 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Saving LLM Cascades with Early Abstention
Feb 13, 2025



LLM cascades are based on the idea that processing all queries with the largest and most expensive LLMs is inefficient. Instead, cascades deploy small LLMs to answer the majority of queries, limiting the use of large and expensive LLMs to only the most difficult queries. This approach can significantly reduce costs without impacting performance. However, risk-sensitive domains such as finance or medicine place an additional premium on avoiding model errors. Recognizing that even the most expensive models may make mistakes, applications in these domains benefit from allowing LLM systems to completely abstain from answering a query when the chance of making a mistake is significant. However, giving a cascade the ability to abstain poses an immediate design question for LLM cascades: should abstention only be allowed at the final model or also at earlier models? Since the error patterns of small and large models are correlated, the latter strategy may further reduce inference costs by letting inexpensive models anticipate abstention decisions by expensive models, thereby obviating the need to run the expensive models. We investigate the benefits of "early abstention" in LLM cascades and find that it reduces the overall test loss by 2.2% on average across six benchmarks (GSM8K, MedMCQA, MMLU, TriviaQA, TruthfulQA, and XSum). These gains result from a more effective use of abstention, which trades a 4.1% average increase in the overall abstention rate for a 13.0% reduction in cost and a 5.0% reduction in error rate. Our findings demonstrate that it is possible to leverage correlations between the error patterns of different language models to drive performance improvements for LLM systems with abstention.
MU-MAE: Multimodal Masked Autoencoders-Based One-Shot Learning
Aug 08, 2024



With the exponential growth of multimedia data, leveraging multimodal sensors presents a promising approach for improving accuracy in human activity recognition. Nevertheless, accurately identifying these activities using both video data and wearable sensor data presents challenges due to the labor-intensive data annotation, and reliance on external pretrained models or additional data. To address these challenges, we introduce Multimodal Masked Autoencoders-Based One-Shot Learning (Mu-MAE). Mu-MAE integrates a multimodal masked autoencoder with a synchronized masking strategy tailored for wearable sensors. This masking strategy compels the networks to capture more meaningful spatiotemporal features, which enables effective self-supervised pretraining without the need for external data. Furthermore, Mu-MAE leverages the representation extracted from multimodal masked autoencoders as prior information input to a cross-attention multimodal fusion layer. This fusion layer emphasizes spatiotemporal features requiring attention across different modalities while highlighting differences from other classes, aiding in the classification of various classes in metric-based one-shot learning. Comprehensive evaluations on MMAct one-shot classification show that Mu-MAE outperforms all the evaluated approaches, achieving up to an 80.17% accuracy for five-way one-shot multimodal classification, without the use of additional data.
STAF: A Spatio-Temporal Attention Fusion Network for Few-shot Video Classification
Dec 08, 2021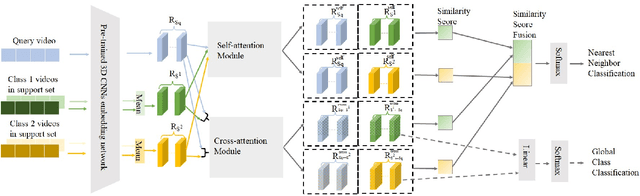
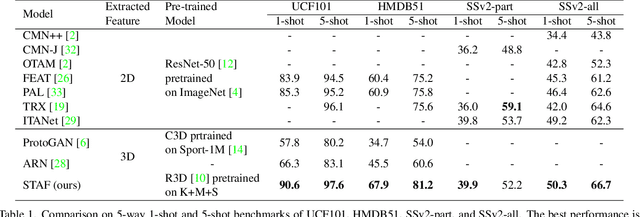
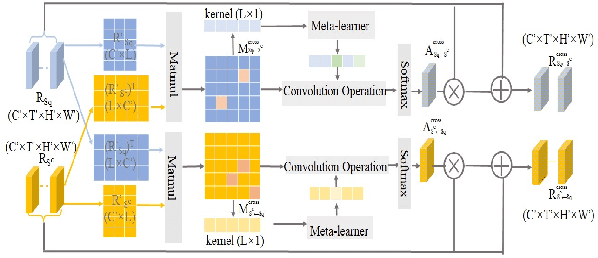
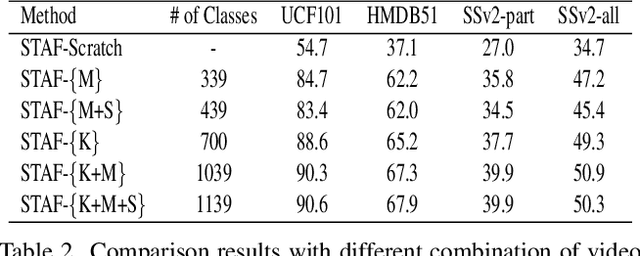
We propose STAF, a Spatio-Temporal Attention Fusion network for few-shot video classification. STAF first extracts coarse-grained spatial and temporal features of videos by applying a 3D Convolution Neural Networks embedding network. It then fine-tunes the extracted features using self-attention and cross-attention networks. Last, STAF applies a lightweight fusion network and a nearest neighbor classifier to classify each query video. To evaluate STAF, we conduct extensive experiments on three benchmarks (UCF101, HMDB51, and Something-Something-V2). The experimental results show that STAF improves state-of-the-art accuracy by a large margin, e.g., STAF increases the five-way one-shot accuracy by 5.3% and 7.0% for UCF101 and HMDB51, respectively.
