 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of state-of-the-art deep learning models in the segmentation of the heart ventricles in parasternal short-axis echocardiograms
Mar 12, 2025Previous studies on echocardiogram segmentation are focused on the left ventricle in parasternal long-axis views. In this study, deep-learning models were evaluated on the segmentation of the ventricles in parasternal short-axis echocardiograms (PSAX-echo). Segmentation of the ventricles in complementary echocardiogram views will allow the computation of important metrics with the potential to aid in diagnosing cardio-pulmonary diseases and other cardiomyopathies. Evaluating state-of-the-art models with small datasets can reveal if they improve performance on limited data. PSAX-echo were performed on 33 volunteer women. An experienced cardiologist identified end-diastole and end-systole frames from 387 scans, and expert observers manually traced the contours of the cardiac structures. Traced frames were pre-processed and used to create labels to train 2 specific-domain (Unet-Resnet101 and Unet-ResNet50), and 4 general-domain (3 Segment Anything (SAM) variants, and the Detectron2) deep-learning models. The performance of the models was evaluated using the Dice similarity coefficient (DSC), Hausdorff distance (HD), and difference in cross-sectional area (DCSA). The Unet-Resnet101 model provided superior performance in the segmentation of the ventricles with 0.83, 4.93 pixels, and 106 pixel2 on average for DSC, HD, and DCSA respectively. A fine-tuned MedSAM model provided a performance of 0.82, 6.66 pixels, and 1252 pixel2, while the Detectron2 model provided 0.78, 2.12 pixels, and 116 pixel2 for the same metrics respectively. Deep-learning models are suitable for the segmentation of the left and right ventricles in PSAX-echo. This study demonstrated that specific-domain trained models such as Unet-ResNet provide higher accuracy for echo segmentation than general-domain segmentation models when working with small and locally acquired datasets.
Simple Transferability Estimation for Regression Tasks
Dec 04, 2023
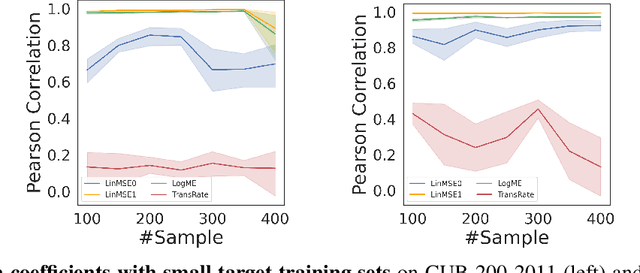
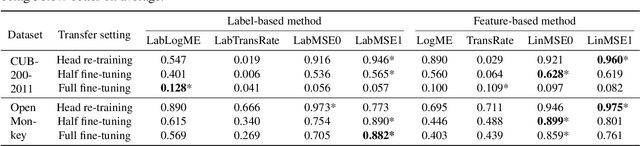
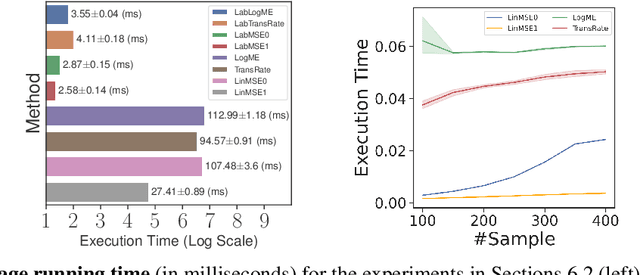
We consider transferability estimation, the problem of estimating how well deep learning models transfer from a source to a target task. We focus on regression tasks, which received little previous attention, and propose two simple and computationally efficient approaches that estimate transferability based on the negative regularized mean squared error of a linear regression model. We prove novel theoretical results connecting our approaches to the actual transferability of the optimal target models obtained from the transfer learning process. Despite their simplicity, our approaches significantly outperform existing state-of-the-art regression transferability estimators in both accuracy and efficiency. On two large-scale keypoint regression benchmarks, our approaches yield 12% to 36% better results on average while being at least 27% faster than previous state-of-the-art methods.
