 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEngineering flexible machine learning systems by traversing functionally invariant paths in weight space
May 09, 2022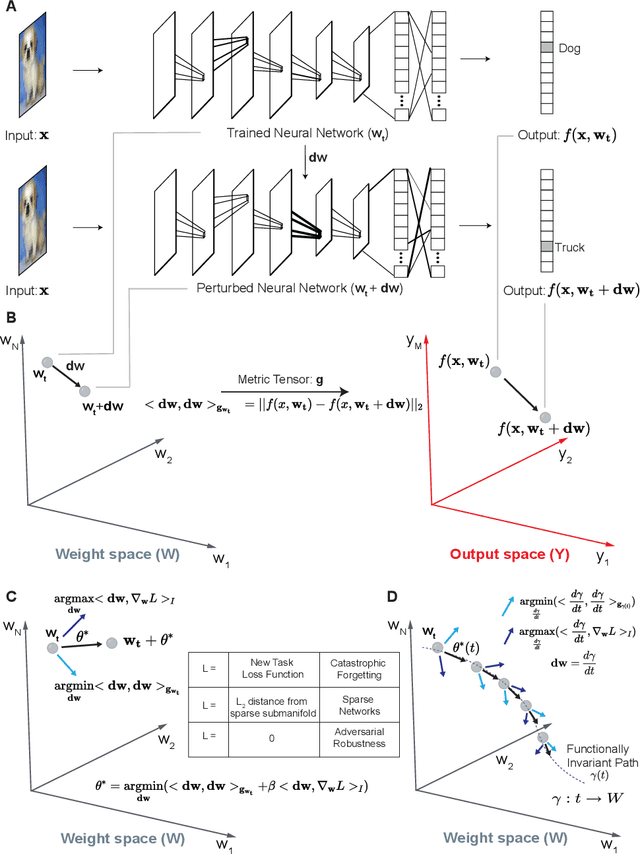
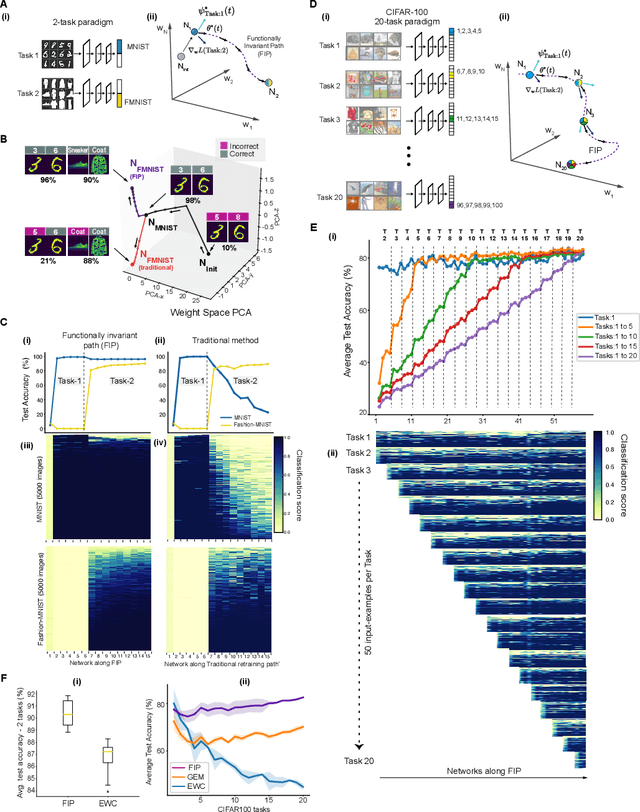
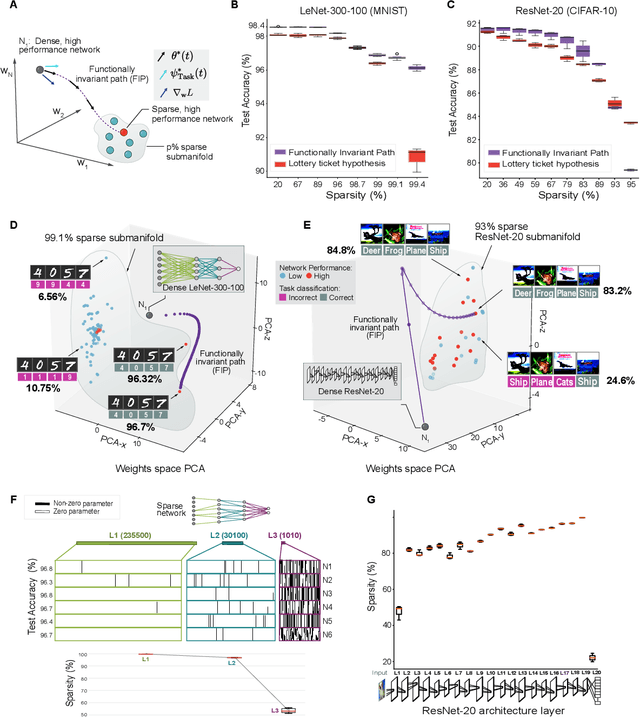
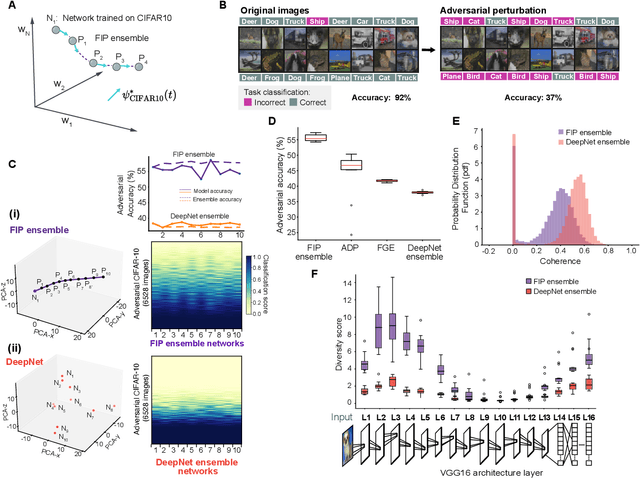
Deep neural networks achieve human-like performance on a variety of perceptual and decision making tasks. However, deep networks perform poorly when confronted with changing tasks or goals, and broadly fail to match the flexibility and robustness of human intelligence. Here, we develop a mathematical and algorithmic framework that enables continual training of deep neural networks on a broad range of objectives by defining path connected sets of neural networks that achieve equivalent functional performance on a given machine learning task while modulating network weights to achieve high-performance on a secondary objective. We view the weight space of a neural network as a curved Riemannian manifold and move a neural network along a functionally invariant path in weight space while searching for networks that satisfy a secondary objective. We introduce a path-sampling algorithm that trains networks with millions of weight parameters to learn a series of image classification tasks without performance loss. The algorithm generalizes to accommodate a range of secondary objectives including weight-pruning and weight diversification and exhibits state of the art performance on network compression and adversarial robustness benchmarks. Broadly, we demonstrate how the intrinsic geometry of machine learning problems can be harnessed to construct flexible and robust neural networks.
