 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Saving LLM Cascades with Early Abstention
Feb 13, 2025



LLM cascades are based on the idea that processing all queries with the largest and most expensive LLMs is inefficient. Instead, cascades deploy small LLMs to answer the majority of queries, limiting the use of large and expensive LLMs to only the most difficult queries. This approach can significantly reduce costs without impacting performance. However, risk-sensitive domains such as finance or medicine place an additional premium on avoiding model errors. Recognizing that even the most expensive models may make mistakes, applications in these domains benefit from allowing LLM systems to completely abstain from answering a query when the chance of making a mistake is significant. However, giving a cascade the ability to abstain poses an immediate design question for LLM cascades: should abstention only be allowed at the final model or also at earlier models? Since the error patterns of small and large models are correlated, the latter strategy may further reduce inference costs by letting inexpensive models anticipate abstention decisions by expensive models, thereby obviating the need to run the expensive models. We investigate the benefits of "early abstention" in LLM cascades and find that it reduces the overall test loss by 2.2% on average across six benchmarks (GSM8K, MedMCQA, MMLU, TriviaQA, TruthfulQA, and XSum). These gains result from a more effective use of abstention, which trades a 4.1% average increase in the overall abstention rate for a 13.0% reduction in cost and a 5.0% reduction in error rate. Our findings demonstrate that it is possible to leverage correlations between the error patterns of different language models to drive performance improvements for LLM systems with abstention.
Rational Tuning of LLM Cascades via Probabilistic Modeling
Jan 16, 2025Understanding the reliability of large language models (LLMs) has recently garnered significant attention. Given LLMs' propensity to hallucinate, as well as their high sensitivity to prompt design, it is already challenging to predict the performance of an individual LLM. However, the problem becomes more complex for compound LLM systems such as cascades, where in addition to each model's standalone performance, we must understand how the error rates of different models interact. In this paper, we present a probabilistic model for the joint performance distribution of a sequence of LLMs, which enables a framework for rationally tuning the confidence thresholds of a LLM cascade using continuous optimization. Compared to selecting confidence thresholds using grid search, our parametric Markov-copula model significantly improves runtime scaling with respect to the length of the cascade and the desired resolution of the cost-error curve, turning them from intractable into low-order polynomial. In addition, the optimal thresholds computed using our continuous optimization-based algorithm increasingly outperform those found via grid search as cascade length grows, improving the area under the cost-error curve by 1.9% on average for cascades consisting of at least three models. Overall, our Markov-copula model provides a rational basis for tuning LLM cascade performance and points to the potential of probabilistic methods in analyzing LLM systems.
Efficiently Deploying LLMs with Controlled Risk
Oct 03, 2024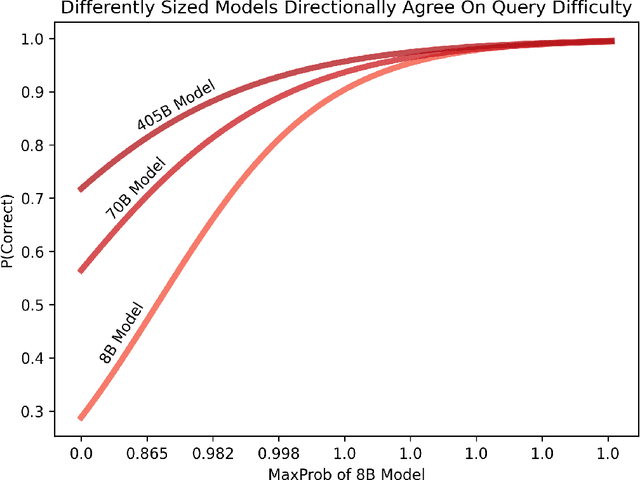
