 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Transformers with Spectrum-Preserving Token Merging
May 25, 2024
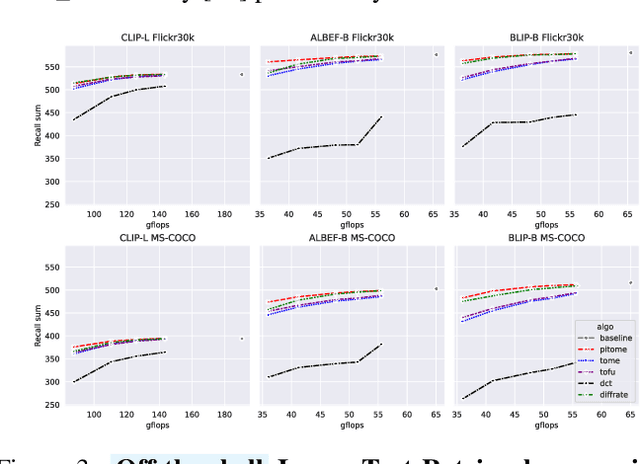
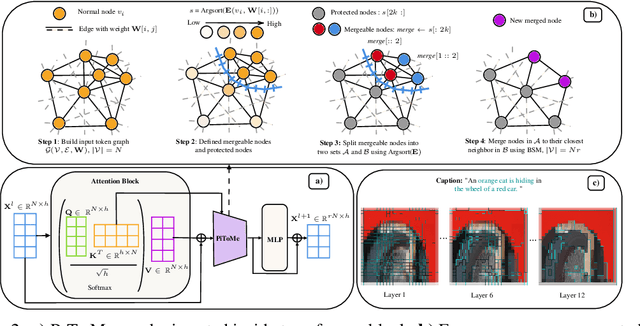
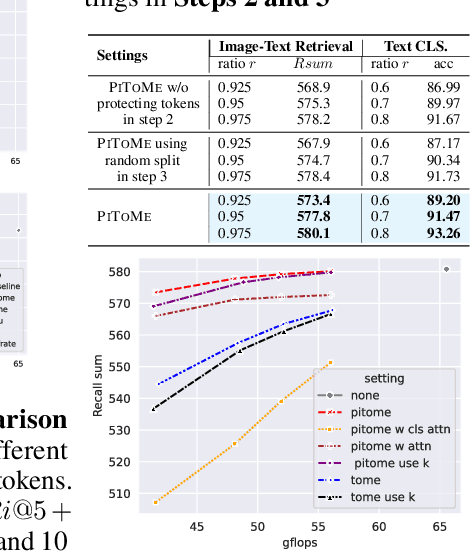
Increasing the throughput of the Transformer architecture, a foundational component used in numerous state-of-the-art models for vision and language tasks (e.g., GPT, LLaVa), is an important problem in machine learning. One recent and effective strategy is to merge token representations within Transformer models, aiming to reduce computational and memory requirements while maintaining accuracy. Prior works have proposed algorithms based on Bipartite Soft Matching (BSM), which divides tokens into distinct sets and merges the top k similar tokens. However, these methods have significant drawbacks, such as sensitivity to token-splitting strategies and damage to informative tokens in later layers. This paper presents a novel paradigm called PiToMe, which prioritizes the preservation of informative tokens using an additional metric termed the energy score. This score identifies large clusters of similar tokens as high-energy, indicating potential candidates for merging, while smaller (unique and isolated) clusters are considered as low-energy and preserved. Experimental findings demonstrate that PiToMe saved from 40-60\% FLOPs of the base models while exhibiting superior off-the-shelf performance on image classification (0.5\% average performance drop of ViT-MAE-H compared to 2.6\% as baselines), image-text retrieval (0.3\% average performance drop of CLIP on Flickr30k compared to 4.5\% as others), and analogously in visual questions answering with LLaVa-7B. Furthermore, PiToMe is theoretically shown to preserve intrinsic spectral properties of the original token space under mild conditions
OASIS: An Active Framework for Set Inversion
May 31, 2021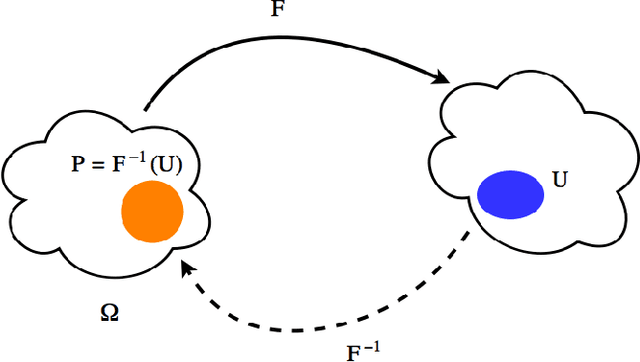
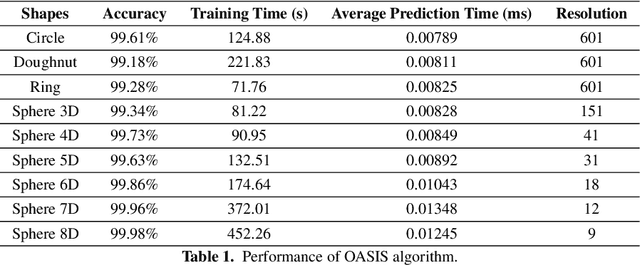
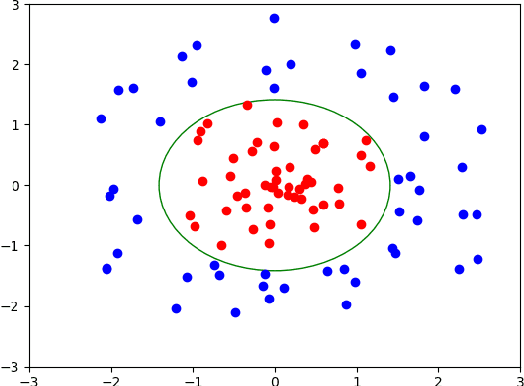
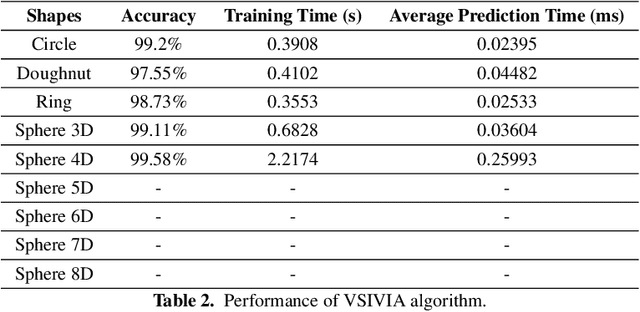