Solving hybrid machine learning tasks by traversing weight space geodesics
Jun 05, 2021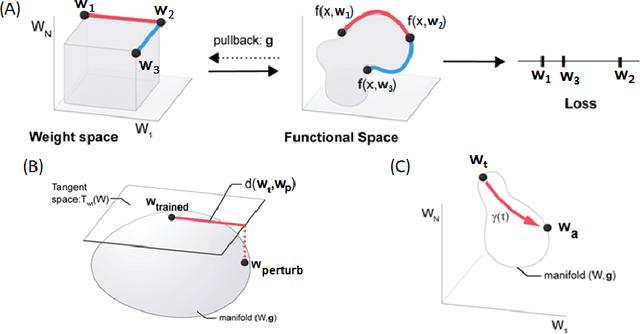
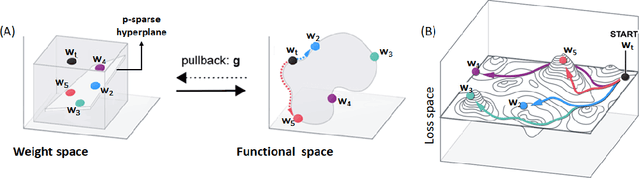
Machine learning problems have an intrinsic geometric structure as central objects including a neural network's weight space and the loss function associated with a particular task can be viewed as encoding the intrinsic geometry of a given machine learning problem. Therefore, geometric concepts can be applied to analyze and understand theoretical properties of machine learning strategies as well as to develop new algorithms. In this paper, we address three seemingly unrelated open questions in machine learning by viewing them through a unified framework grounded in differential geometry. Specifically, we view the weight space of a neural network as a manifold endowed with a Riemannian metric that encodes performance on specific tasks. By defining a metric, we can construct geodesic, minimum length, paths in weight space that represent sets of networks of equivalent or near equivalent functional performance on a specific task. We, then, traverse geodesic paths while identifying networks that satisfy a second objective. Inspired by the geometric insight, we apply our geodesic framework to 3 major applications: (i) Network sparsification (ii) Mitigating catastrophic forgetting by constructing networks with high performance on a series of objectives and (iii) Finding high-accuracy paths connecting distinct local optima of deep networks in the non-convex loss landscape. Our results are obtained on a wide range of network architectures (MLP, VGG11/16) trained on MNIST, CIFAR-10/100. Broadly, we introduce a geometric framework that unifies a range of machine learning objectives and that can be applied to multiple classes of neural network architectures.
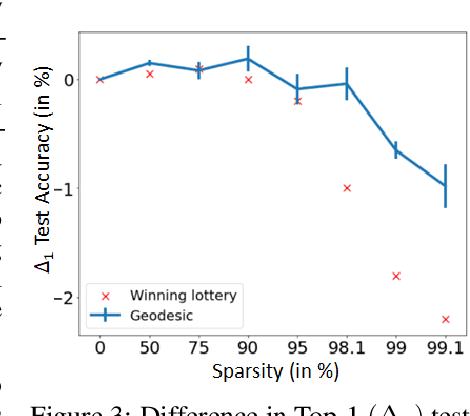
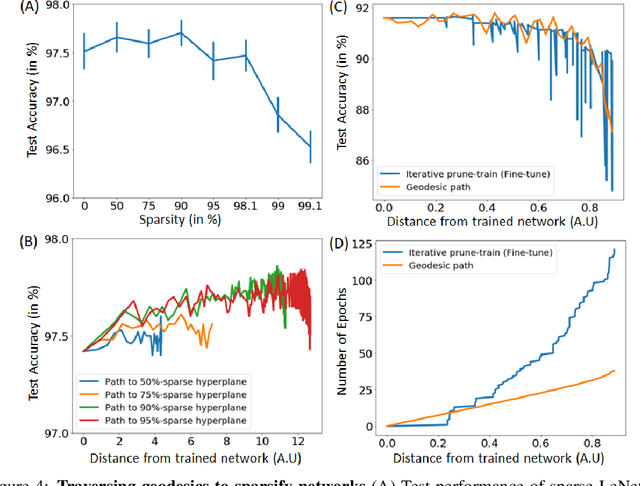
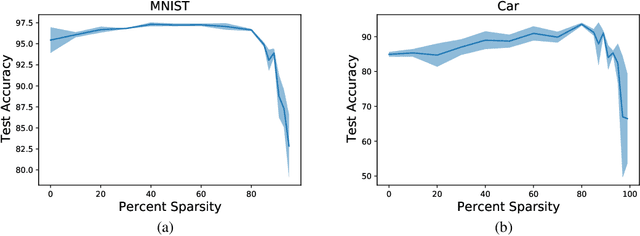
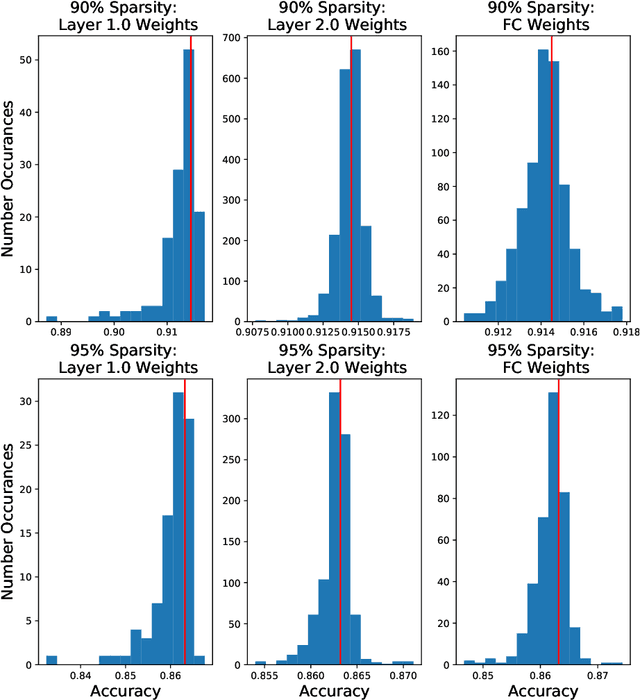
Sparsifying networks by traversing Geodesics