Early Mobility Recognition for Intensive Care Unit Patients Using Accelerometers
Jun 28, 2021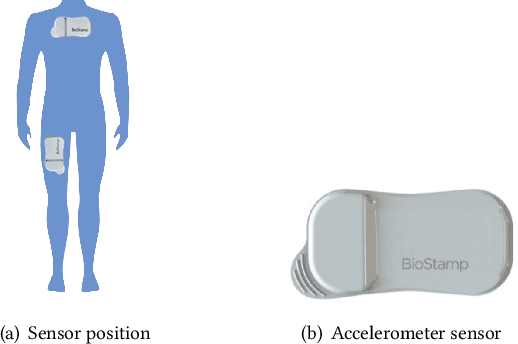
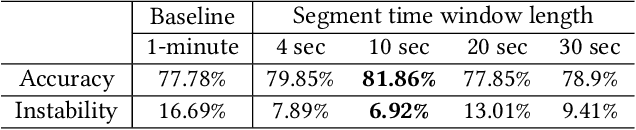
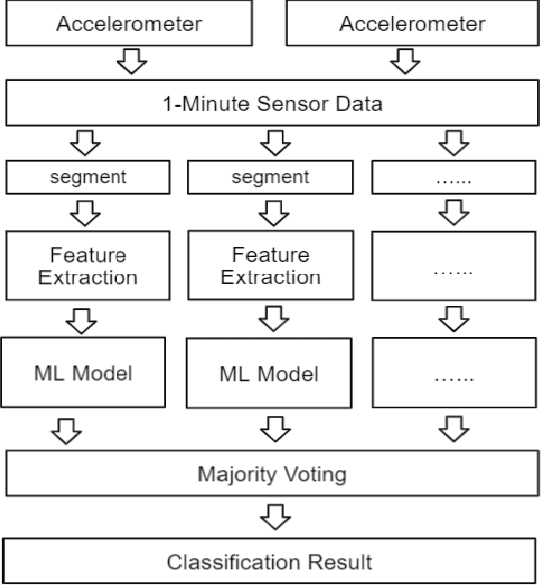

With the development of the Internet of Things(IoT) and Artificial Intelligence(AI) technologies, human activity recognition has enabled various applications, such as smart homes and assisted living. In this paper, we target a new healthcare application of human activity recognition, early mobility recognition for Intensive Care Unit(ICU) patients. Early mobility is essential for ICU patients who suffer from long-time immobilization. Our system includes accelerometer-based data collection from ICU patients and an AI model to recognize patients' early mobility. To improve the model accuracy and stability, we identify features that are insensitive to sensor orientations and propose a segment voting process that leverages a majority voting strategy to recognize each segment's activity. Our results show that our system improves model accuracy from 77.78\% to 81.86\% and reduces the model instability (standard deviation) from 16.69\% to 6.92\%, compared to the same AI model without our feature engineering and segment voting process.