In this work, we introduce a novel method for solving the set inversion problem by formulating it as a binary classification problem. Aiming to develop a fast algorithm that can work effectively with high-dimensional and computationally expensive nonlinear models, we focus on active learning, a family of new and powerful techniques which can achieve the same level of accuracy with fewer data points compared to traditional learning methods. Specifically, we propose OASIS, an active learning framework using Support Vector Machine algorithms for solving the problem of set inversion. Our method works well in high dimensions and its computational cost is relatively robust to the increase of dimension. We illustrate the performance of OASIS by several simulation studies and show that our algorithm outperforms VISIA, the state-of-the-art method.
* 13 pages, 8 figures
Attention with Multiple Sources Knowledges for COVID-19 from CT Images
Sep 24, 2020
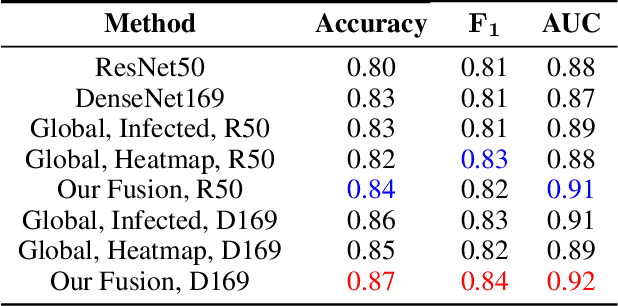

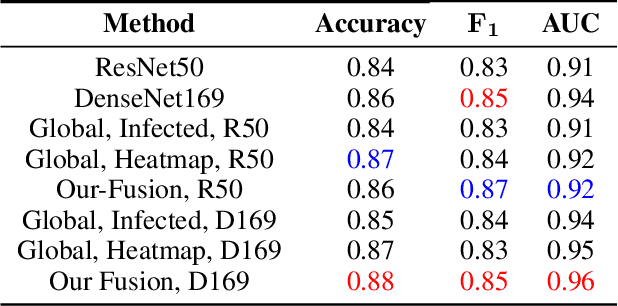
Until now, Coronavirus SARS-CoV-2 has caused more than 850,000 deaths and infected more than 27 million individuals in over 120 countries. Besides principal polymerase chain reaction (PCR) tests, automatically identifying positive samples based on computed tomography (CT) scans can present a promising option in the early diagnosis of COVID-19. Recently, there have been increasing efforts to utilize deep networks for COVID-19 diagnosis based on CT scans. While these approaches mostly focus on introducing novel architectures, transfer learning techniques, or construction large scale data, we propose a novel strategy to improve the performance of several baselines by leveraging multiple useful information sources relevant to doctors' judgments. Specifically, infected regions and heat maps extracted from learned networks are integrated with the global image via an attention mechanism during the learning process. This procedure not only makes our system more robust to noise but also guides the network focusing on local lesion areas. Extensive experiments illustrate the superior performance of our approach compared to recent baselines. Furthermore, our learned network guidance presents an explainable feature to doctors as we can understand the connection between input and output in a grey-box model.