 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Deploying LLMs with Controlled Risk
Paper and Code
Oct 03, 2024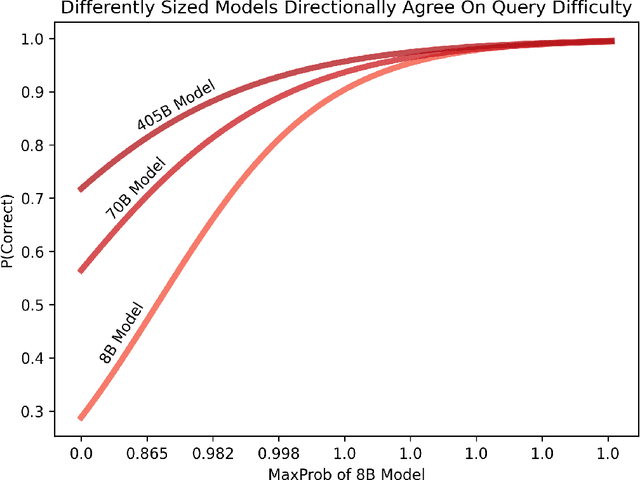
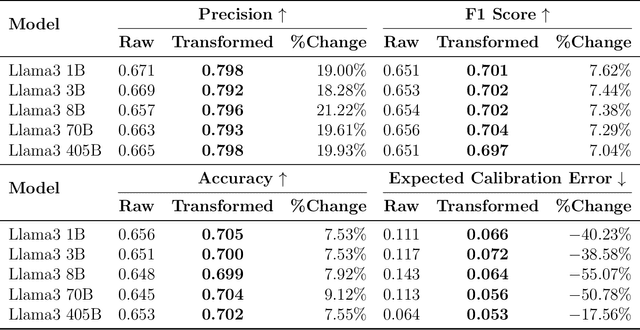
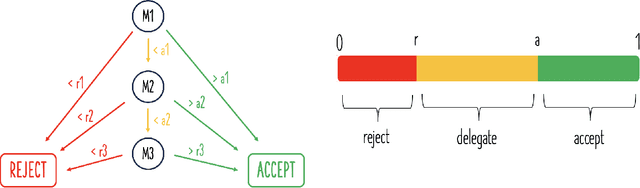
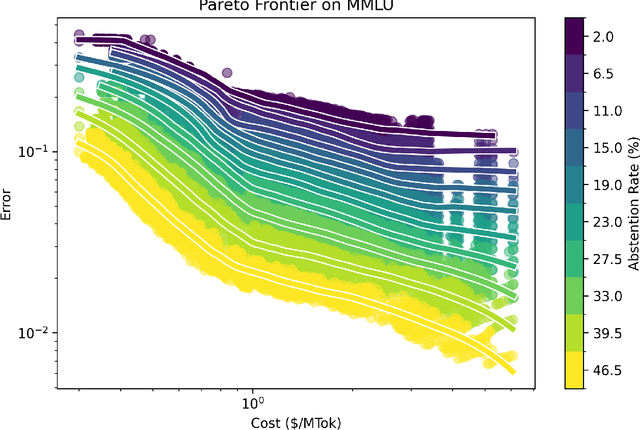
Deploying large language models in production requires simultaneous attention to efficiency and risk control. Prior work has shown the possibility to cut costs while maintaining similar accuracy, but has neglected to focus on risk control. By contrast, here we present hierarchical chains with multi-level abstention (HCMA), which use model-intrinsic uncertainty to delegate queries along the LLM intelligence hierarchy, enabling training-free model switching based solely on black-box API calls. Our framework presents novel trade-offs between efficiency and risk. For example, deploying HCMA on MMLU cuts the error rate of Llama3 405B by 30% when the model is allowed to abstain on 20% of the queries. To calibrate HCMA for optimal performance, our approach uses data-efficient logistic regressions (based on a simple nonlinear feature transformation), which require only 50 or 100 labeled examples to achieve excellent calibration error (ECE), cutting ECE by 50% compared to naive Platt scaling. On free-form generation tasks, we find that chain-of-thought is ineffectual for selective prediction, whereas zero-shot prompting drives error to 0% on TruthfulQA at high abstention rates. As LLMs are increasingly deployed across computing environments with different capabilities (such as mobile, laptop, and cloud), our framework paves the way towards maintaining deployment efficiency while putting in place sharp risk controls.