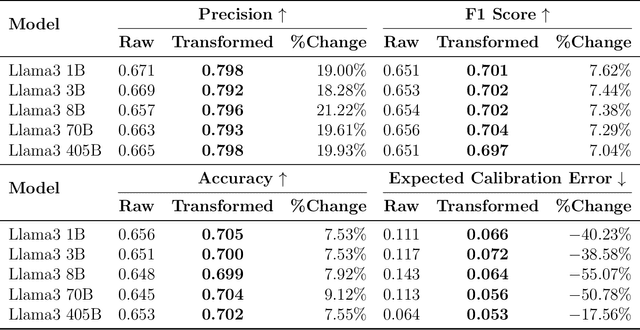
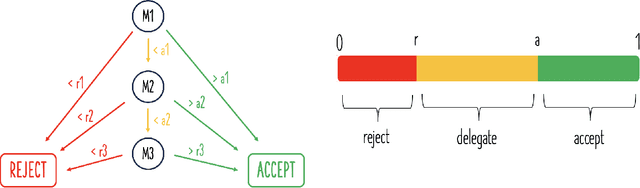
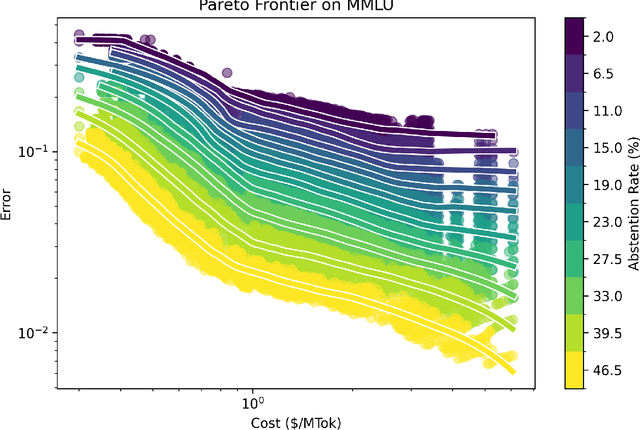
Deploying large language models in production requires simultaneous attention to efficiency and risk control. Prior work has shown the possibility to cut costs while maintaining similar accuracy, but has neglected to focus on risk control. By contrast, here we present hierarchical chains with multi-level abstention (HCMA), which use model-intrinsic uncertainty to delegate queries along the LLM intelligence hierarchy, enabling training-free model switching based solely on black-box API calls. Our framework presents novel trade-offs between efficiency and risk. For example, deploying HCMA on MMLU cuts the error rate of Llama3 405B by 30% when the model is allowed to abstain on 20% of the queries. To calibrate HCMA for optimal performance, our approach uses data-efficient logistic regressions (based on a simple nonlinear feature transformation), which require only 50 or 100 labeled examples to achieve excellent calibration error (ECE), cutting ECE by 50% compared to naive Platt scaling. On free-form generation tasks, we find that chain-of-thought is ineffectual for selective prediction, whereas zero-shot prompting drives error to 0% on TruthfulQA at high abstention rates. As LLMs are increasingly deployed across computing environments with different capabilities (such as mobile, laptop, and cloud), our framework paves the way towards maintaining deployment efficiency while putting in place sharp risk controls.
Leveraging Open-Source Large Language Models for encoding Social Determinants of Health using an Intelligent Router
May 30, 2024



Social Determinants of Health (SDOH) play a significant role in patient health outcomes. The Center of Disease Control (CDC) introduced a subset of ICD-10 codes called Z-codes in an attempt to officially recognize and measure SDOH in the health care system. However, these codes are rarely annotated in a patient's Electronic Health Record (EHR), and instead, in many cases, need to be inferred from clinical notes. Previous research has shown that large language models (LLMs) show promise on extracting unstructured data from EHRs. However, with thousands of models to choose from with unique architectures and training sets, it's difficult to choose one model that performs the best on coding tasks. Further, clinical notes contain trusted health information making the use of closed-source language models from commercial vendors difficult, so the identification of open source LLMs that can be run within health organizations and exhibits high performance on SDOH tasks is an urgent problem. Here, we introduce an intelligent routing system for SDOH coding that uses a language model router to direct medical record data to open source LLMs that demonstrate optimal performance on specific SDOH codes. The intelligent routing system exhibits state of the art performance of 97.4% accuracy averaged across 5 codes, including homelessness and food insecurity, on par with closed models such as GPT-4o. In order to train the routing system and validate models, we also introduce a synthetic data generation and validation paradigm to increase the scale of training data without needing privacy protected medical records. Together, we demonstrate an architecture for intelligent routing of inputs to task-optimal language models to achieve high performance across a set of medical coding sub-tasks.