Gait Characterization in Duchenne Muscular Dystrophy (DMD) Using a Single-Sensor Accelerometer: Classical Machine Learning and Deep Learning Approaches
May 12, 2021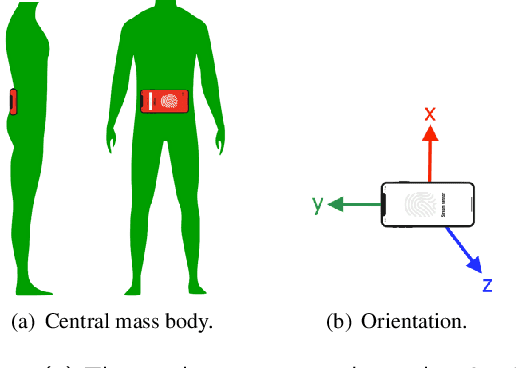
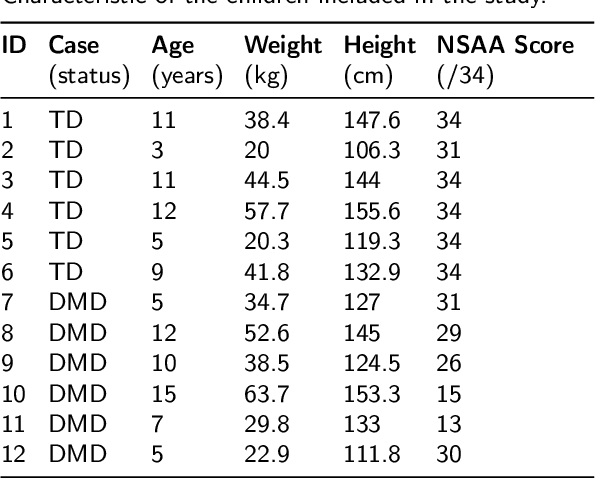

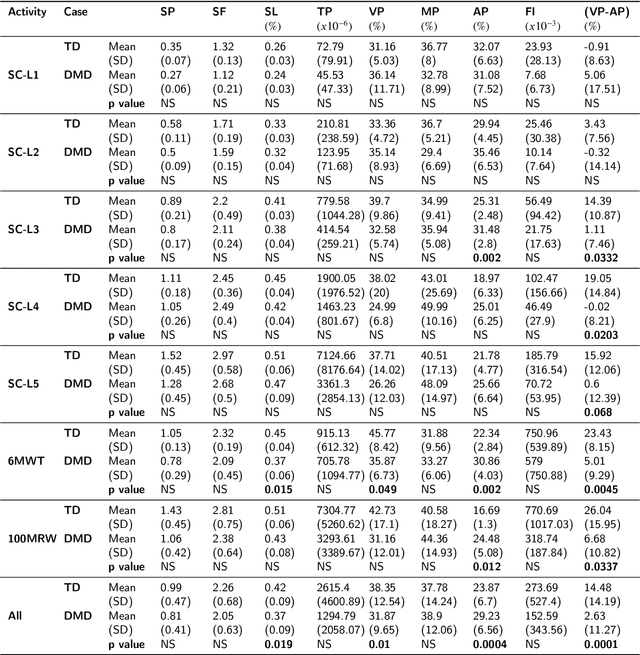
Differences in gait patterns of children with Duchenne muscular dystrophy (DMD) and typically developing (TD) peers are visible to the eye, but quantification of those differences outside of the gait laboratory has been elusive. We measured vertical, mediolateral, and anteroposterior acceleration using a waist-worn iPhone accelerometer during ambulation across a typical range of velocities. Six TD and six DMD children from 3-15 years of age underwent seven walking/running tasks, including five 25m walk/run tests at a slow walk to running speeds, a 6-minute walk test (6MWT), and a 100-meter-run/walk (100MRW). We extracted temporospatial clinical gait features (CFs) and applied multiple Artificial Intelligence (AI) tools to differentiate between DMD and TD control children using extracted features and raw data. Extracted CFs showed reduced step length and a greater mediolateral component of total power (TP) consistent with shorter strides and Trendelenberg-like gait commonly observed in DMD. AI methods using CFs and raw data varied ineffectiveness at differentiating between DMD and TD controls at different speeds, with an accuracy of some methods exceeding 91%. We demonstrate that by using AI tools with accelerometer data from a consumer-level smartphone, we can identify DMD gait disturbance in toddlers to early teens.
