Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterior concentration and fast convergence rates for generalized Bayesian learning
Paper and Code
Nov 19, 2021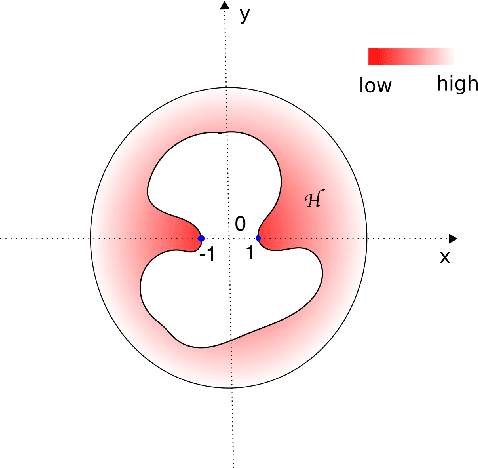
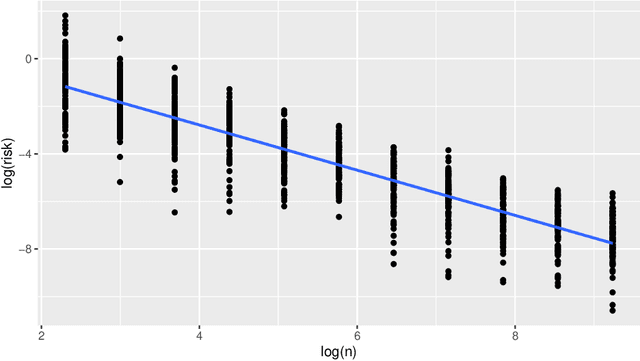
In this paper, we study the learning rate of generalized Bayes estimators in a general setting where the hypothesis class can be uncountable and have an irregular shape, the loss function can have heavy tails, and the optimal hypothesis may not be unique. We prove that under the multi-scale Bernstein's condition, the generalized posterior distribution concentrates around the set of optimal hypotheses and the generalized Bayes estimator can achieve fast learning rate. Our results are applied to show that the standard Bayesian linear regression is robust to heavy-tailed distributions.
View paper on