Herd: Using multiple, smaller LLMs to match the performances of proprietary, large LLMs via an intelligent composer
Oct 30, 2023Currently, over a thousand LLMs exist that are multi-purpose and are capable of performing real world tasks, including Q&A, text summarization, content generation, etc. However, accessibility, scale and reliability of free models prevents them from being widely deployed in everyday use cases. To address the first two issues of access and scale, organisations such as HuggingFace have created model repositories where users have uploaded model weights and quantized versions of models trained using different paradigms, as well as model cards describing their training process. While some models report performance on commonly used benchmarks, not all do, and interpreting the real world impact of trading off performance on a benchmark for model deployment cost, is unclear. Here, we show that a herd of open source models can match or exceed the performance of proprietary models via an intelligent router. We show that a Herd of open source models is able to match the accuracy of ChatGPT, despite being composed of models that are effectively 2.5x smaller. We show that in cases where GPT is not able to answer the query, Herd is able to identify a model that can, at least 40% of the time.
What's the Magic Word? A Control Theory of LLM Prompting
Oct 10, 2023Prompt engineering is effective and important in the deployment of LLMs but is poorly understood mathematically. Here, we formalize prompt engineering as an optimal control problem on LLMs -- where the prompt is considered a control variable for modulating the output distribution of the LLM. Within this framework, we ask a simple question: given a sequence of tokens, does there always exist a prompt we can prepend that will steer the LLM toward accurately predicting the final token? We call such an optimal prompt the magic word since prepending the prompt causes the LLM to output the correct answer. If magic words exist, can we find them? If so, what are their properties? We offer analytic analysis on the controllability of the self-attention head where we prove a bound on controllability as a function of the singular values of its weight matrices. We take inspiration from control theory to propose a metric called $k-\epsilon$ controllability to characterize LLM steerability. We compute the $k-\epsilon$ controllability of a panel of large language models, including Falcon-7b, Llama-7b, and Falcon-40b on 5000 WikiText causal language modeling tasks. Remarkably, we find that magic words of 10 tokens or less exist for over 97% of WikiText instances surveyed for each model.
Tryage: Real-time, intelligent Routing of User Prompts to Large Language Models
Aug 23, 2023The introduction of the transformer architecture and the self-attention mechanism has led to an explosive production of language models trained on specific downstream tasks and data domains. With over 200, 000 models in the Hugging Face ecosystem, users grapple with selecting and optimizing models to suit multifaceted workflows and data domains while addressing computational, security, and recency concerns. There is an urgent need for machine learning frameworks that can eliminate the burden of model selection and customization and unleash the incredible power of the vast emerging model library for end users. Here, we propose a context-aware routing system, Tryage, that leverages a language model router for optimal selection of expert models from a model library based on analysis of individual input prompts. Inspired by the thalamic router in the brain, Tryage employs a perceptive router to predict down-stream model performance on prompts and, then, makes a routing decision using an objective function that integrates performance predictions with user goals and constraints that are incorporated through flags (e.g., model size, model recency). Tryage allows users to explore a Pareto front and automatically trade-off between task accuracy and secondary goals including minimization of model size, recency, security, verbosity, and readability. Across heterogeneous data sets that include code, text, clinical data, and patents, the Tryage framework surpasses Gorilla and GPT3.5 turbo in dynamic model selection identifying the optimal model with an accuracy of 50.9% , compared to 23.6% by GPT 3.5 Turbo and 10.8% by Gorilla. Conceptually, Tryage demonstrates how routing models can be applied to program and control the behavior of multi-model LLM systems to maximize efficient use of the expanding and evolving language model ecosystem.