Dec 12, 2020
The geometry of weight spaces and functional manifolds of neural networks play an important role towards 'understanding' the intricacies of ML. In this paper, we attempt to solve certain open questions in ML, by viewing them through the lens of geometry, ultimately relating it to the discovery of points or paths of equivalent function in these spaces. We propose a mathematical framework to evaluate geodesics in the functional space, to find high-performance paths from a dense network to its sparser counterpart. Our results are obtained on VGG-11 trained on CIFAR-10 and MLP's trained on MNIST. Broadly, we demonstrate that the framework is general, and can be applied to a wide variety of problems, ranging from sparsification to alleviating catastrophic forgetting.
Architecture Agnostic Neural Networks
Nov 05, 2020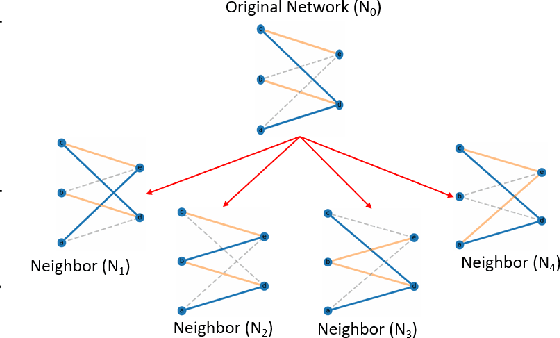
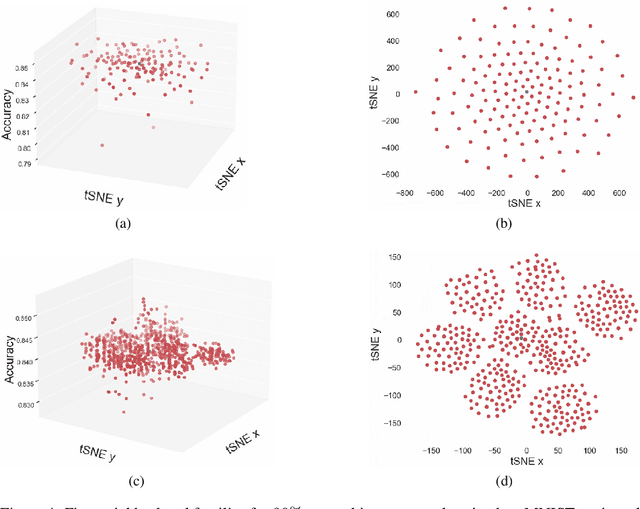
In this paper, we explore an alternate method for synthesizing neural network architectures, inspired by the brain's stochastic synaptic pruning. During a person's lifetime, numerous distinct neuronal architectures are responsible for performing the same tasks. This indicates that biological neural networks are, to some degree, architecture agnostic. However, artificial networks rely on their fine-tuned weights and hand-crafted architectures for their remarkable performance. This contrast begs the question: Can we build artificial architecture agnostic neural networks? To ground this study we utilize sparse, binary neural networks that parallel the brain's circuits. Within this sparse, binary paradigm we sample many binary architectures to create families of architecture agnostic neural networks not trained via backpropagation. These high-performing network families share the same sparsity, distribution of binary weights, and succeed in both static and dynamic tasks. In summation, we create an architecture manifold search procedure to discover families or architecture agnostic neural networks.
