 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Supervised Bootstrap Method for Single-Image 3D Face Reconstruction
Paper and Code
Dec 17, 2018

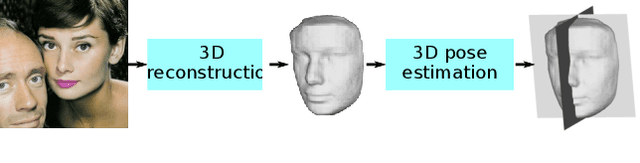
State-of-the-art methods for 3D reconstruction of faces from a single image require 2D-3D pairs of ground-truth data for supervision. Such data is costly to acquire, and most datasets available in the literature are restricted to pairs for which the input 2D images depict faces in a near fronto-parallel pose. Therefore, many data-driven methods for single-image 3D facial reconstruction perform poorly on profile and near-profile faces. We propose a method to improve the performance of single-image 3D facial reconstruction networks by utilizing the network to synthesize its own training data for fine-tuning, comprising: (i) single-image 3D reconstruction of faces in near-frontal images without ground-truth 3D shape; (ii) application of a rigid-body transformation to the reconstructed face model; (iii) rendering of the face model from new viewpoints; and (iv) use of the rendered image and corresponding 3D reconstruction as additional data for supervised fine-tuning. The new 2D-3D pairs thus produced have the same high-quality observed for near fronto-parallel reconstructions, thereby nudging the network towards more uniform performance as a function of the viewing angle of input faces. Application of the proposed technique to the fine-tuning of a state-of-the-art single-image 3D-reconstruction network for faces demonstrates the usefulness of the method, with particularly significant gains for profile or near-profile views.