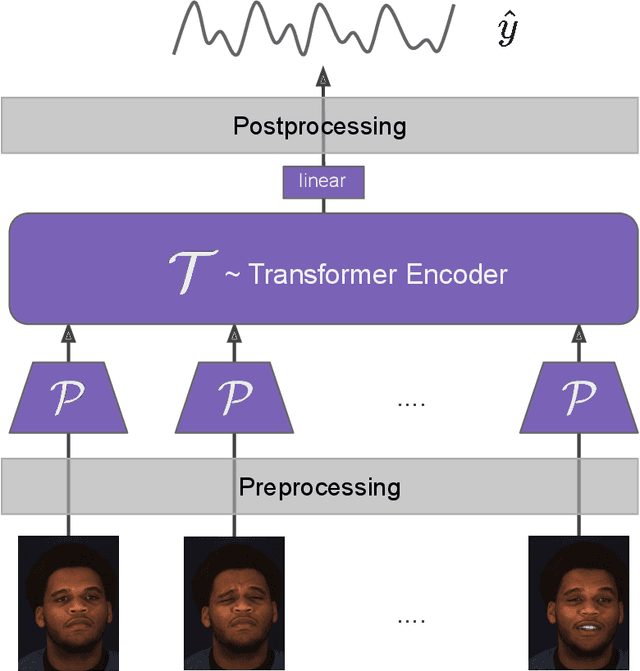
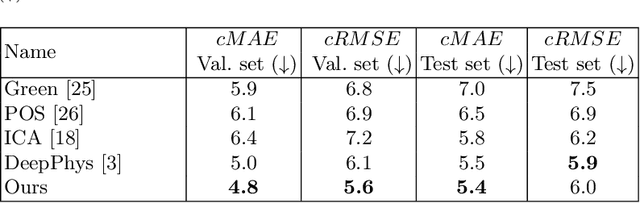
Video-based physiological signal estimation has been limited primarily to predicting episodic scores in windowed intervals. While these intermittent values are useful, they provide an incomplete picture of patients' physiological status and may lead to late detection of critical conditions. We propose a video Transformer for estimating instantaneous heart rate and respiration rate from face videos. Physiological signals are typically confounded by alignment errors in space and time. To overcome this, we formulated the loss in the frequency domain. We evaluated the method on the large scale Vision-for-Vitals (V4V) benchmark. It outperformed both shallow and deep learning based methods for instantaneous respiration rate estimation. In the case of heart-rate estimation, it achieved an instantaneous-MAE of 13.0 beats-per-minute.