 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Unlearning in Diffusion Models
Mar 02, 2025Recent work has shown that diffusion models memorize and reproduce training data examples. At the same time, large copyright lawsuits and legislation such as GDPR have highlighted the need for erasing datapoints from diffusion models. However, retraining from scratch is often too expensive. This motivates the setting of data unlearning, i.e., the study of efficient techniques for unlearning specific datapoints from the training set. Existing concept unlearning techniques require an anchor prompt/class/distribution to guide unlearning, which is not available in the data unlearning setting. General-purpose machine unlearning techniques were found to be either unstable or failed to unlearn data. We therefore propose a family of new loss functions called Subtracted Importance Sampled Scores (SISS) that utilize importance sampling and are the first method to unlearn data with theoretical guarantees. SISS is constructed as a weighted combination between simpler objectives that are responsible for preserving model quality and unlearning the targeted datapoints. When evaluated on CelebA-HQ and MNIST, SISS achieved Pareto optimality along the quality and unlearning strength dimensions. On Stable Diffusion, SISS successfully mitigated memorization on nearly 90% of the prompts we tested.
Multi-Aspect Reviewed-Item Retrieval via LLM Query Decomposition and Aspect Fusion
Aug 01, 2024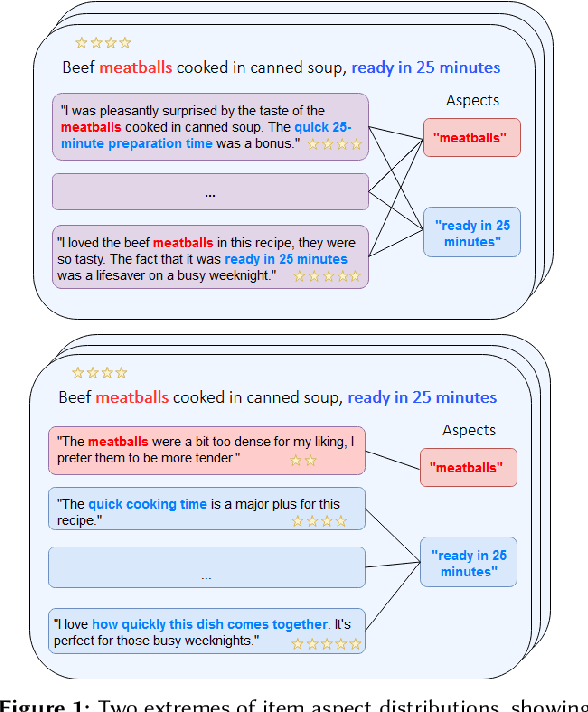
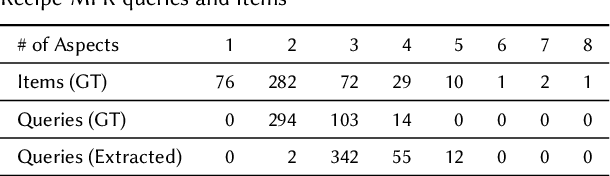
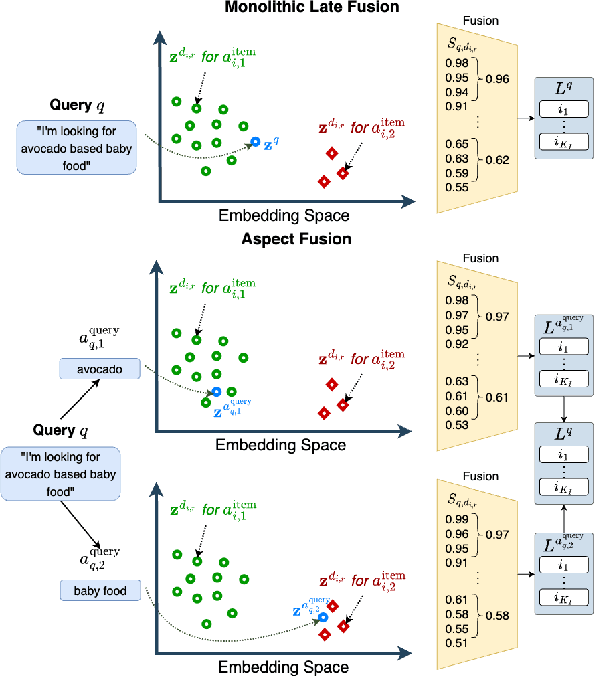
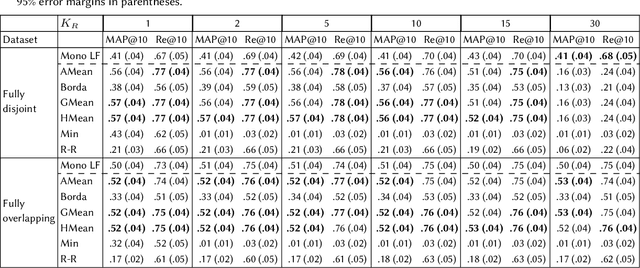
While user-generated product reviews often contain large quantities of information, their utility in addressing natural language product queries has been limited, with a key challenge being the need to aggregate information from multiple low-level sources (reviews) to a higher item level during retrieval. Existing methods for reviewed-item retrieval (RIR) typically take a late fusion (LF) approach which computes query-item scores by simply averaging the top-K query-review similarity scores for an item. However, we demonstrate that for multi-aspect queries and multi-aspect items, LF is highly sensitive to the distribution of aspects covered by reviews in terms of aspect frequency and the degree of aspect separation across reviews. To address these LF failures, we propose several novel aspect fusion (AF) strategies which include Large Language Model (LLM) query extraction and generative reranking. Our experiments show that for imbalanced review corpora, AF can improve over LF by a MAP@10 increase from 0.36 to 0.52, while achieving equivalent performance for balanced review corpora.
What's the Magic Word? A Control Theory of LLM Prompting
Oct 10, 2023Prompt engineering is effective and important in the deployment of LLMs but is poorly understood mathematically. Here, we formalize prompt engineering as an optimal control problem on LLMs -- where the prompt is considered a control variable for modulating the output distribution of the LLM. Within this framework, we ask a simple question: given a sequence of tokens, does there always exist a prompt we can prepend that will steer the LLM toward accurately predicting the final token? We call such an optimal prompt the magic word since prepending the prompt causes the LLM to output the correct answer. If magic words exist, can we find them? If so, what are their properties? We offer analytic analysis on the controllability of the self-attention head where we prove a bound on controllability as a function of the singular values of its weight matrices. We take inspiration from control theory to propose a metric called $k-\epsilon$ controllability to characterize LLM steerability. We compute the $k-\epsilon$ controllability of a panel of large language models, including Falcon-7b, Llama-7b, and Falcon-40b on 5000 WikiText causal language modeling tasks. Remarkably, we find that magic words of 10 tokens or less exist for over 97% of WikiText instances surveyed for each model.