 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePopulation Transformer: Learning Population-level Representations of Intracranial Activity
Jun 05, 2024We present a self-supervised framework that learns population-level codes for intracranial neural recordings at scale, unlocking the benefits of representation learning for a key neuroscience recording modality. The Population Transformer (PopT) lowers the amount of data required for decoding experiments, while increasing accuracy, even on never-before-seen subjects and tasks. We address two key challenges in developing PopT: sparse electrode distribution and varying electrode location across patients. PopT stacks on top of pretrained representations and enhances downstream tasks by enabling learned aggregation of multiple spatially-sparse data channels. Beyond decoding, we interpret the pretrained PopT and fine-tuned models to show how it can be used to provide neuroscience insights learned from massive amounts of data. We release a pretrained PopT to enable off-the-shelf improvements in multi-channel intracranial data decoding and interpretability, and code is available at https://github.com/czlwang/PopulationTransformer.
Generalizability Under Sensor Failure: Tokenization + Transformers Enable More Robust Latent Spaces
Feb 29, 2024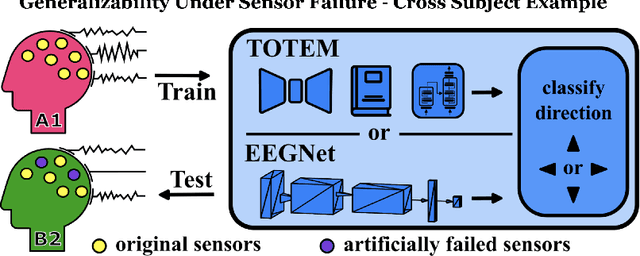
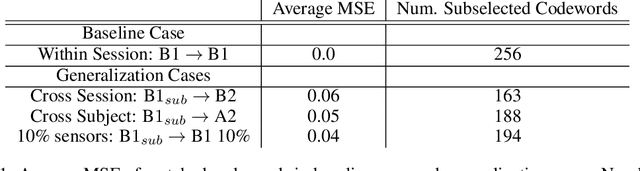
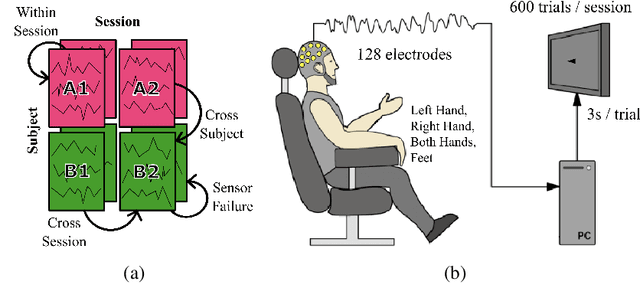
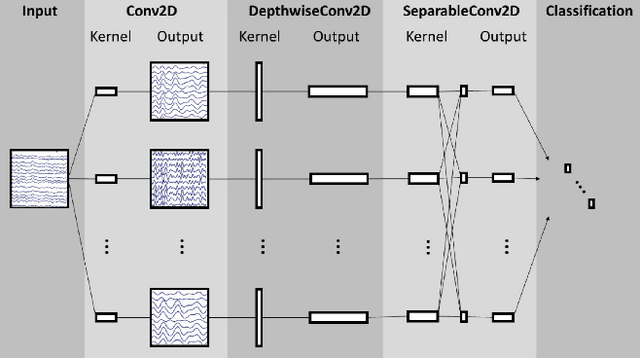
A major goal in neuroscience is to discover neural data representations that generalize. This goal is challenged by variability along recording sessions (e.g. environment), subjects (e.g. varying neural structures), and sensors (e.g. sensor noise), among others. Recent work has begun to address generalization across