Generalization Bounds for Deep Transfer Learning Using Majority Predictor Accuracy
Sep 13, 2022We analyze new generalization bounds for deep learning models trained by transfer learning from a source to a target task. Our bounds utilize a quantity called the majority predictor accuracy, which can be computed efficiently from data. We show that our theory is useful in practice since it implies that the majority predictor accuracy can be used as a transferability measure, a fact that is also validated by our experiments.
Posterior concentration and fast convergence rates for generalized Bayesian learning
Nov 19, 2021
In this paper, we study the learning rate of generalized Bayes estimators in a general setting where the hypothesis class can be uncountable and have an irregular shape, the loss function can have heavy tails, and the optimal hypothesis may not be unique. We prove that under the multi-scale Bernstein's condition, the generalized posterior distribution concentrates around the set of optimal hypotheses and the generalized Bayes estimator can achieve fast learning rate. Our results are applied to show that the standard Bayesian linear regression is robust to heavy-tailed distributions.
Searching for Minimal Optimal Neural Networks
Sep 27, 2021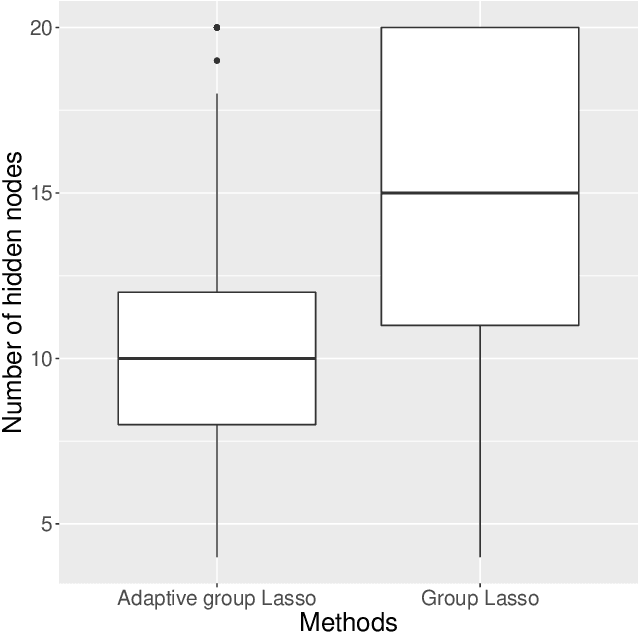
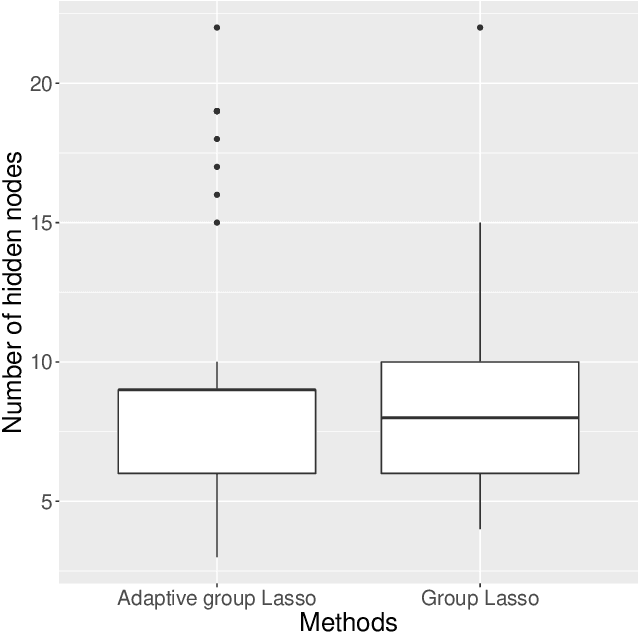
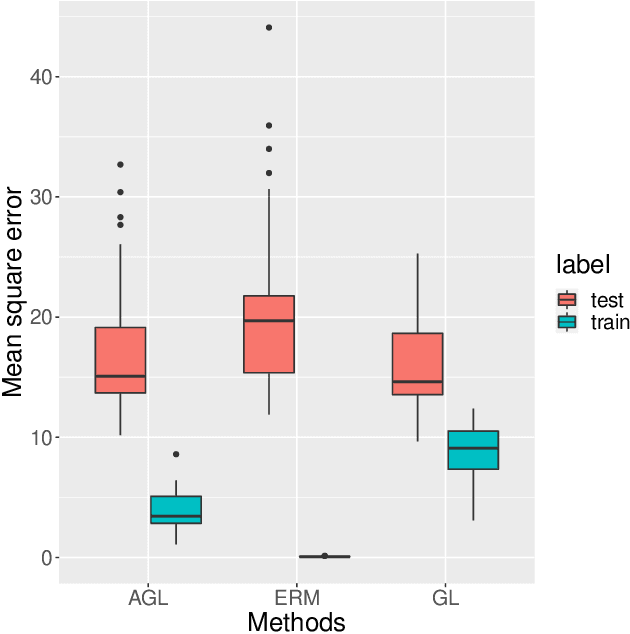
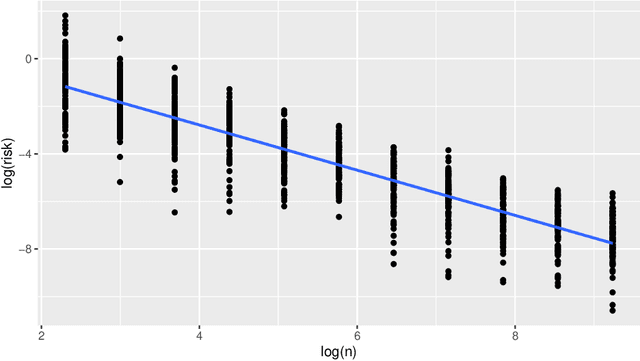
Large neural network models have high predictive power but may suffer from overfitting if the training set is not large enough. Therefore, it is desirable to select an appropriate size for neural networks. The destructive approach, which starts with a large architecture and then reduces the size using a Lasso-type penalty, has been used extensively for this task. Despite its popularity, there is no theoretical guarantee for this technique. Based on the notion of minimal neural networks, we posit a rigorous mathematical framework for studying the asymptotic theory of the destructive technique. We prove that Adaptive group Lasso is consistent and can reconstruct the correct number of hidden nodes of one-hidden-layer feedforward networks with high probability. To the best of our knowledge, this is the first theoretical result establishing for the destructive technique.
