 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Distribution Valuation Using Generalized Bayesian Inference
Apr 07, 2026We investigate the data distribution valuation problem, which aims to quantify the values of data distributions from their samples. This is a recently proposed problem that is related to but different from classical data valuation and can be applied to various applications. For this problem, we develop a novel framework called Generalized Bayes Valuation that utilizes generalized Bayesian inference with a loss constructed from transferability measures. This framework allows us to solve, in a unified way, seemingly unrelated practical problems, such as annotator evaluation and data augmentation. Using the Bayesian principles, we further improve and enhance the applicability of our framework by extending it to the continuous data stream setting. Our experiment results confirm the effectiveness and efficiency of our framework in different real-world scenarios.
PTB-Image: A Scanned Paper ECG Dataset for Digitization and Image-based Diagnosis
Feb 19, 2025Electrocardiograms (ECGs) recorded on paper remain prevalent in clinical practice, yet their use presents challenges for automated analysis and digital storage. To address this issue, we introduce PTB-Image, a dataset comprising scanned paper ECGs with corresponding digital signals, enabling research on ECG digitization. We also provide VinDigitizer, a digitization baseline to convert paper-based ECGs into digital time-series signals. The method involves detecting signal rows, extracting waveforms from the background, and reconstructing numerical values from the digitized traces. We applied VinDigitizer to 549 scanned ECGs and evaluated its performance against the original PTB dataset (modified to match the printed signals). The results achieved a mean signal-to-noise ratio (SNR) of 0.01 dB, highlighting both the feasibility and challenges of ECG digitization, particularly in mitigating distortions from printing and scanning processes. By providing PTB-Image and baseline digitization methods, this work aims to facilitate advancements in ECG digitization, enhancing access to historical ECG data and supporting applications in telemedicine and automated cardiac diagnostics.
Sequence Transferability and Task Order Selection in Continual Learning
Feb 10, 2025In continual learning, understanding the properties of task sequences and their relationships to model performance is important for developing advanced algorithms with better accuracy. However, efforts in this direction remain underdeveloped despite encouraging progress in methodology development. In this work, we investigate the impacts of sequence transferability on continual learning and propose two novel measures that capture the total transferability of a task sequence, either in the forward or backward direction. Based on the empirical properties of these measures, we then develop a new method for the task order selection problem in continual learning. Our method can be shown to offer a better performance than the conventional strategy of random task selection.
Fake Advertisements Detection Using Automated Multimodal Learning: A Case Study for Vietnamese Real Estate Data
Jan 18, 2025The popularity of e-commerce has given rise to fake advertisements that can expose users to financial and data risks while damaging the reputation of these e-commerce platforms. For these reasons, detecting and removing such fake advertisements are important for the success of e-commerce websites. In this paper, we propose FADAML, a novel end-to-end machine learning system to detect and filter out fake online advertisements. Our system combines techniques in multimodal machine learning and automated machine learning to achieve a high detection rate. As a case study, we apply FADAML to detect fake advertisements on popular Vietnamese real estate websites. Our experiments show that we can achieve 91.5% detection accuracy, which significantly outperforms three different state-of-the-art fake news detection systems.
Hamiltonian Monte Carlo on ReLU Neural Networks is Inefficient
Oct 29, 2024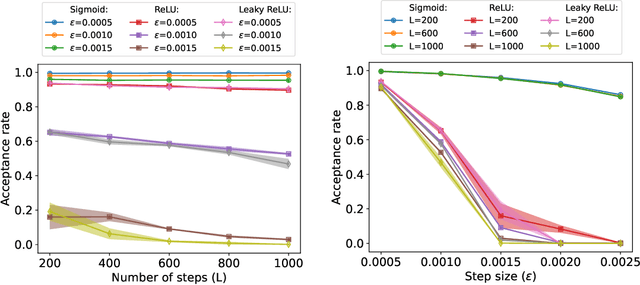



We analyze the error rates of the Hamiltonian Monte Carlo algorithm with leapfrog integrator for Bayesian neural network inference. We show that due to the non-differentiability of activation functions in the ReLU family, leapfrog HMC for networks with these activation functions has a large local error rate of $\Omega(\epsilon)$ rather than the classical error rate of $O(\epsilon^3)$. This leads to a higher rejection rate of the proposals, making the method inefficient. We then verify our theoretical findings through empirical simulations as well as experiments on a real-world dataset that highlight the inefficiency of HMC inference on ReLU-based neural networks compared to analytical networks.