Self-organization of multi-layer spiking neural networks
Jun 12, 2020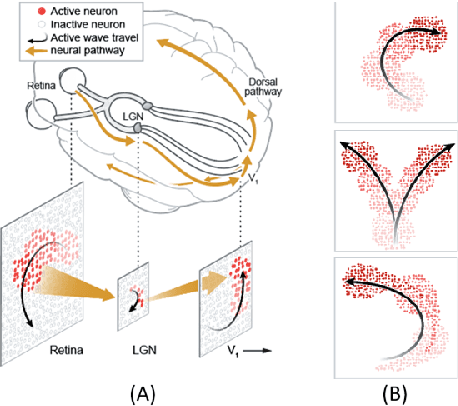
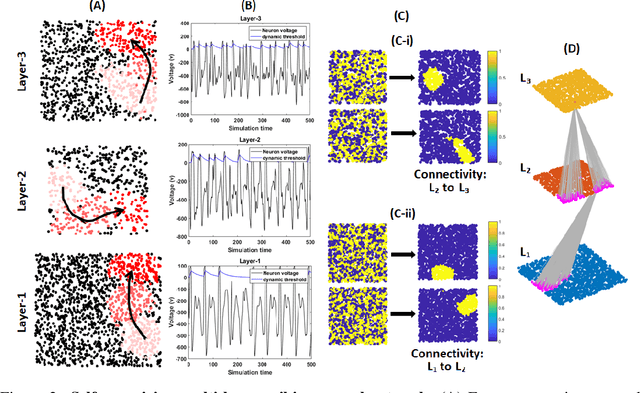
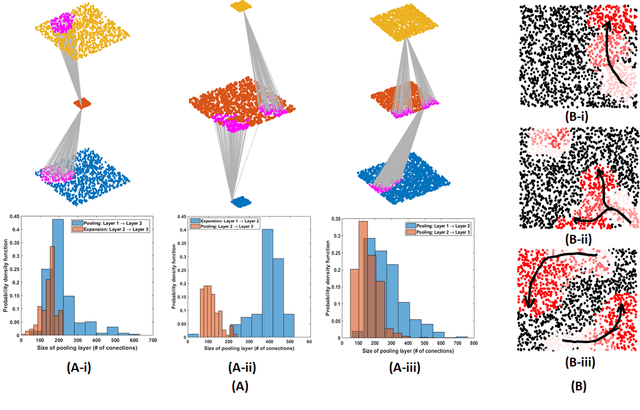
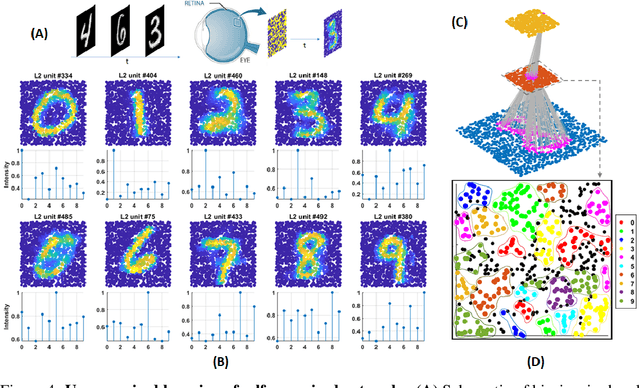
Living neural networks in our brains autonomously self-organize into large, complex architectures during early development to result in an organized and functional organic computational device. A key mechanism that enables the formation of complex architecture in the developing brain is the emergence of traveling spatio-temporal waves of neuronal activity across the growing brain. Inspired by this strategy, we attempt to efficiently self-organize large neural networks with an arbitrary number of layers into a wide variety of architectures. To achieve this, we propose a modular tool-kit in the form of a dynamical system that can be seamlessly stacked to assemble multi-layer neural networks. The dynamical system encapsulates the dynamics of spiking units, their inter/intra layer interactions as well as the plasticity rules that control the flow of information between layers. The key features of our tool-kit are (1) autonomous spatio-temporal waves across multiple layers triggered by activity in the preceding layer and (2) Spike-timing dependent plasticity (STDP) learning rules that update the inter-layer connectivity based on wave activity in the connecting layers. Our framework leads to the self-organization of a wide variety of architectures, ranging from multi-layer perceptrons to autoencoders. We also demonstrate that emergent waves can self-organize spiking network architecture to perform unsupervised learning, and networks can be coupled with a linear classifier to perform classification on classic image datasets like MNIST. Broadly, our work shows that a dynamical systems framework for learning can be used to self-organize large computational devices.