An Overview of Human Activity Recognition Using Wearable Sensors: Healthcare and Artificial Intelligence
Mar 29, 2021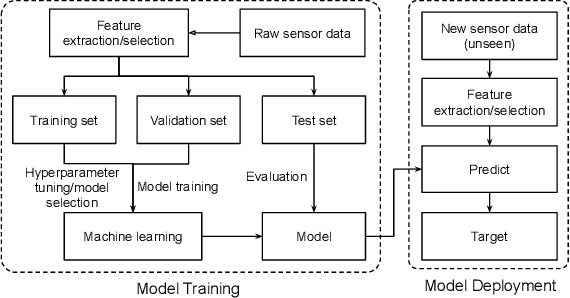
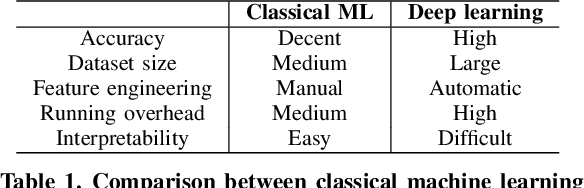
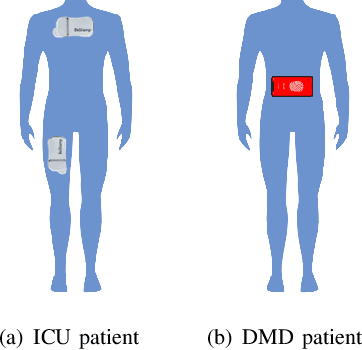
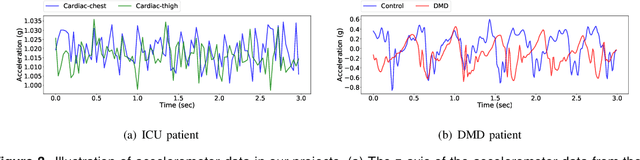
With the rapid development of the internet of things (IoT) and artificial intelligence (AI) technologies, human activity recognition (HAR) has been applied in a variety of domains such as security and surveillance, human-robot interaction, and entertainment. Even though a number of surveys and review papers have been published, there is a lack of HAR overview paper focusing on healthcare applications that use wearable sensors. Therefore, we fill in the gap by presenting this overview paper. In particular, we present our emerging HAR projects for healthcare: identification of human activities for intensive care unit (ICU) patients and Duchenne muscular dystrophy (DMD) patients. Our HAR systems include hardware design to collect sensor data from ICU patients and DMD patients and accurate AI models to recognize patients' activities. This overview paper covers considerations and settings for building a HAR healthcare system, including sensor factors, AI model comparison, and system challenges.
BWCNN: Blink to Word, a Real-Time Convolutional Neural Network Approach
Jun 01, 2020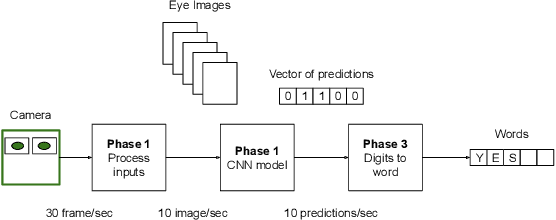


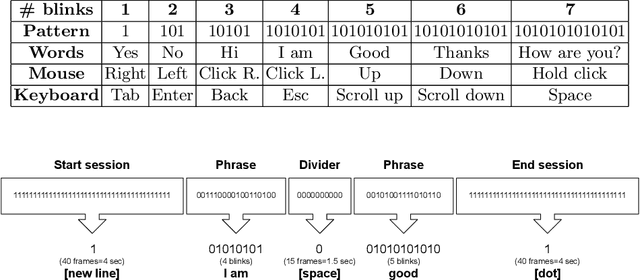
Amyotrophic lateral sclerosis (ALS) is a progressive neurodegenerative disease of the brain and the spinal cord, which leads to paralysis of motor functions. Patients retain their ability to blink, which can be used for communication. Here, We present an Artificial Intelligence (AI) system that uses eye-blinks to communicate with the outside world, running on real-time Internet-of-Things (IoT) devices. The system uses a Convolutional Neural Network (CNN) to find the blinking pattern, which is defined as a series of Open and Closed states. Each pattern is mapped to a collection of words that manifest the patient's intent. To investigate the best trade-off between accuracy and latency, we investigated several Convolutional Network architectures, such as ResNet, SqueezeNet, DenseNet, and InceptionV3, and evaluated their performance. We found that the InceptionV3 architecture, after hyper-parameter fine-tuning on the specific task led to the best performance with an accuracy of 99.20% and 94ms latency. This work demonstrates how the latest advances in deep learning architectures can be adapted for clinical systems that ameliorate the patient's quality of life regardless of the point-of-care.