sessions and subjects, but few study robustness to sensor failure which is highly prevalent in neuroscience experiments. In order to address these generalizability dimensions we first collect our own electroencephalography dataset with numerous sessions, subjects, and sensors, then study two time series models: EEGNet (Lawhern et al., 2018) and TOTEM (Talukder et al., 2024). EEGNet is a widely used convolutional neural network, while TOTEM is a discrete time series tokenizer and transformer model. We find that TOTEM outperforms or matches EEGNet across all generalizability cases. Finally through analysis of TOTEM's latent codebook we observe that tokenization enables generalization
TOTEM: TOkenized Time Series EMbeddings for General Time Series Analysis
Feb 26, 2024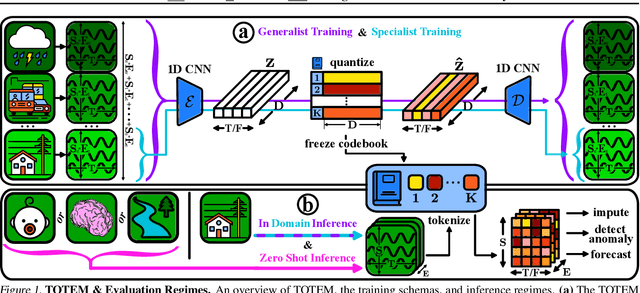

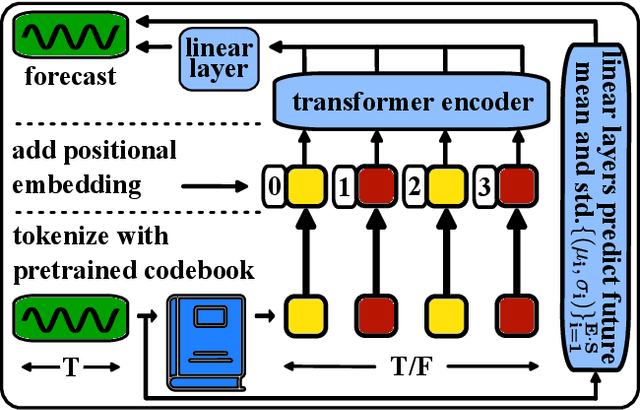

The field of general time series analysis has recently begun to explore unified modeling, where a common architectural backbone can be retrained on a specific task for a specific dataset. In this work, we approach unification from a complementary vantage point: unification across tasks and domains. To this end, we explore the impact of discrete, learnt, time series data representations that enable generalist, cross-domain training. Our method, TOTEM, or TOkenized Time Series EMbeddings, proposes a simple tokenizer architecture that embeds time series data from varying domains using a discrete vectorized representation learned in a self-supervised manner. TOTEM works across multiple tasks and domains with minimal to no tuning. We study the efficacy of TOTEM with an extensive evaluation on 17 real world time series datasets across 3 tasks. We evaluate both the specialist (i.e., training a model on each domain) and generalist (i.e., training a single model on many domains) settings, and show that TOTEM matches or outperforms previous best methods on several popular benchmarks. The code can be found at: https://github.com/SaberaTalukder/TOTEM.