OASIS: An Active Framework for Set Inversion
May 31, 2021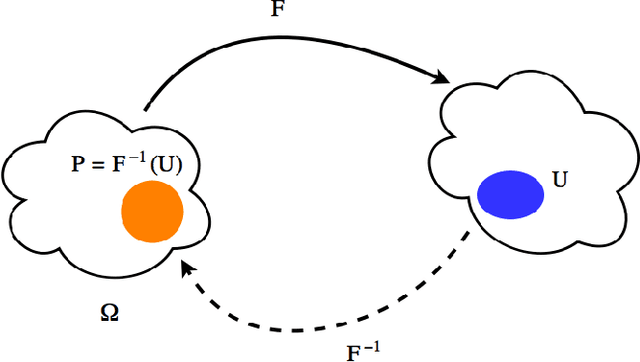
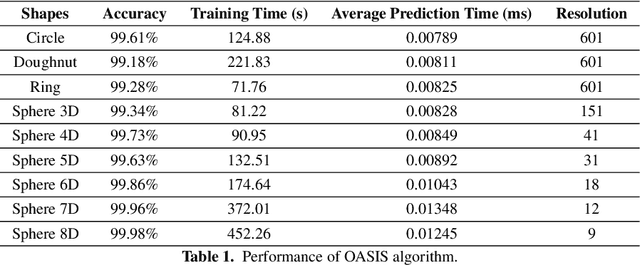
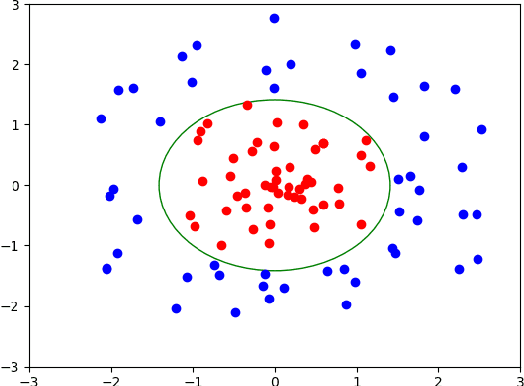
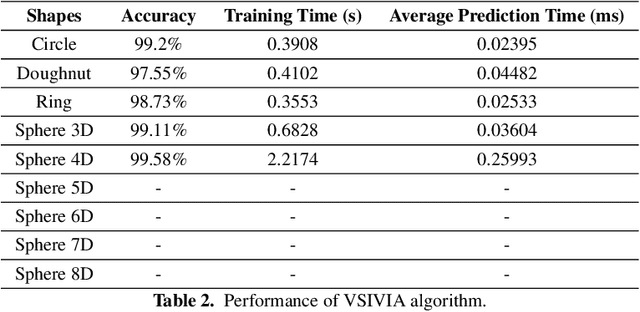
In this work, we introduce a novel method for solving the set inversion problem by formulating it as a binary classification problem. Aiming to develop a fast algorithm that can work effectively with high-dimensional and computationally expensive nonlinear models, we focus on active learning, a family of new and powerful techniques which can achieve the same level of accuracy with fewer data points compared to traditional learning methods. Specifically, we propose OASIS, an active learning framework using Support Vector Machine algorithms for solving the problem of set inversion. Our method works well in high dimensions and its computational cost is relatively robust to the increase of dimension. We illustrate the performance of OASIS by several simulation studies and show that our algorithm outperforms VISIA, the state-of-the-art method.
* 13 pages, 8 figures
Consistent Feature Selection for Analytic Deep Neural Networks
Oct 16, 2020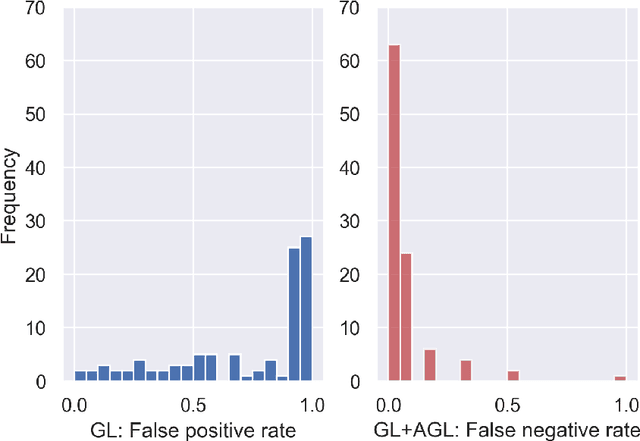
One of the most important steps toward interpretability and explainability of neural network models is feature selection, which aims to identify the subset of relevant features. Theoretical results in the field have mostly focused on the prediction aspect of the problem with virtually no work on feature selection consistency for deep neural networks due to the model's severe nonlinearity and unidentifiability. This lack of theoretical foundation casts doubt on the applicability of deep learning to contexts where correct interpretations of the features play a central role. In this work, we investigate the problem of feature selection for analytic deep networks. We prove that for a wide class of networks, including deep feed-forward neural networks, convolutional neural networks, and a major sub-class of residual neural networks, the Adaptive Group Lasso selection procedure with Group Lasso as the base estimator is selection-consistent. The work provides further evidence that Group Lasso might be inefficient for feature selection with neural networks and advocates the use of Adaptive Group Lasso over the popular Group Lasso.