Transfer Learning in ECG Diagnosis: Is It Effective?
Feb 03, 2024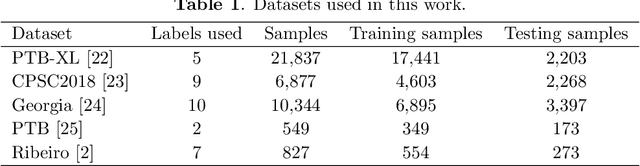
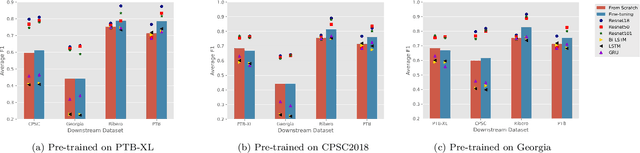
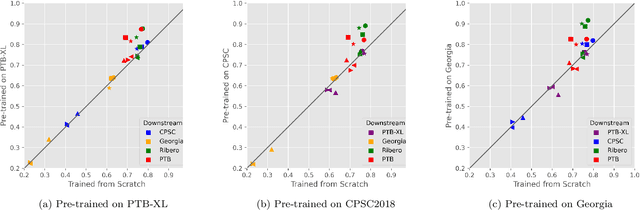
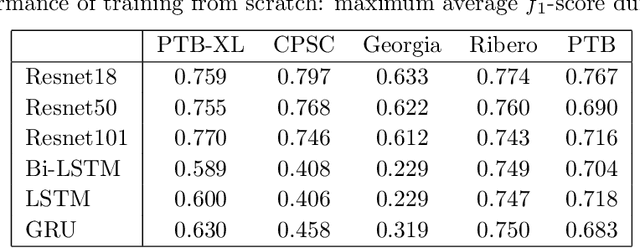
The adoption of deep learning in ECG diagnosis is often hindered by the scarcity of large, well-labeled datasets in real-world scenarios, leading to the use of transfer learning to leverage features learned from larger datasets. Yet the prevailing assumption that transfer learning consistently outperforms training from scratch has never been systematically validated. In this study, we conduct the first extensive empirical study on the effectiveness of transfer learning in multi-label ECG classification, by investigating comparing the fine-tuning performance with that of training from scratch, covering a variety of ECG datasets and deep neural networks. We confirm that fine-tuning is the preferable choice for small downstream datasets; however, when the dataset is sufficiently large, training from scratch can achieve comparable performance, albeit requiring a longer training time to catch up. Furthermore, we find that transfer learning exhibits better compatibility with convolutional neural networks than with recurrent neural networks, which are the two most prevalent architectures for time-series ECG applications. Our results underscore the importance of transfer learning in ECG diagnosis, yet depending on the amount of available data, researchers may opt not to use it, considering the non-negligible cost associated with pre-training.