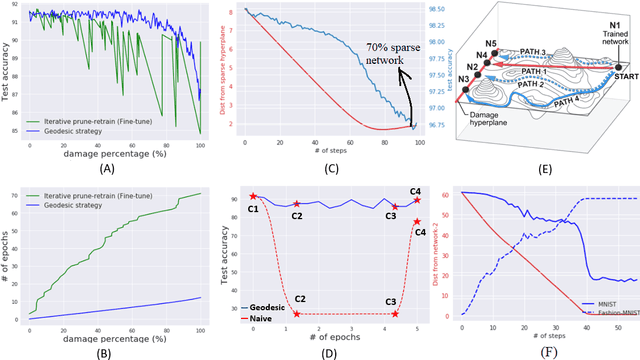
Geometric algorithms for predicting resilience and recovering damage in neural networks
Jun 02, 2020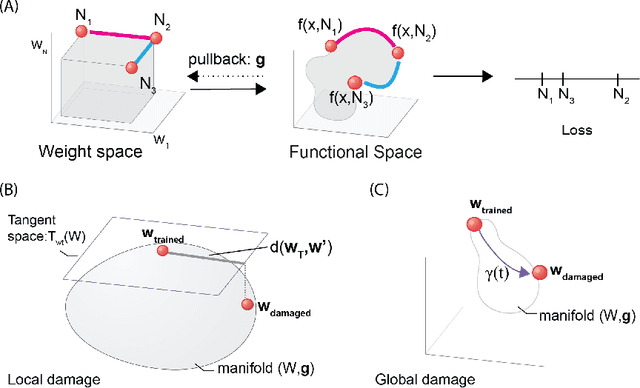
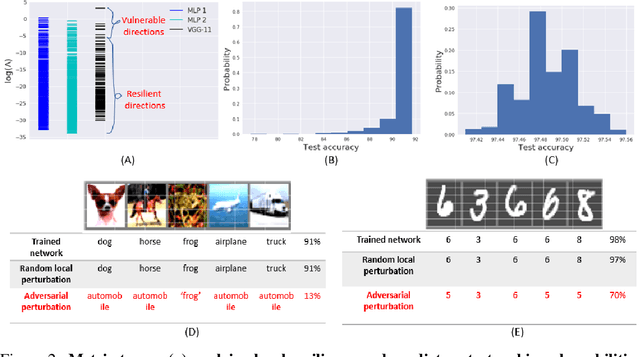
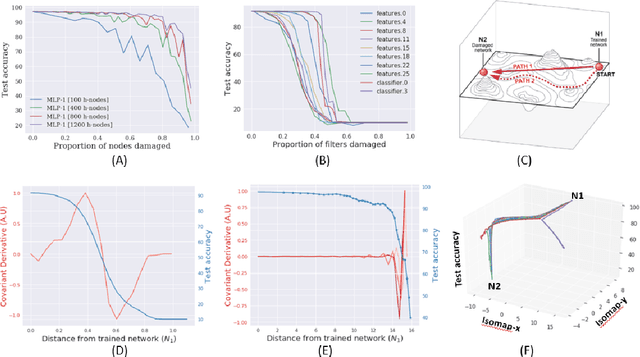
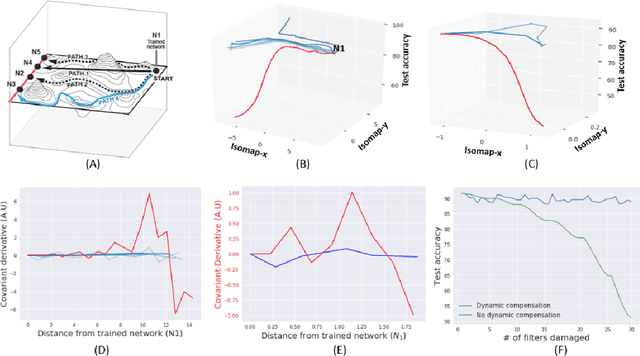
Biological neural networks have evolved to maintain performance despite significant circuit damage. To survive damage, biological network architectures have both intrinsic resilience to component loss and also activate recovery programs that adjust network weights through plasticity to stabilize performance. Despite the importance of resilience in technology applications, the resilience of artificial neural networks is poorly understood, and autonomous recovery algorithms have yet to be developed. In this paper, we establish a mathematical framework to analyze the resilience of artificial neural networks through the lens of differential geometry. Our geometric language provides natural algorithms that identify local vulnerabilities in trained networks as well as recovery algorithms that dynamically adjust networks to compensate for damage. We reveal striking vulnerabilities in commonly used image analysis networks, like MLP's and CNN's trained on MNIST and CIFAR10 respectively. We also uncover high-performance recovery paths that enable the same networks to dynamically re-adjust their parameters to compensate for damage. Broadly, our work provides procedures that endow artificial systems with resilience and rapid-recovery routines to enhance their integration with IoT devices as well as enable their deployment for critical applications.