Generating counterfactual explanations of tumor spatial proteomes to discover effective, combinatorial therapies that enhance cancer immunotherapy
Nov 08, 2022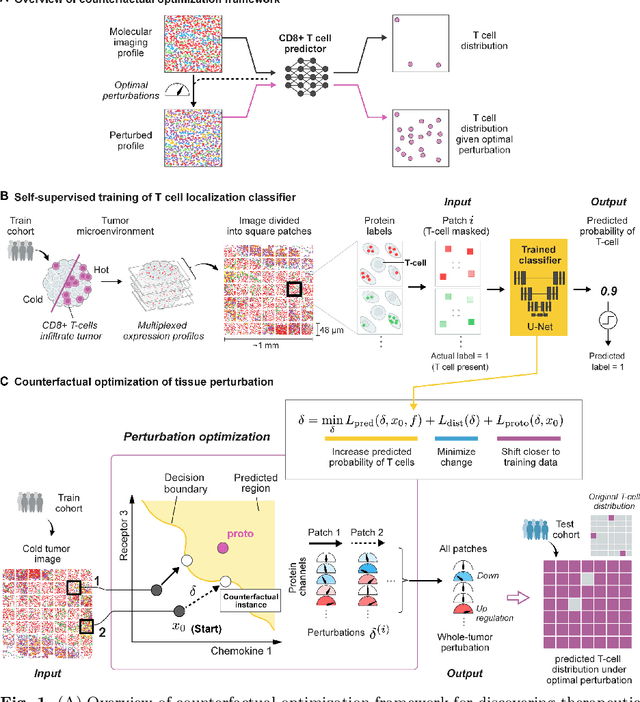

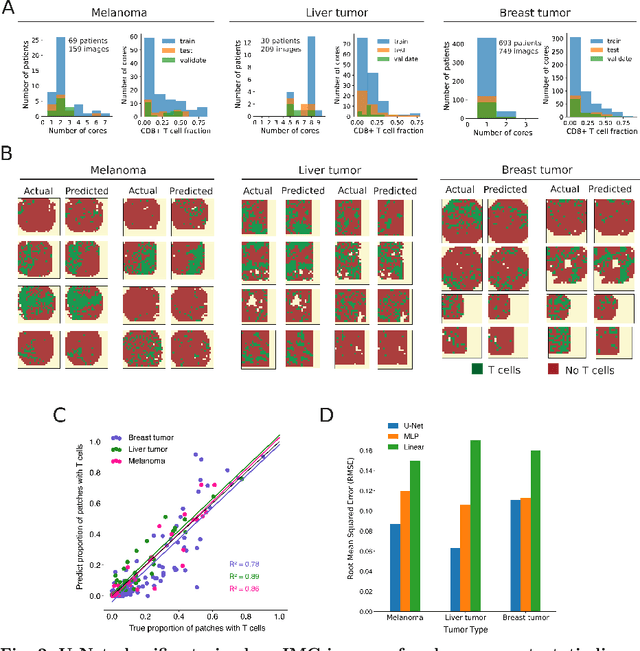

Recent advances in spatial omics methods enable the molecular composition of human tumors to be imaged at micron-scale resolution across hundreds of patients and ten to thousands of molecular imaging channels. Large-scale molecular imaging datasets offer a new opportunity to understand how the spatial organization of proteins and cell types within a tumor modulate the response of a patient to different therapeutic strategies and offer potential insights into the design of novel therapies to increase patient response. However, spatial omics datasets require computational analysis methods that can scale to incorporate hundreds to thousands of imaging channels (ie colors) while enabling the extraction of molecular patterns that correlate with treatment responses across large number of patients with potentially heterogeneous tumors presentations. Here, we have develop a machine learning strategy for the identification and design of signaling molecule combinations that predict the degree of immune system engagement with a specific patient tumors. We specifically train a classifier to predict T cell distribution in patient tumors using the images from 30-40 molecular imaging channels. Second, we apply a gradient descent based counterfactual reasoning strategy to the classifier and discover combinations of signaling molecules predicted to increase T cell infiltration. Applied to spatial proteomics data of melanoma tumor, our model predicts that increasing the level of CXCL9, CXCL10, CXCL12, CCL19 and decreasing the level of CCL8 in melanoma tumor will increase T cell infiltration by 10-fold across a cohort of 69 patients. The model predicts that the combination is many fold more effective than single target perturbations. Our work provides a paradigm for machine learning based prediction and design of cancer therapeutics based on classification of immune system activity in spatial omics data.
