 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing and exploiting the computational demands of videos games for deep reinforcement learning
Sep 22, 2023Humans learn by interacting with their environments and perceiving the outcomes of their actions. A landmark in artificial intelligence has been the development of deep reinforcement learning (dRL) algorithms capable of doing the same in video games, on par with or better than humans. However, it remains unclear whether the successes of dRL models reflect advances in visual representation learning, the effectiveness of reinforcement learning algorithms at discovering better policies, or both. To address this question, we introduce the Learning Challenge Diagnosticator (LCD), a tool that separately measures the perceptual and reinforcement learning demands of a task. We use LCD to discover a novel taxonomy of challenges in the Procgen benchmark, and demonstrate that these predictions are both highly reliable and can instruct algorithmic development. More broadly, the LCD reveals multiple failure cases that can occur when optimizing dRL algorithms over entire video game benchmarks like Procgen, and provides a pathway towards more efficient progress.
Computing a human-like reaction time metric from stable recurrent vision models
Jun 20, 2023The meteoric rise in the adoption of deep neural networks as computational models of vision has inspired efforts to "align" these models with humans. One dimension of interest for alignment includes behavioral choices, but moving beyond characterizing choice patterns to capturing temporal aspects of visual decision-making has been challenging. Here, we sketch a general-purpose methodology to construct computational accounts of reaction times from a stimulus-computable, task-optimized model. Specifically, we introduce a novel metric leveraging insights from subjective logic theory summarizing evidence accumulation in recurrent vision models. We demonstrate that our metric aligns with patterns of human reaction times for stimulus manipulations across four disparate visual decision-making tasks spanning perceptual grouping, mental simulation, and scene categorization. This work paves the way for exploring the temporal alignment of model and human visual strategies in the context of various other cognitive tasks toward generating testable hypotheses for neuroscience.
Stable and expressive recurrent vision models
May 22, 2020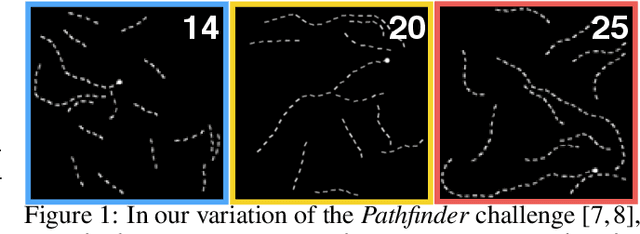
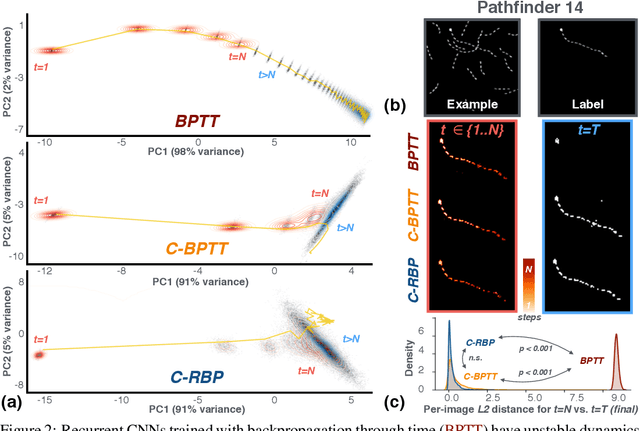
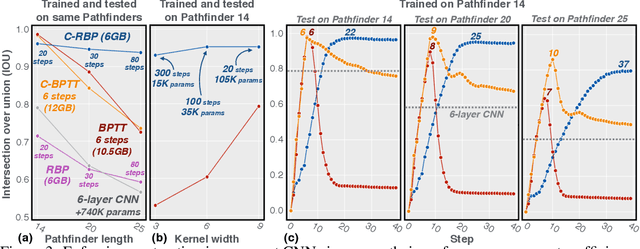
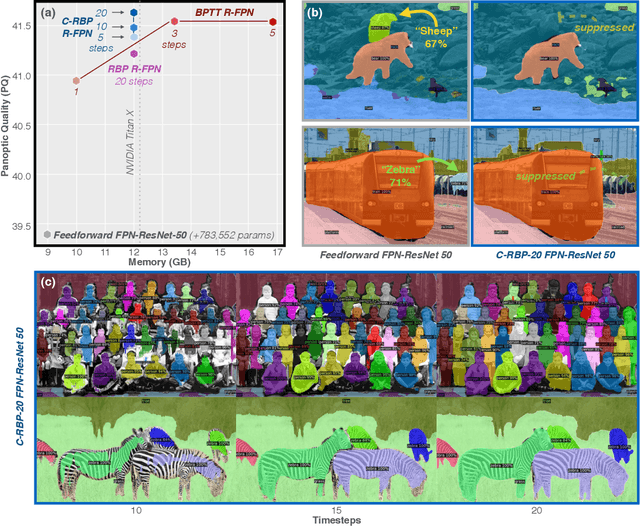