Deep Neural Imputation: A Framework for Recovering Incomplete Brain Recordings
Jun 16, 2022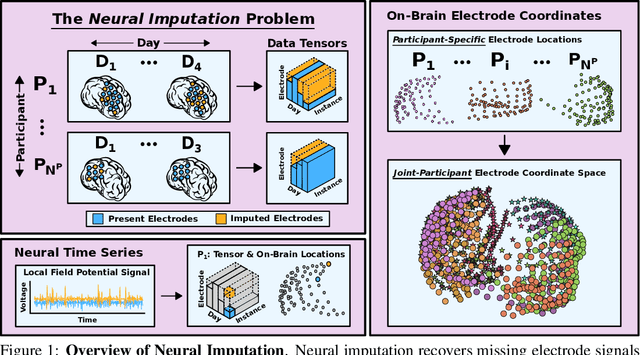
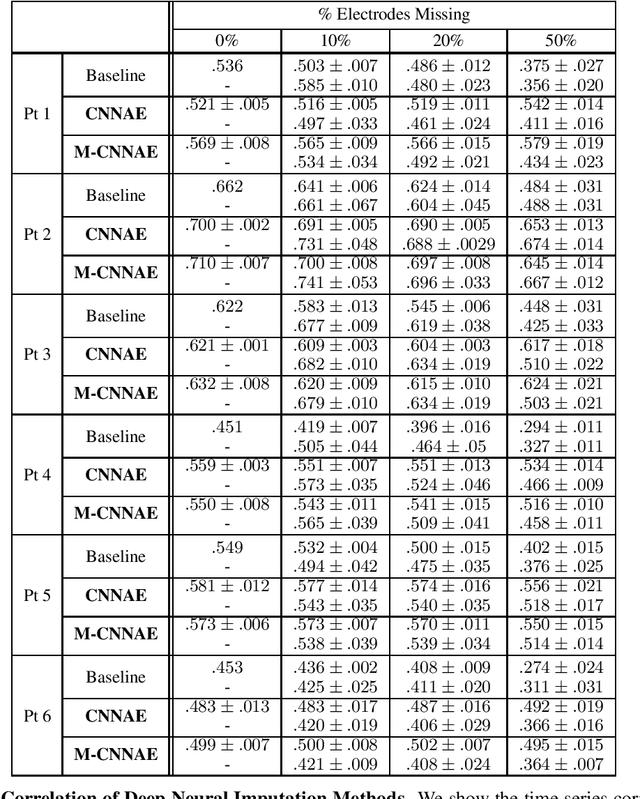
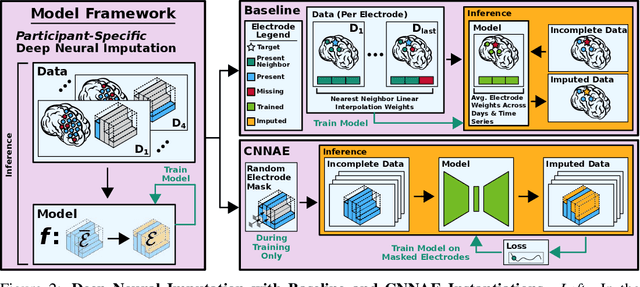
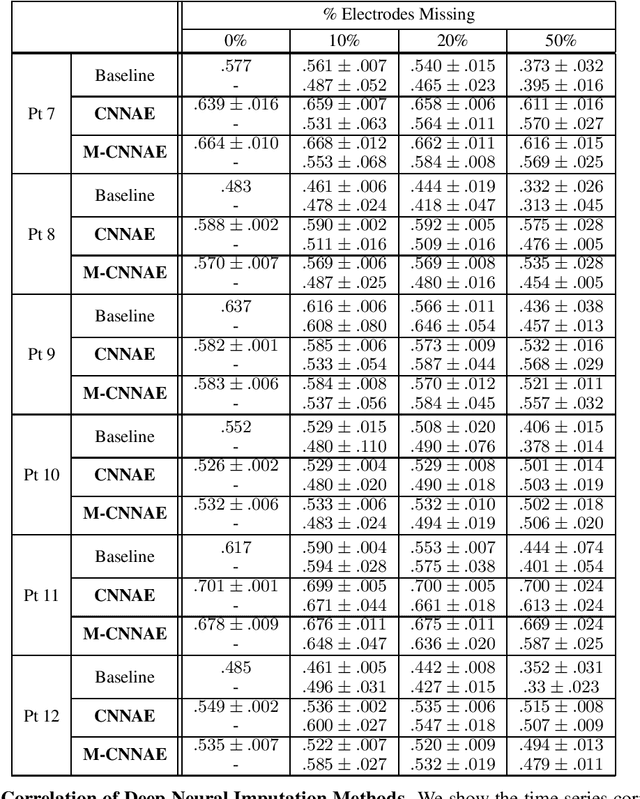
Neuroscientists and neuroengineers have long relied on multielectrode neural recordings to study the brain. However, in a typical experiment, many factors corrupt neural recordings from individual electrodes, including electrical noise, movement artifacts, and faulty manufacturing. Currently, common practice is to discard these corrupted recordings, reducing already limited data that is difficult to collect. To address this challenge, we propose Deep Neural Imputation (DNI), a framework to recover missing values from electrodes by learning from data collected across spatial locations, days, and participants. We explore our framework with a linear nearest-neighbor approach and two deep generative autoencoders, demonstrating DNI's flexibility. One deep autoencoder models participants individually, while the other extends this architecture to model many participants jointly. We evaluate our models across 12 human participants implanted with multielectrode intracranial electrocorticography arrays; participants had no explicit task and behaved naturally across hundreds of recording hours. We show that DNI recovers not only time series but also frequency content, and further establish DNI's practical value by recovering significant performance on a scientifically-relevant downstream neural decoding task.
