 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI in clinical practice: novel qualitative evidence of risk and responsible use of Google's NotebookLM
May 04, 2025The advent of generative artificial intelligence, especially large language models (LLMs), presents opportunities for innovation in research, clinical practice, and education. Recently, Dihan et al. lauded LLM tool NotebookLM's potential, including for generating AI-voiced podcasts to educate patients about treatment and rehabilitation, and for quickly synthesizing medical literature for professionals. We argue that NotebookLM presently poses clinical and technological risks that should be tested and considered prior to its implementation in clinical practice.
Diagnosing and exploiting the computational demands of videos games for deep reinforcement learning
Sep 22, 2023Humans learn by interacting with their environments and perceiving the outcomes of their actions. A landmark in artificial intelligence has been the development of deep reinforcement learning (dRL) algorithms capable of doing the same in video games, on par with or better than humans. However, it remains unclear whether the successes of dRL models reflect advances in visual representation learning, the effectiveness of reinforcement learning algorithms at discovering better policies, or both. To address this question, we introduce the Learning Challenge Diagnosticator (LCD), a tool that separately measures the perceptual and reinforcement learning demands of a task. We use LCD to discover a novel taxonomy of challenges in the Procgen benchmark, and demonstrate that these predictions are both highly reliable and can instruct algorithmic development. More broadly, the LCD reveals multiple failure cases that can occur when optimizing dRL algorithms over entire video game benchmarks like Procgen, and provides a pathway towards more efficient progress.
I'm Afraid I Can't Do That: Predicting Prompt Refusal in Black-Box Generative Language Models
Jun 14, 2023
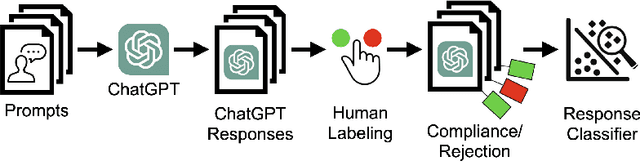

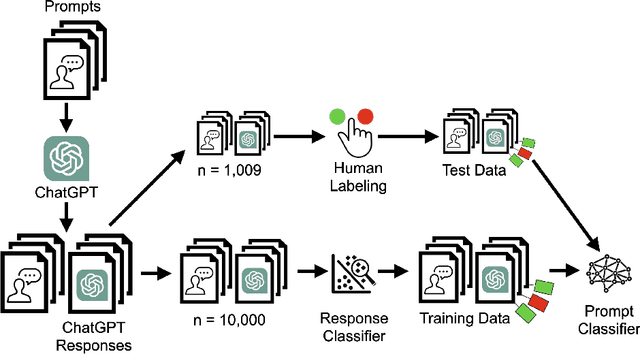
Since the release of OpenAI's ChatGPT, generative language models have attracted extensive public attention. The increased usage has highlighted generative models' broad utility, but also revealed several forms of embedded bias. Some is induced by the pre-training corpus; but additional bias specific to generative models arises from the use of subjective fine-tuning to avoid generating harmful content. Fine-tuning bias may come from individual engineers and company policies, and affects which prompts the model chooses to refuse. In this experiment, we characterize ChatGPT's refusal behavior using a black-box attack. We first query ChatGPT with a variety of offensive and benign prompts (n=1,706), then manually label each response as compliance or refusal. Manual examination of responses reveals that refusal is not cleanly binary, and lies on a continuum; as such, we map several different kinds of responses to a binary of compliance or refusal. The small manually-labeled dataset is used to train a refusal classifier, which achieves an accuracy of 96%. Second, we use this refusal classifier to bootstrap a larger (n=10,000) dataset adapted from the Quora Insincere Questions dataset. With this machine-labeled data, we train a prompt classifier to predict whether ChatGPT will refuse a given question, without seeing ChatGPT's response. This prompt classifier achieves 76% accuracy on a test set of manually labeled questions (n=985). We examine our classifiers and the prompt n-grams that are most predictive of either compliance or refusal. Our datasets and code are available at https://github.com/maxwellreuter/chatgpt-refusals.
Sublinear Subwindow Search
Jul 31, 2019

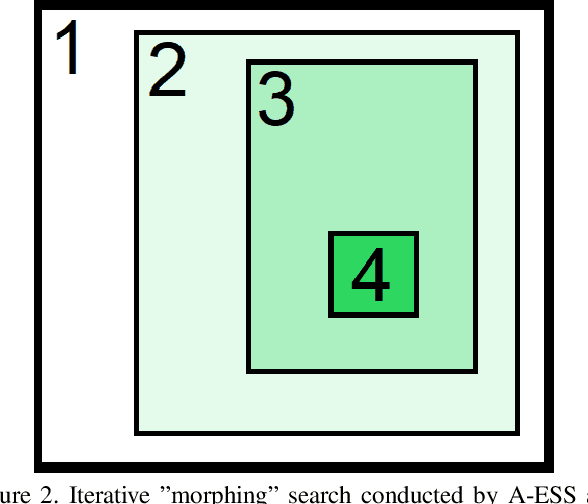
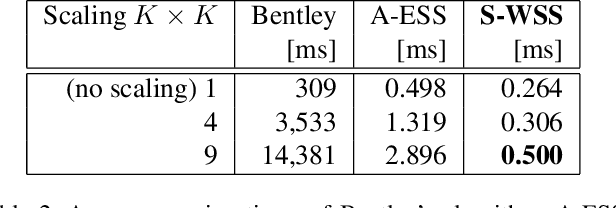
We propose an efficient approximation algorithm for subwindow search that runs in sublinear time and memory. Applied to object localization, this algorithm significantly reduces running time and memory usage while maintaining competitive accuracy scores compared to the state-of-the-art. The algorithm's accuracy also scales with both the size and the spatial coherence (nearby-element similarity) of the matrix. It is thus well-suited for real-time applications and against many matrices in general.