Primate vision depends on recurrent processing for reliable perception (Gilbert & Li, 2013). At the same time, there is a growing body of literature demonstrating that recurrent connections improve the learning efficiency and generalization of vision models on classic computer vision challenges. Why then, are current large-scale challenges dominated by feedforward networks? We posit that the effectiveness of recurrent vision models is bottlenecked by the widespread algorithm used for training them, "back-propagation through time" (BPTT), which has O(N) memory-complexity for training an N step model. Thus, recurrent vision model design is bounded by memory constraints, forcing a choice between rivaling the enormous capacity of leading feedforward models or trying to compensate for this deficit through granular and complex dynamics. Here, we develop a new learning algorithm, "contractor recurrent back-propagation" (C-RBP), which alleviates these issues by achieving constant O(1) memory-complexity with steps of recurrent processing. We demonstrate that recurrent vision models trained with C-RBP can detect long-range spatial dependencies in a synthetic contour tracing task that BPTT-trained models cannot. We further demonstrate that recurrent vision models trained with C-RBP to solve the large-scale Panoptic Segmentation MS-COCO challenge outperform the leading feedforward approach. C-RBP is a general-purpose learning algorithm for any application that can benefit from expansive recurrent dynamics. Code and data are available at https://github.com/c-rbp.
Robust pose tracking with a joint model of appearance and shape
Jun 28, 2018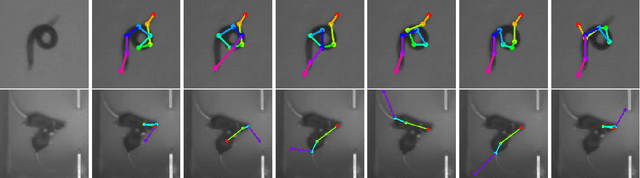
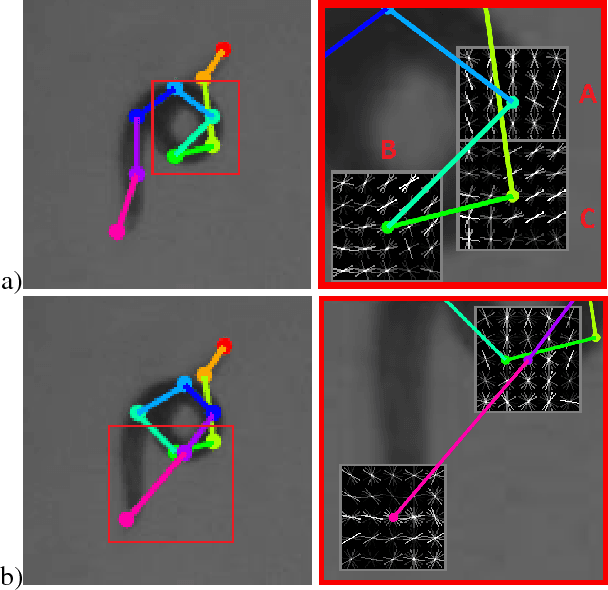
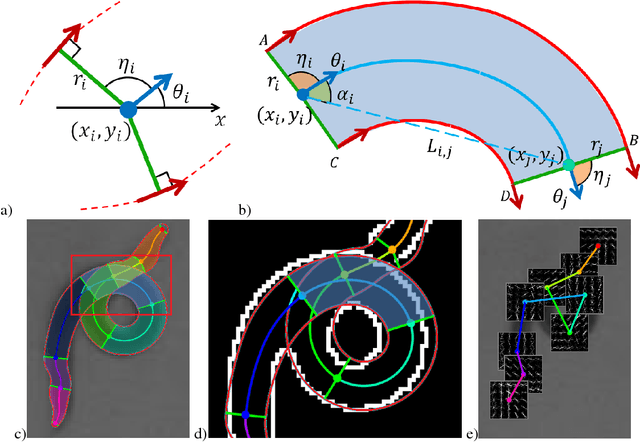
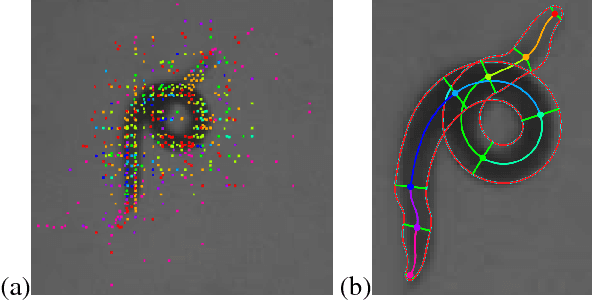
We present a novel approach for estimating the 2D pose of an articulated object with an application to automated video analysis of small laboratory animals. We have found that deformable part models developed for humans, exemplified by the flexible mixture of parts (FMP) model, typically fail on challenging animal poses. We argue that beyond encoding appearance and spatial relations, shape is needed to overcome the lack of distinctive landmarks on laboratory animal bodies. In our approach, a shape consistent FMP (scFMP) model computes promising pose candidates after a standard FMP model is used to rapidly discard false part detections. This "cascaded" approach combines the relative strengths of spatial-relations, appearance and shape representations and is shown to yield significant improvements over the original FMP model as well as a representative deep neural network baseline.