Engineering flexible machine learning systems by traversing functionally invariant paths in weight space
May 09, 2022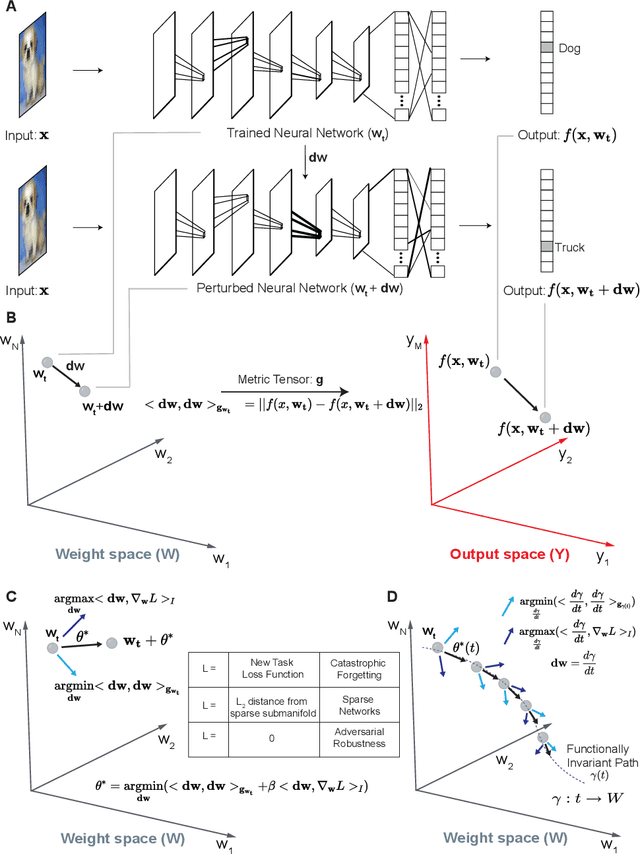
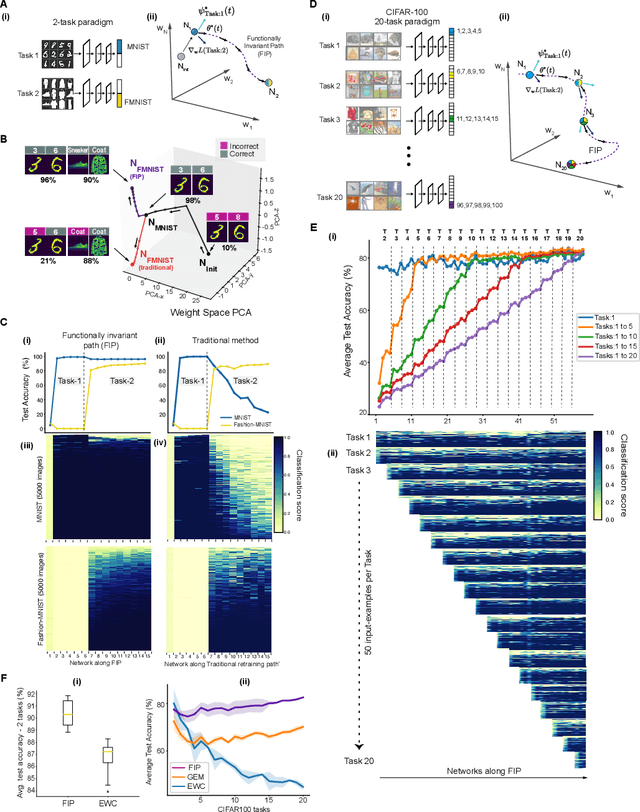
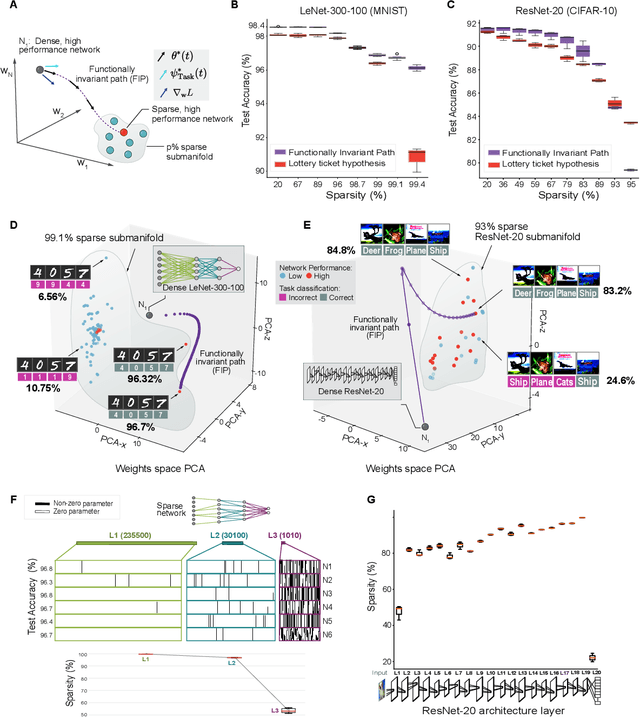
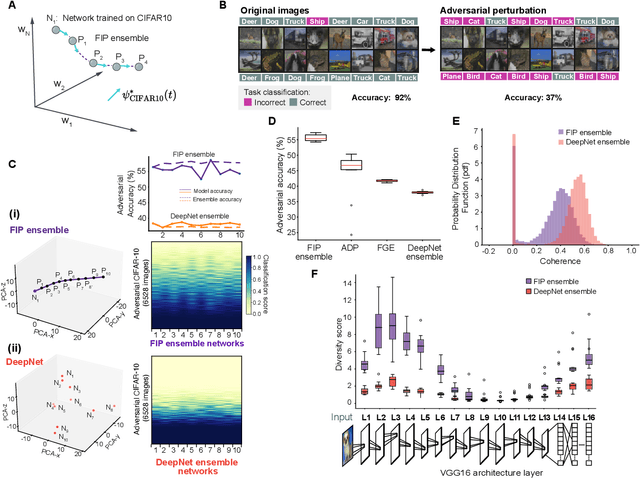
Deep neural networks achieve human-like performance on a variety of perceptual and decision making tasks. However, deep networks perform poorly when confronted with changing tasks or goals, and broadly fail to match the flexibility and robustness of human intelligence. Here, we develop a mathematical and algorithmic framework that enables continual training of deep neural networks on a broad range of objectives by defining path connected sets of neural networks that achieve equivalent functional performance on a given machine learning task while modulating network weights to achieve high-performance on a secondary objective. We view the weight space of a neural network as a curved Riemannian manifold and move a neural network along a functionally invariant path in weight space while searching for networks that satisfy a secondary objective. We introduce a path-sampling algorithm that trains networks with millions of weight parameters to learn a series of image classification tasks without performance loss. The algorithm generalizes to accommodate a range of secondary objectives including weight-pruning and weight diversification and exhibits state of the art performance on network compression and adversarial robustness benchmarks. Broadly, we demonstrate how the intrinsic geometry of machine learning problems can be harnessed to construct flexible and robust neural networks.
Active feature selection discovers minimal gene-sets for classifying cell-types and disease states in single-cell mRNA-seq data
Jun 15, 2021Sequencing costs currently prohibit the application of single cell mRNA-seq for many biological and clinical tasks of interest. Here, we introduce an active learning framework that constructs compressed gene sets that enable high accuracy classification of cell-types and physiological states while analyzing a minimal number of gene transcripts. Our active feature selection procedure constructs gene sets through an iterative cell-type classification task where misclassified cells are examined at each round to identify maximally informative genes through an `active' support vector machine (SVM) classifier. Our active SVM procedure automatically identifies gene sets that enables $>90\%$ cell-type classification accuracy in the Tabula Muris mouse tissue survey as well as a $\sim 40$ gene set that enables classification of multiple myeloma patient samples with $>95\%$ accuracy. Broadly, the discovery of compact but highly informative gene sets might enable drastic reductions in sequencing requirements for applications of single-cell mRNA-seq.