Explainable Severity ranking via pairwise n-hidden comparison: a case study of glaucoma
Dec 05, 2023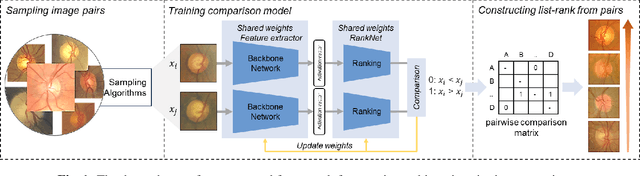

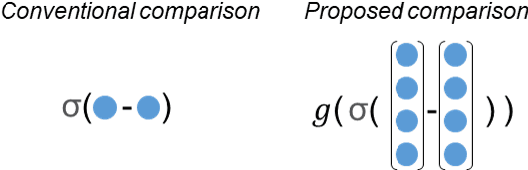
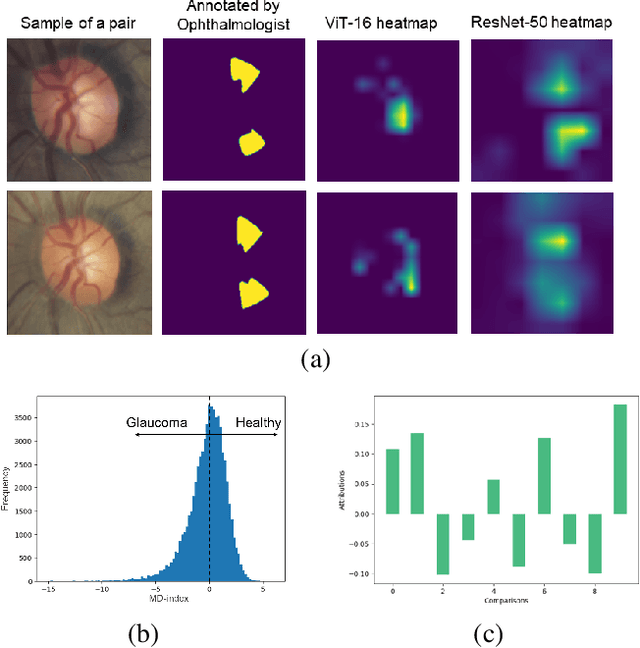
Primary open-angle glaucoma (POAG) is a chronic and progressive optic nerve condition that results in an acquired loss of optic nerve fibers and potential blindness. The gradual onset of glaucoma results in patients progressively losing their vision without being consciously aware of the changes. To diagnose POAG and determine its severity, patients must undergo a comprehensive dilated eye examination. In this work, we build a framework to rank, compare, and interpret the severity of glaucoma using fundus images. We introduce a siamese-based severity ranking using pairwise n-hidden comparisons. We additionally have a novel approach to explaining why a specific image is deemed more severe than others. Our findings indicate that the proposed severity ranking model surpasses traditional ones in terms of diagnostic accuracy and delivers improved saliency explanations.
Simple Transferability Estimation for Regression Tasks
Dec 04, 2023
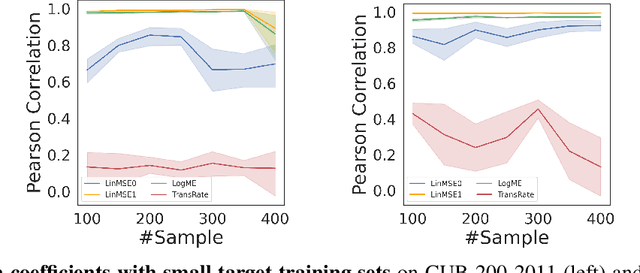
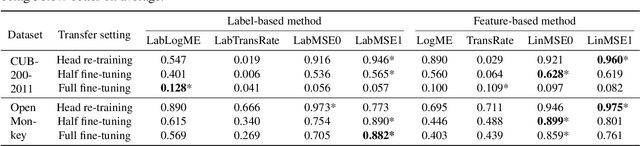
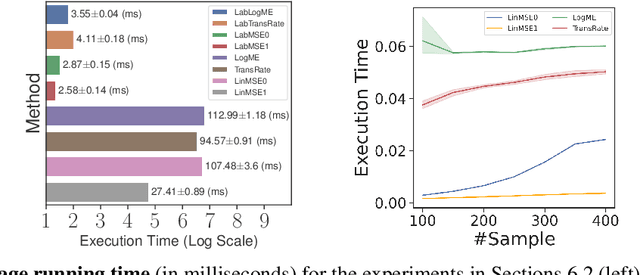
We consider transferability estimation, the problem of estimating how well deep learning models transfer from a source to a target task. We focus on regression tasks, which received little previous attention, and propose two simple and computationally efficient approaches that estimate transferability based on the negative regularized mean squared error of a linear regression model. We prove novel theoretical results connecting our approaches to the actual transferability of the optimal target models obtained from the transfer learning process. Despite their simplicity, our approaches significantly outperform existing state-of-the-art regression transferability estimators in both accuracy and efficiency. On two large-scale keypoint regression benchmarks, our approaches yield 12% to 36% better results on average while being at least 27% faster than previous state-of-the-art methods.