An Interval-Based Bayesian Generative Model for Human Complex Activity Recognition
Jan 04, 2017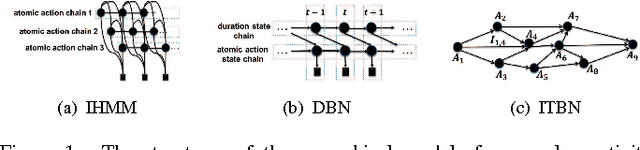
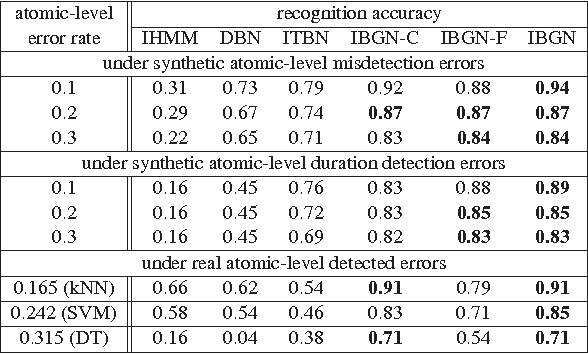
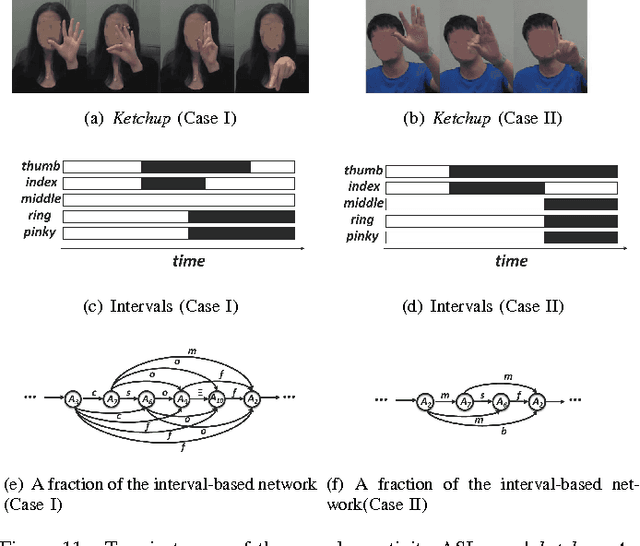
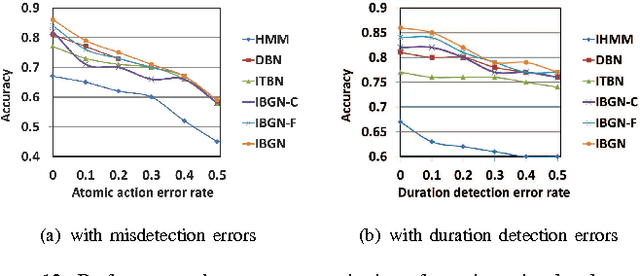
Complex activity recognition is challenging due to the inherent uncertainty and diversity of performing a complex activity. Normally, each instance of a complex activity has its own configuration of atomic actions and their temporal dependencies. We propose in this paper an atomic action-based Bayesian model that constructs Allen's interval relation networks to characterize complex activities with structural varieties in a probabilistic generative way: By introducing latent variables from the Chinese restaurant process, our approach is able to capture all possible styles of a particular complex activity as a unique set of distributions over atomic actions and relations. We also show that local temporal dependencies can be retained and are globally consistent in the resulting interval network. Moreover, network structure can be learned from empirical data. A new dataset of complex hand activities has been constructed and made publicly available, which is much larger in size than any existing datasets. Empirical evaluations on benchmark datasets as well as our in-house dataset demonstrate the competitiveness of our approach.
