 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence Transferability and Task Order Selection in Continual Learning
Feb 10, 2025In continual learning, understanding the properties of task sequences and their relationships to model performance is important for developing advanced algorithms with better accuracy. However, efforts in this direction remain underdeveloped despite encouraging progress in methodology development. In this work, we investigate the impacts of sequence transferability on continual learning and propose two novel measures that capture the total transferability of a task sequence, either in the forward or backward direction. Based on the empirical properties of these measures, we then develop a new method for the task order selection problem in continual learning. Our method can be shown to offer a better performance than the conventional strategy of random task selection.
Simple Transferability Estimation for Regression Tasks
Dec 04, 2023
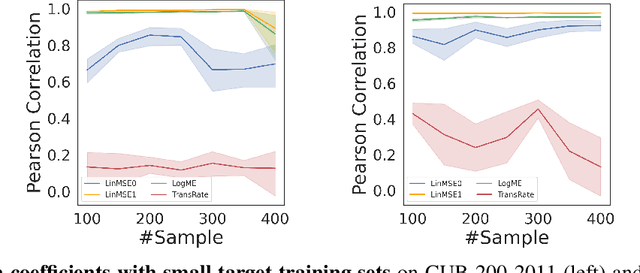
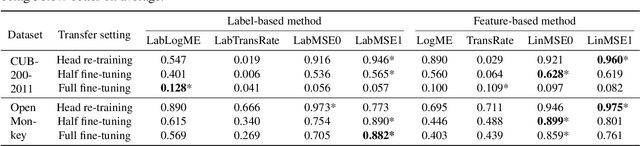
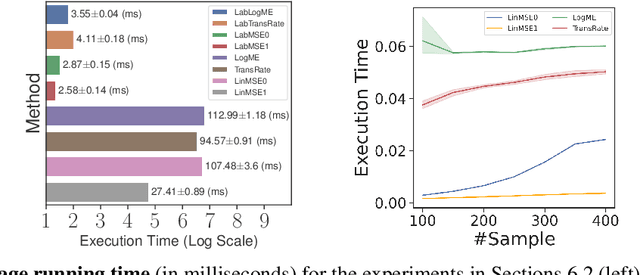
We consider transferability estimation, the problem of estimating how well deep learning models transfer from a source to a target task. We focus on regression tasks, which received little previous attention, and propose two simple and computationally efficient approaches that estimate transferability based on the negative regularized mean squared error of a linear regression model. We prove novel theoretical results connecting our approaches to the actual transferability of the optimal target models obtained from the transfer learning process. Despite their simplicity, our approaches significantly outperform existing state-of-the-art regression transferability estimators in both accuracy and efficiency. On two large-scale keypoint regression benchmarks, our approaches yield 12% to 36% better results on average while being at least 27% faster than previous state-of-the-art methods.
Generalization Bounds for Deep Transfer Learning Using Majority Predictor Accuracy
Sep 13, 2022We analyze new generalization bounds for deep learning models trained by transfer learning from a source to a target task. Our bounds utilize a quantity called the majority predictor accuracy, which can be computed efficiently from data. We show that our theory is useful in practice since it implies that the majority predictor accuracy can be used as a transferability measure, a fact that is also validated by our experiments.
VinDr-CXR: An open dataset of chest X-rays with radiologist's annotations
Jan 03, 2021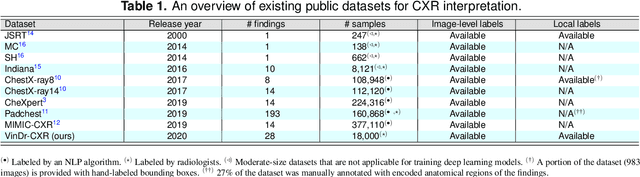
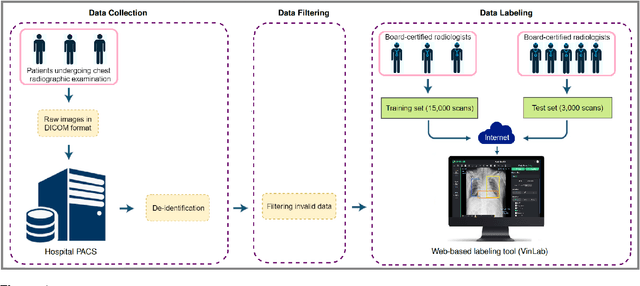
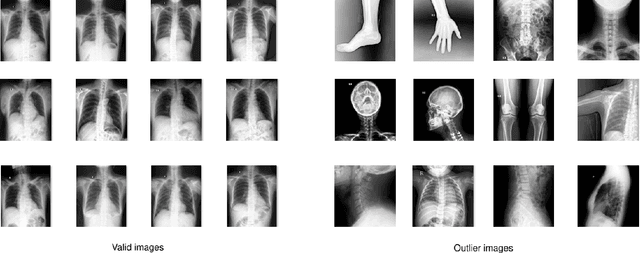
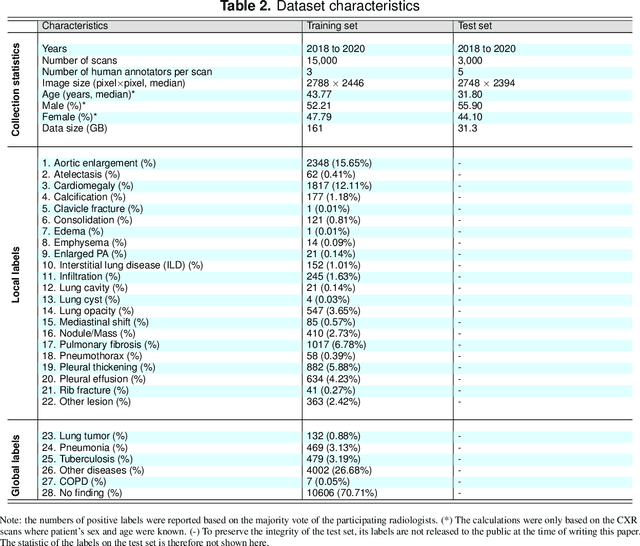
Most of the existing chest X-ray datasets include labels from a list of findings without specifying their locations on the radiographs. This limits the development of machine learning algorithms for the detection and localization of chest abnormalities. In this work, we describe a dataset of more than 100,000 chest X-ray scans that were retrospectively collected from two major hospitals in Vietnam. Out of this raw data, we release 18,000 images that were manually annotated by a total of 17 experienced radiologists with 22 local labels of rectangles surrounding abnormalities and 6 global labels of suspected diseases. The released dataset is divided into a training set of 15,000 and a test set of 3,000. Each scan in the training set was independently labeled by 3 radiologists, while each scan in the test set was labeled by the consensus of 5 radiologists. We designed and built a labeling platform for DICOM images to facilitate these annotation procedures. All images are made publicly available in DICOM format in company with the labels of the training set. The labels of the test set are hidden at the time of writing this paper as they will be used for benchmarking machine learning algorithms on an open platform.