Stable and expressive recurrent vision models
May 22, 2020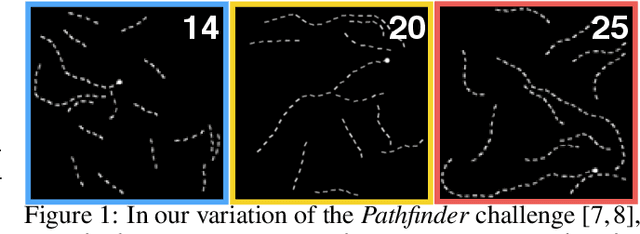
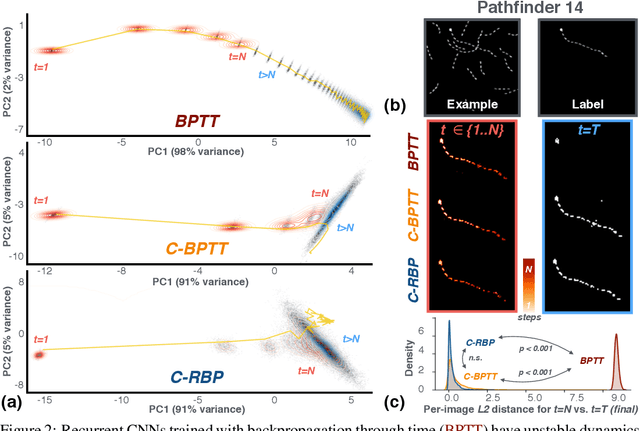
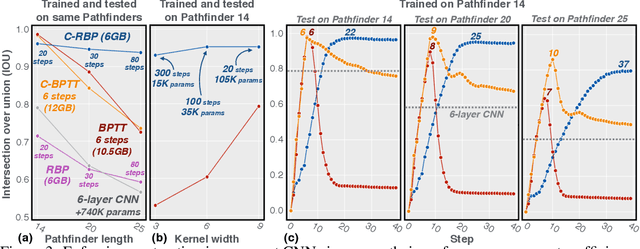
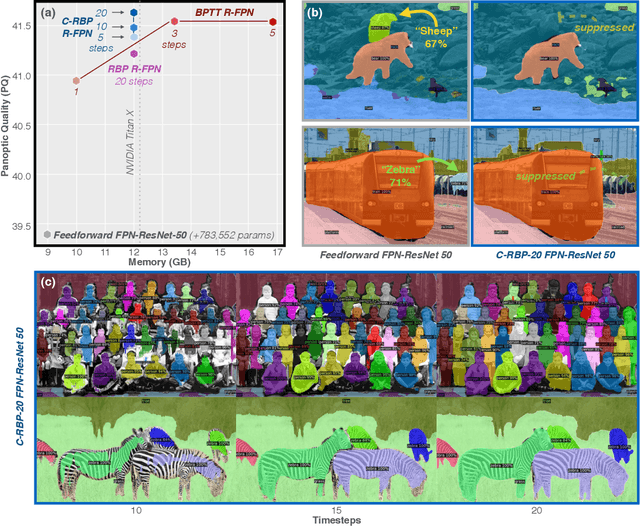
Primate vision depends on recurrent processing for reliable perception (Gilbert & Li, 2013). At the same time, there is a growing body of literature demonstrating that recurrent connections improve the learning efficiency and generalization of vision models on classic computer vision challenges. Why then, are current large-scale challenges dominated by feedforward networks? We posit that the effectiveness of recurrent vision models is bottlenecked by the widespread algorithm used for training them, "back-propagation through time" (BPTT), which has O(N) memory-complexity for training an N step model. Thus, recurrent vision model design is bounded by memory constraints, forcing a choice between rivaling the enormous capacity of leading feedforward models or trying to compensate for this deficit through granular and complex dynamics. Here, we develop a new learning algorithm, "contractor recurrent back-propagation" (C-RBP), which alleviates these issues by achieving constant O(1) memory-complexity with steps of recurrent processing. We demonstrate that recurrent vision models trained with C-RBP can detect long-range spatial dependencies in a synthetic contour tracing task that BPTT-trained models cannot. We further demonstrate that recurrent vision models trained with C-RBP to solve the large-scale Panoptic Segmentation MS-COCO challenge outperform the leading feedforward approach. C-RBP is a general-purpose learning algorithm for any application that can benefit from expansive recurrent dynamics. Code and data are available at https://github.com/c-rbp.