Lie-X: Depth Image Based Articulated Object Pose Estimation, Tracking, and Action Recognition on Lie Groups
Sep 13, 2016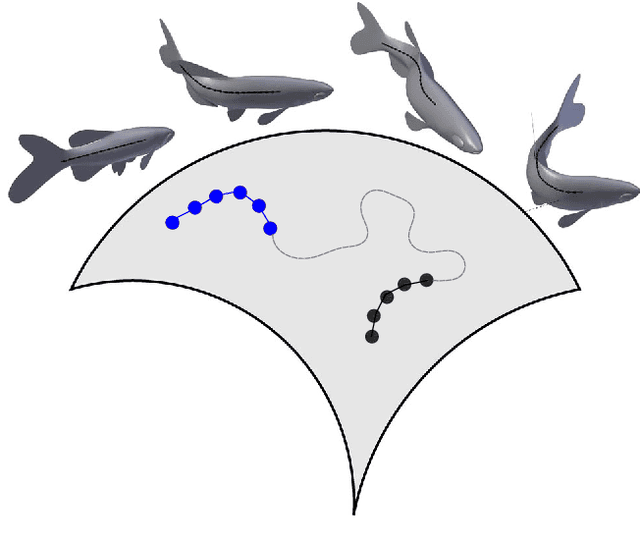
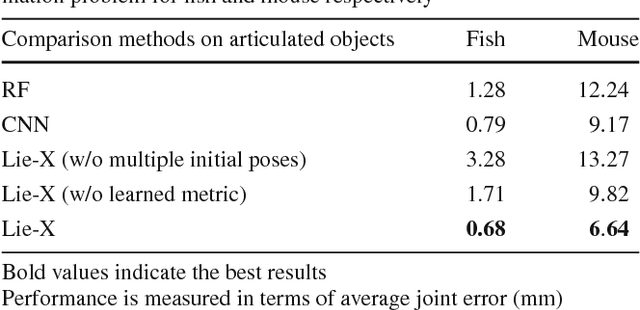
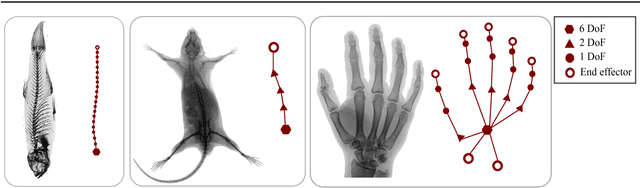

Pose estimation, tracking, and action recognition of articulated objects from depth images are important and challenging problems, which are normally considered separately. In this paper, a unified paradigm based on Lie group theory is proposed, which enables us to collectively address these related problems. Our approach is also applicable to a wide range of articulated objects. Empirically it is evaluated on lab animals including mouse and fish, as well as on human hand. On these applications, it is shown to deliver competitive results compared to the state-of-the-arts, and non-trivial baselines including convolutional neural networks and regression forest methods.
Hand Action Detection from Ego-centric Depth Sequences with Error-correcting Hough Transform
Jun 07, 2016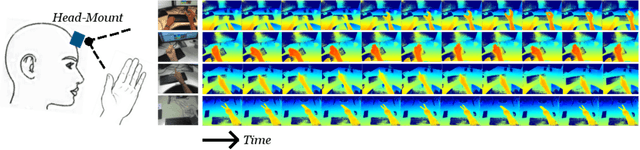
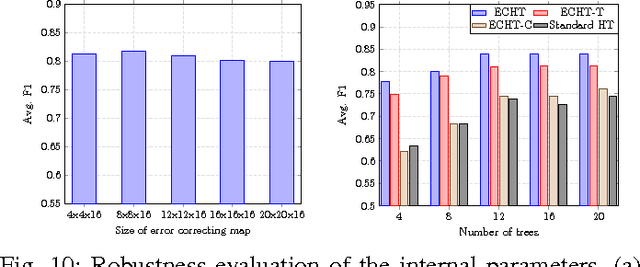
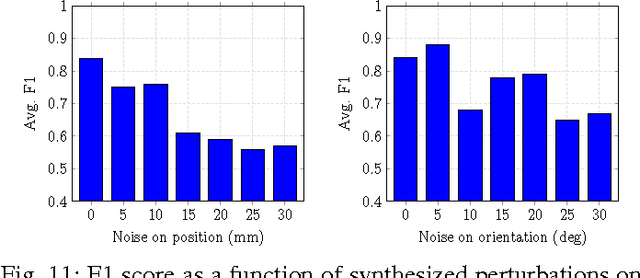

Detecting hand actions from ego-centric depth sequences is a practically challenging problem, owing mostly to the complex and dexterous nature of hand articulations as well as non-stationary camera motion. We address this problem via a Hough transform based approach coupled with a discriminatively learned error-correcting component to tackle the well known issue of incorrect votes from the Hough transform. In this framework, local parts vote collectively for the start $\&$ end positions of each action over time. We also construct an in-house annotated dataset of 300 long videos, containing 3,177 single-action subsequences over 16 action classes collected from 26 individuals. Our system is empirically evaluated on this real-life dataset for both the action recognition and detection tasks, and is shown to produce satisfactory results. To facilitate reproduction, the new dataset and our implementation are also provided online.