 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal vs distributed representations: What is the right basis for interpretability?
Nov 06, 2024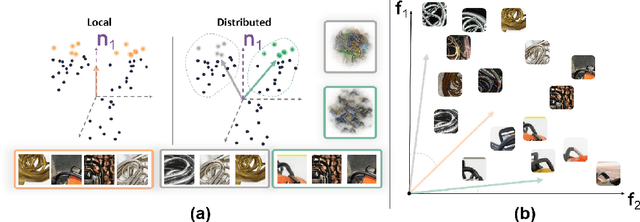


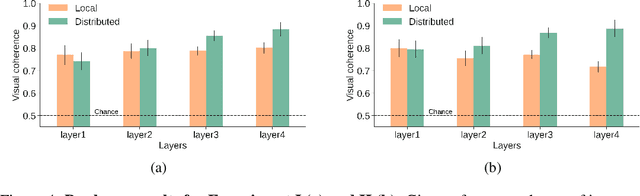
Much of the research on the interpretability of deep neural networks has focused on studying the visual features that maximally activate individual neurons. However, recent work has cast doubts on the usefulness of such local representations for understanding the behavior of deep neural networks because individual neurons tend to respond to multiple unrelated visual patterns, a phenomenon referred to as "superposition". A promising alternative to disentangle these complex patterns is learning sparsely distributed vector representations from entire network layers, as the resulting basis vectors seemingly encode single identifiable visual patterns consistently. Thus, one would expect the resulting code to align better with human perceivable visual patterns, but supporting evidence remains, at best, anecdotal. To fill this gap, we conducted three large-scale psychophysics experiments collected from a pool of 560 participants. Our findings provide (i) strong evidence that features obtained from sparse distributed representations are easier to interpret by human observers and (ii) that this effect is more pronounced in the deepest layers of a neural network. Complementary analyses also reveal that (iii) features derived from sparse distributed representations contribute more to the model's decision. Overall, our results highlight that distributed representations constitute a superior basis for interpretability, underscoring a need for the field to move beyond the interpretation of local neural codes in favor of sparsely distributed ones.
Computing a human-like reaction time metric from stable recurrent vision models
Jun 20, 2023The meteoric rise in the adoption of deep neural networks as computational models of vision has inspired efforts to "align" these models with humans. One dimension of interest for alignment includes behavioral choices, but moving beyond characterizing choice patterns to capturing temporal aspects of visual decision-making has been challenging. Here, we sketch a general-purpose methodology to construct computational accounts of reaction times from a stimulus-computable, task-optimized model. Specifically, we introduce a novel metric leveraging insights from subjective logic theory summarizing evidence accumulation in recurrent vision models. We demonstrate that our metric aligns with patterns of human reaction times for stimulus manipulations across four disparate visual decision-making tasks spanning perceptual grouping, mental simulation, and scene categorization. This work paves the way for exploring the temporal alignment of model and human visual strategies in the context of various other cognitive tasks toward generating testable hypotheses for neuroscience.
Memorability: An image-computable measure of information utility
Apr 01, 2021
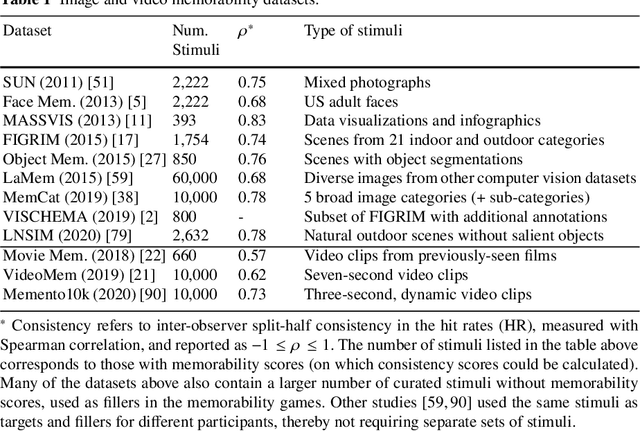

