 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour "Attention" Deserves Attention: A Self-Diversified Multi-Channel Attention for Facial Action Analysis
Paper and Code
Mar 23, 2022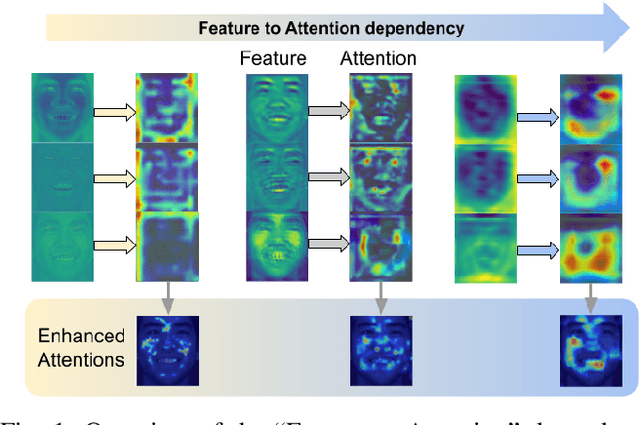
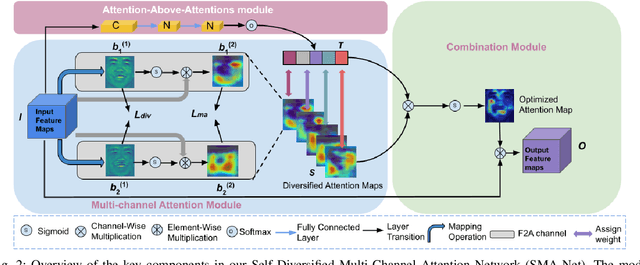
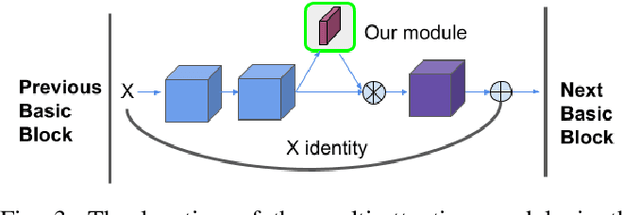
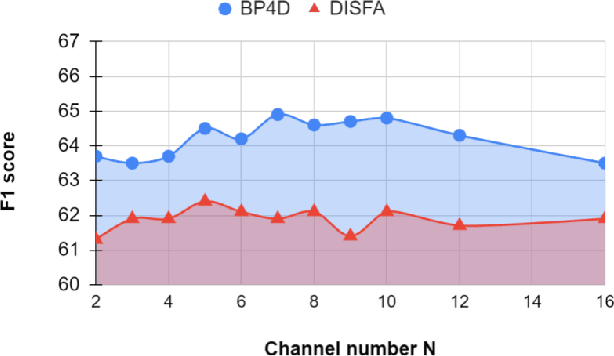
Visual attention has been extensively studied for learning fine-grained features in both facial expression recognition (FER) and Action Unit (AU) detection. A broad range of previous research has explored how to use attention modules to localize detailed facial parts (e,g. facial action units), learn discriminative features, and learn inter-class correlation. However, few related works pay attention to the robustness of the attention module itself. Through experiments, we found neural attention maps initialized with different feature maps yield diverse representations when learning to attend the identical Region of Interest (ROI). In other words, similar to general feature learning, the representational quality of attention maps also greatly affects the performance of a model, which means unconstrained attention learning has lots of randomnesses. This uncertainty lets conventional attention learning fall into sub-optimal. In this paper, we propose a compact model to enhance the representational and focusing power of neural attention maps and learn the "inter-attention" correlation for refined attention maps, which we term the "Self-Diversified Multi-Channel Attention Network (SMA-Net)". The proposed method is evaluated on two benchmark databases (BP4D and DISFA) for AU detection and four databases (CK+, MMI, BU-3DFE, and BP4D+) for facial expression recognition. It achieves superior performance compared to the state-of-the-art methods.