Consistent feature selection for neural networks via Adaptive Group Lasso
Jun 10, 2020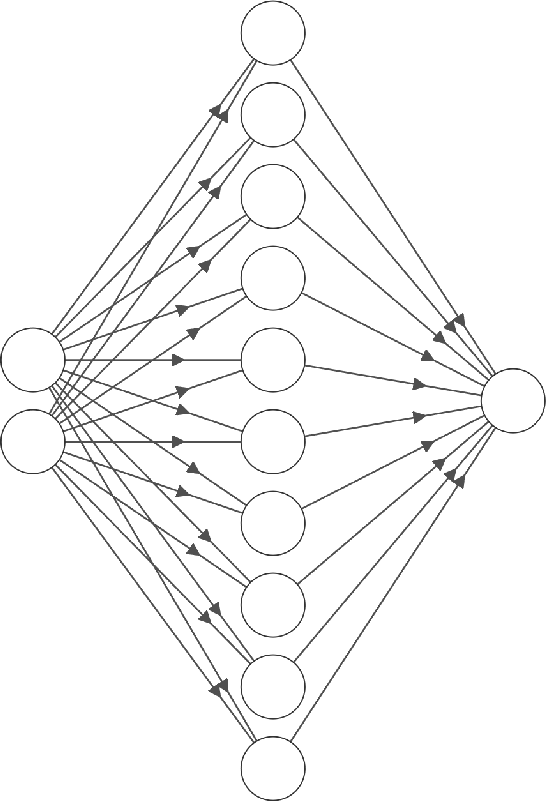


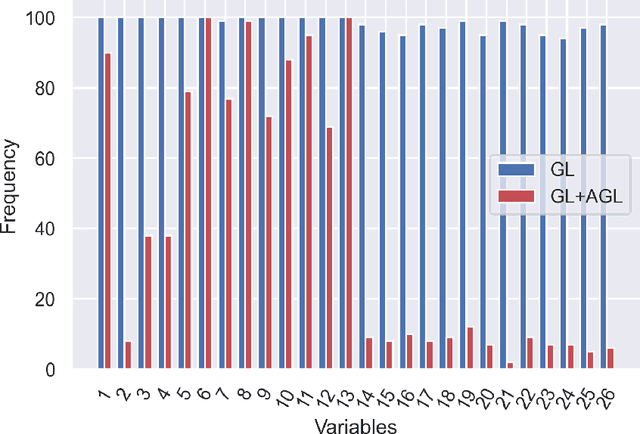
One main obstacle for the wide use of deep learning in medical and engineering sciences is its interpretability. While neural network models are strong tools for making predictions, they often provide little information about which features play significant roles in influencing the prediction accuracy. To overcome this issue, many regularization procedures for learning with neural networks have been proposed for dropping non-significant features. Unfortunately, the lack of theoretical results casts doubt on the applicability of such pipelines. In this work, we propose and establish a theoretical guarantee for the use of the adaptive group lasso for selecting important features of neural networks. Specifically, we show that our feature selection method is consistent for single-output feed-forward neural networks with one hidden layer and hyperbolic tangent activation function. We demonstrate its applicability using both simulation and data analysis.
