 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Saving LLM Cascades with Early Abstention
Feb 13, 2025



LLM cascades are based on the idea that processing all queries with the largest and most expensive LLMs is inefficient. Instead, cascades deploy small LLMs to answer the majority of queries, limiting the use of large and expensive LLMs to only the most difficult queries. This approach can significantly reduce costs without impacting performance. However, risk-sensitive domains such as finance or medicine place an additional premium on avoiding model errors. Recognizing that even the most expensive models may make mistakes, applications in these domains benefit from allowing LLM systems to completely abstain from answering a query when the chance of making a mistake is significant. However, giving a cascade the ability to abstain poses an immediate design question for LLM cascades: should abstention only be allowed at the final model or also at earlier models? Since the error patterns of small and large models are correlated, the latter strategy may further reduce inference costs by letting inexpensive models anticipate abstention decisions by expensive models, thereby obviating the need to run the expensive models. We investigate the benefits of "early abstention" in LLM cascades and find that it reduces the overall test loss by 2.2% on average across six benchmarks (GSM8K, MedMCQA, MMLU, TriviaQA, TruthfulQA, and XSum). These gains result from a more effective use of abstention, which trades a 4.1% average increase in the overall abstention rate for a 13.0% reduction in cost and a 5.0% reduction in error rate. Our findings demonstrate that it is possible to leverage correlations between the error patterns of different language models to drive performance improvements for LLM systems with abstention.
Rational Tuning of LLM Cascades via Probabilistic Modeling
Jan 16, 2025Understanding the reliability of large language models (LLMs) has recently garnered significant attention. Given LLMs' propensity to hallucinate, as well as their high sensitivity to prompt design, it is already challenging to predict the performance of an individual LLM. However, the problem becomes more complex for compound LLM systems such as cascades, where in addition to each model's standalone performance, we must understand how the error rates of different models interact. In this paper, we present a probabilistic model for the joint performance distribution of a sequence of LLMs, which enables a framework for rationally tuning the confidence thresholds of a LLM cascade using continuous optimization. Compared to selecting confidence thresholds using grid search, our parametric Markov-copula model significantly improves runtime scaling with respect to the length of the cascade and the desired resolution of the cost-error curve, turning them from intractable into low-order polynomial. In addition, the optimal thresholds computed using our continuous optimization-based algorithm increasingly outperform those found via grid search as cascade length grows, improving the area under the cost-error curve by 1.9% on average for cascades consisting of at least three models. Overall, our Markov-copula model provides a rational basis for tuning LLM cascade performance and points to the potential of probabilistic methods in analyzing LLM systems.
Efficiently Deploying LLMs with Controlled Risk
Oct 03, 2024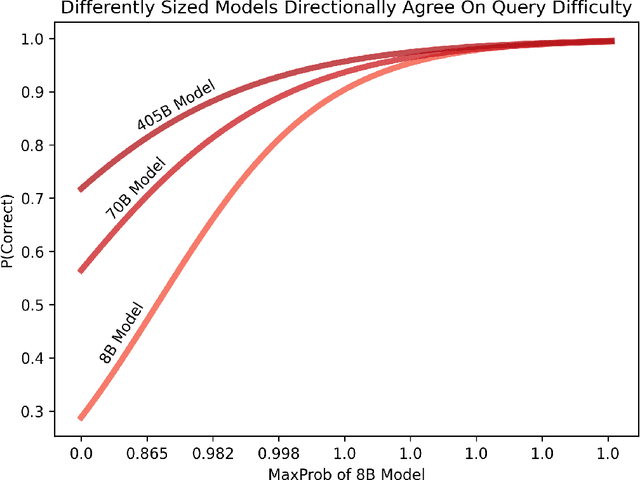
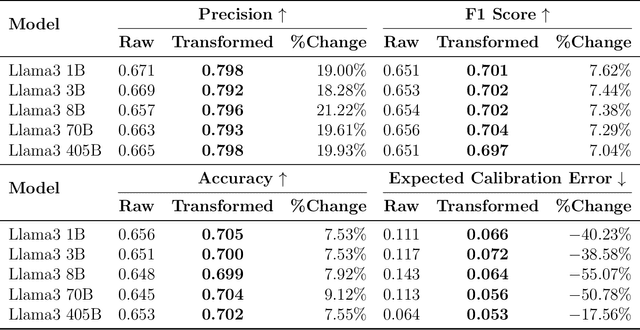
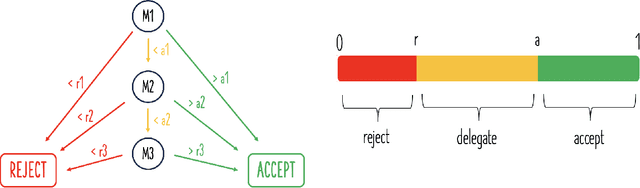
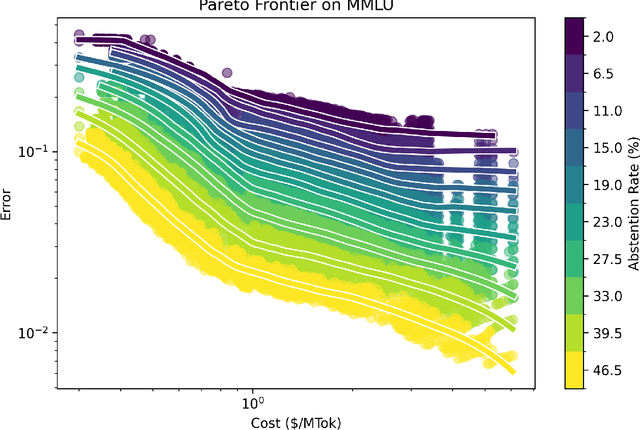
Deploying large language models in production requires simultaneous attention to efficiency and risk control. Prior work has shown the possibility to cut costs while maintaining similar accuracy, but has neglected to focus on risk control. By contrast, here we present hierarchical chains with multi-level abstention (HCMA), which use model-intrinsic uncertainty to delegate queries along the LLM intelligence hierarchy, enabling training-free model switching based solely on black-box API calls. Our framework presents novel trade-offs between efficiency and risk. For example, deploying HCMA on MMLU cuts the error rate of Llama3 405B by 30% when the model is allowed to abstain on 20% of the queries. To calibrate HCMA for optimal performance, our approach uses data-efficient logistic regressions (based on a simple nonlinear feature transformation), which require only 50 or 100 labeled examples to achieve excellent calibration error (ECE), cutting ECE by 50% compared to naive Platt scaling. On free-form generation tasks, we find that chain-of-thought is ineffectual for selective prediction, whereas zero-shot prompting drives error to 0% on TruthfulQA at high abstention rates. As LLMs are increasingly deployed across computing environments with different capabilities (such as mobile, laptop, and cloud), our framework paves the way towards maintaining deployment efficiency while putting in place sharp risk controls.
repliclust: Synthetic Data for Cluster Analysis
Mar 24, 2023We present repliclust (from repli-cate and clust-er), a Python package for generating synthetic data sets with clusters. Our approach is based on data set archetypes, high-level geometric descriptions from which the user can create many different data sets, each possessing the desired geometric characteristics. The architecture of our software is modular and object-oriented, decomposing data generation into algorithms for placing cluster centers, sampling cluster shapes, selecting the number of data points for each cluster, and assigning probability distributions to clusters. The project webpage, repliclust.org, provides a concise user guide and thorough documentation.