MELEP: A Novel Predictive Measure of Transferability in Multi-Label ECG Analysis
Oct 27, 2023We introduce MELEP, which stands for Muti-label Expected Log of Empirical Predictions, a novel measure to estimate how effective it is to transfer knowledge from a pre-trained model to a downstream task in a multi-label settings. The measure is generic to work with new target data having a different label set from source data. It is also computationally efficient, only requires forward passing the downstream dataset through the pre-trained model once. To the best of our knowledge, we are the first to develop such a transferability metric for multi-label ECG classification problems. Our experiments show that MELEP can predict the performance of pre-trained convolutional and recurrent deep neural networks, on small and imbalanced ECG data. Specifically, strong correlation coefficients, with absolute values exceeding 0.6 in most cases, were observed between MELEP and the actual average F1 scores of the fine-tuned models.
Hate Speech Detection in Limited Data Contexts using Synthetic Data Generation
Oct 04, 2023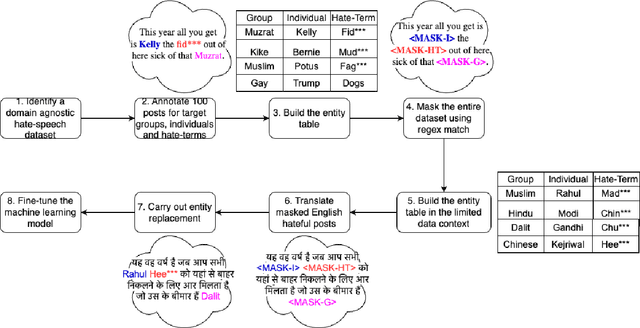
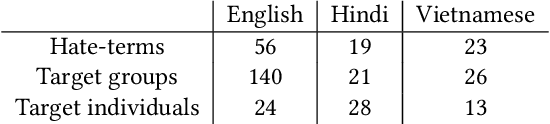

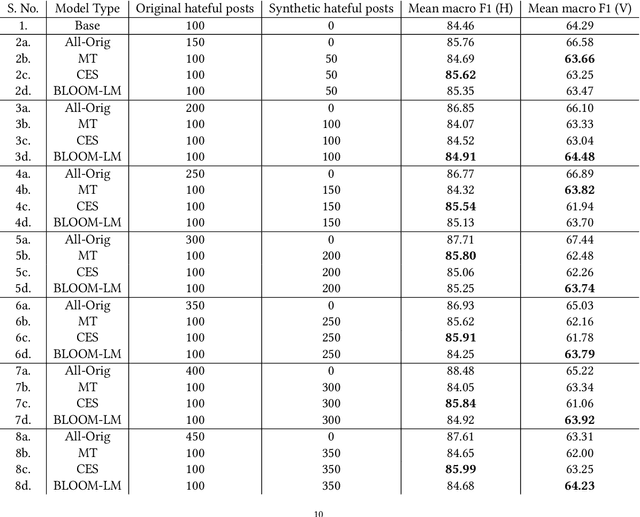
A growing body of work has focused on text classification methods for detecting the increasing amount of hate speech posted online. This progress has been limited to only a select number of highly-resourced languages causing detection systems to either under-perform or not exist in limited data contexts. This is majorly caused by a lack of training data which is expensive to collect and curate in these settings. In this work, we propose a data augmentation approach that addresses the problem of lack of data for online hate speech detection in limited data contexts using synthetic data generation techniques. Given a handful of hate speech examples in a high-resource language such as English, we present three methods to synthesize new examples of hate speech data in a target language that retains the hate sentiment in the original examples but transfers the hate targets. We apply our approach to generate training data for hate speech classification tasks in Hindi and Vietnamese. Our findings show that a model trained on synthetic data performs comparably to, and in some cases outperforms, a model trained only on the samples available in the target domain. This method can be adopted to bootstrap hate speech detection models from scratch in limited data contexts. As the growth of social media within these contexts continues to outstrip response efforts, this work furthers our capacities for detection, understanding, and response to hate speech.