Bayesian Active Learning With Abstention Feedbacks
Jun 04, 2019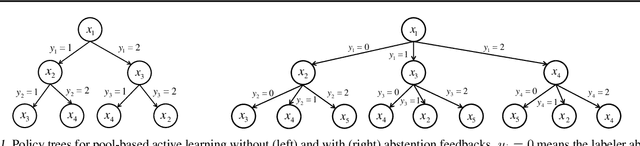
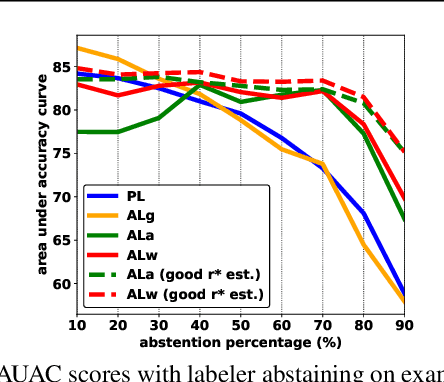
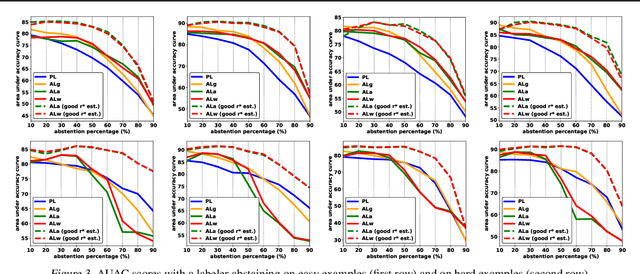
We study pool-based active learning with abstention feedbacks where a labeler can abstain from labeling a queried example with some unknown abstention rate. Using the Bayesian approach, we develop two new greedy algorithms that learn both the classification problem and the unknown abstention rate at the same time. These are achieved by incorporating the estimated average abstention rate into the greedy criteria. We prove that both algorithms have near-optimality guarantees: they respectively achieve a ${(1-\frac{1}{e})}$ constant factor approximation of the optimal expected or worst-case value of a useful utility function. Our experiments show the algorithms perform well in various practical scenarios.
Non-bifurcating phylogenetic tree inference via the adaptive LASSO
May 28, 2018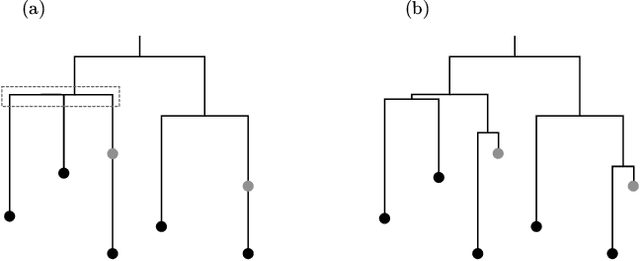
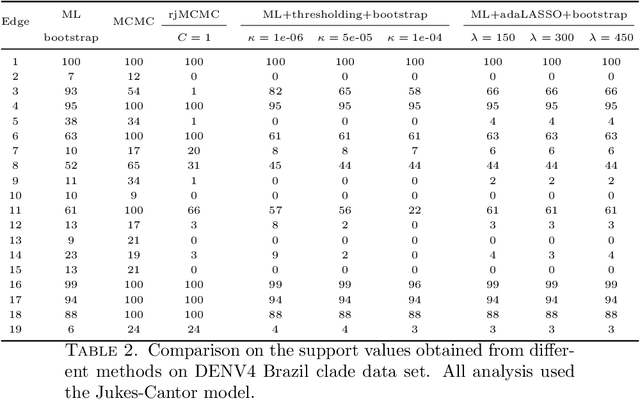
Phylogenetic tree inference using deep DNA sequencing is reshaping our understanding of rapidly evolving systems, such as the within-host battle between viruses and the immune system. Densely sampled phylogenetic trees can contain special features, including "sampled ancestors" in which we sequence a genotype along with its direct descendants, and "polytomies" in which multiple descendants arise simultaneously. These features are apparent after identifying zero-length branches in the tree. However, current maximum-likelihood based approaches are not capable of revealing such zero-length branches. In this paper, we find these zero-length branches by introducing adaptive-LASSO-type regularization estimators to phylogenetics, deriving their properties, and showing regularization to be a practically useful approach for phylogenetics.