Neural networks grown and self-organized by noise
Jun 03, 2019



Living neural networks emerge through a process of growth and self-organization that begins with a single cell and results in a brain, an organized and functional computational device. Artificial neural networks, however, rely on human-designed, hand-programmed architectures for their remarkable performance. Can we develop artificial computational devices that can grow and self-organize without human intervention? In this paper, we propose a biologically inspired developmental algorithm that can 'grow' a functional, layered neural network from a single initial cell. The algorithm organizes inter-layer connections to construct a convolutional pooling layer, a key constituent of convolutional neural networks (CNN's). Our approach is inspired by the mechanisms employed by the early visual system to wire the retina to the lateral geniculate nucleus (LGN), days before animals open their eyes. The key ingredients for robust self-organization are an emergent spontaneous spatiotemporal activity wave in the first layer and a local learning rule in the second layer that 'learns' the underlying activity pattern in the first layer. The algorithm is adaptable to a wide-range of input-layer geometries, robust to malfunctioning units in the first layer, and so can be used to successfully grow and self-organize pooling architectures of different pool-sizes and shapes. The algorithm provides a primitive procedure for constructing layered neural networks through growth and self-organization. Broadly, our work shows that biologically inspired developmental algorithms can be applied to autonomously grow functional 'brains' in-silico.