 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI'm Afraid I Can't Do That: Predicting Prompt Refusal in Black-Box Generative Language Models
Paper and Code

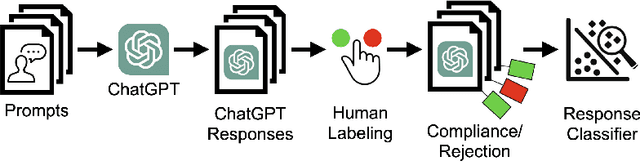

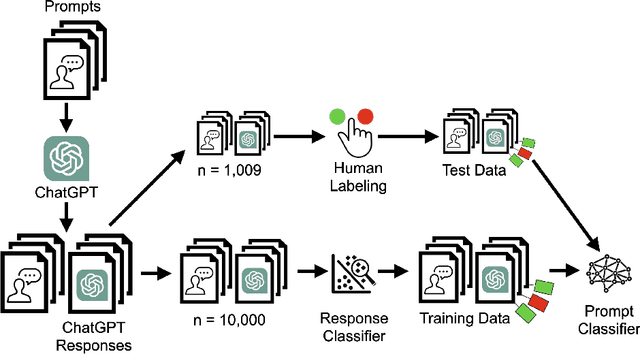
Since the release of OpenAI's ChatGPT, generative language models have attracted extensive public attention. The increased usage has highlighted generative models' broad utility, but also revealed several forms of embedded bias. Some is induced by the pre-training corpus; but additional bias specific to generative models arises from the use of subjective fine-tuning to avoid generating harmful content. Fine-tuning bias may come from individual engineers and company policies, and affects which prompts the model chooses to refuse. In this experiment, we characterize ChatGPT's refusal behavior using a black-box attack. We first query ChatGPT with a variety of offensive and benign prompts (n=1,706), then manually label each response as compliance or refusal. Manual examination of responses reveals that refusal is not cleanly binary, and lies on a continuum; as such, we map several different kinds of responses to a binary of compliance or refusal. The small manually-labeled dataset is used to train a refusal classifier, which achieves an accuracy of 96%. Second, we use this refusal classifier to bootstrap a larger (n=10,000) dataset adapted from the Quora Insincere Questions dataset. With this machine-labeled data, we train a prompt classifier to predict whether ChatGPT will refuse a given question, without seeing ChatGPT's response. This prompt classifier achieves 76% accuracy on a test set of manually labeled questions (n=985). We examine our classifiers and the prompt n-grams that are most predictive of either compliance or refusal. Our datasets and code are available at https://github.com/maxwellreuter/chatgpt-refusals.