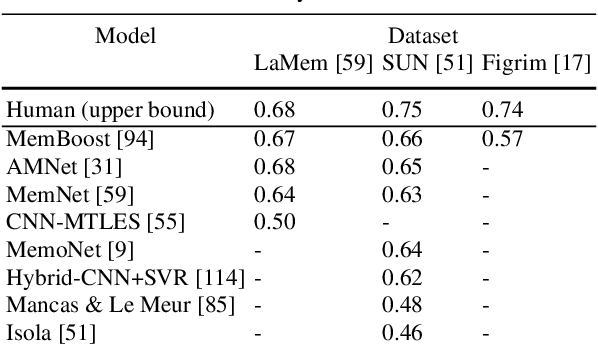
The pixels in an image, and the objects, scenes, and actions that they compose, determine whether an image will be memorable or forgettable. While memorability varies by image, it is largely independent of an individual observer. Observer independence is what makes memorability an image-computable measure of information, and eligible for automatic prediction. In this chapter, we zoom into memorability with a computational lens, detailing the state-of-the-art algorithms that accurately predict image memorability relative to human behavioral data, using image features at different scales from raw pixels to semantic labels. We discuss the design of algorithms and visualizations for face, object, and scene memorability, as well as algorithms that generalize beyond static scenes to actions and videos. We cover the state-of-the-art deep learning approaches that are the current front runners in the memorability prediction space. Beyond prediction, we show how recent A.I. approaches can be used to create and modify visual memorability. Finally, we preview the computational applications that memorability can power, from filtering visual streams to enhancing augmented reality interfaces.
GANalyze: Toward Visual Definitions of Cognitive Image Properties
Jun 24, 2019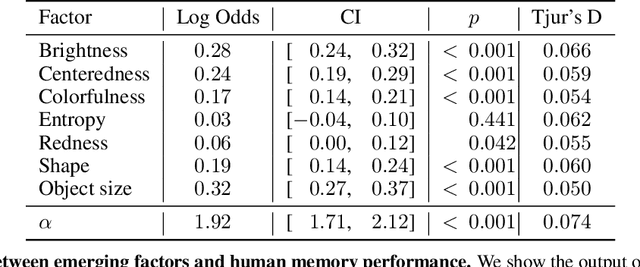

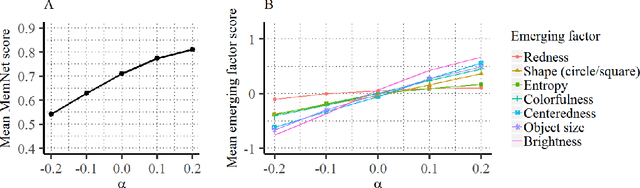
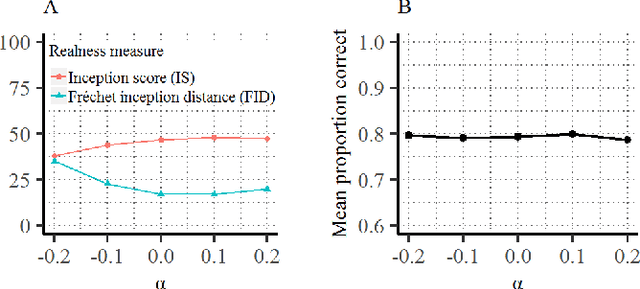
We introduce a framework that uses Generative Adversarial Networks (GANs) to study cognitive properties like memorability, aesthetics, and emotional valence. These attributes are of interest because we do not have a concrete visual definition of what they entail. What does it look like for a dog to be more or less memorable? GANs allow us to generate a manifold of natural-looking images with fine-grained differences in their visual attributes. By navigating this manifold in directions that increase memorability, we can visualize what it looks like for a particular generated image to become more or less memorable. The resulting ``visual definitions" surface image properties (like ``object size") that may underlie memorability. Through behavioral experiments, we verify that our method indeed discovers image manipulations that causally affect human memory performance. We further demonstrate that the same framework can be used to analyze image aesthetics and emotional valence. Visit the GANalyze website at http://ganalyze.csail.mit.edu/.