On the Benefits of Early Fusion in Multimodal Representation Learning
Nov 14, 2020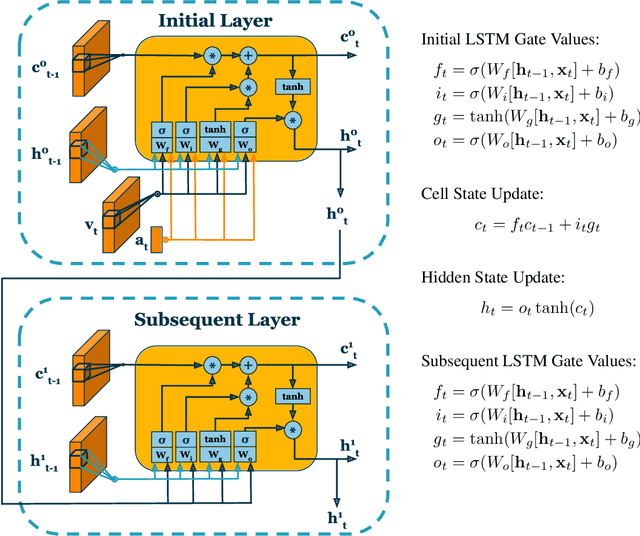
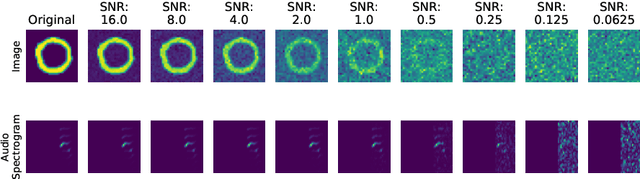
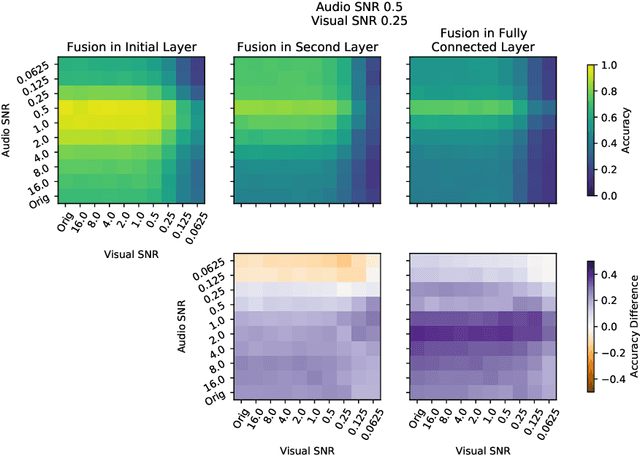
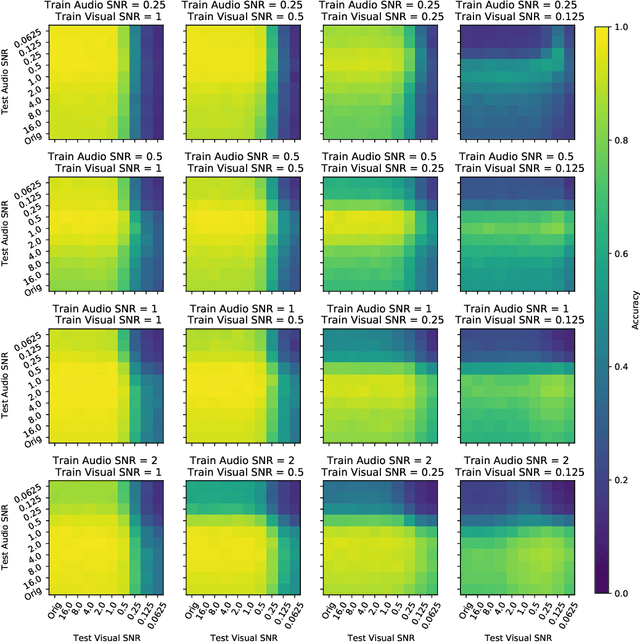
Intelligently reasoning about the world often requires integrating data from multiple modalities, as any individual modality may contain unreliable or incomplete information. Prior work in multimodal learning fuses input modalities only after significant independent processing. On the other hand, the brain performs multimodal processing almost immediately. This divide between conventional multimodal learning and neuroscience suggests that a detailed study of early multimodal fusion could improve artificial multimodal representations. To facilitate the study of early multimodal fusion, we create a convolutional LSTM network architecture that simultaneously processes both audio and visual inputs, and allows us to select the layer at which audio and visual information combines. Our results demonstrate that immediate fusion of audio and visual inputs in the initial C-LSTM layer results in higher performing networks that are more robust to the addition of white noise in both audio and visual inputs.
Architecture Agnostic Neural Networks
Nov 05, 2020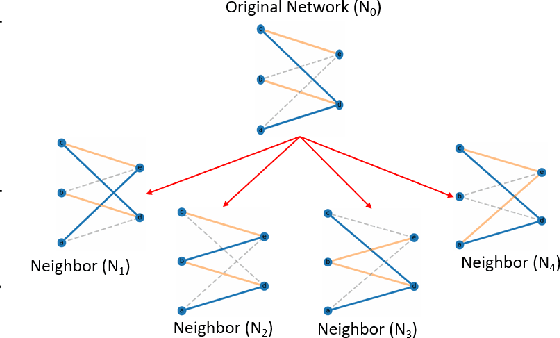
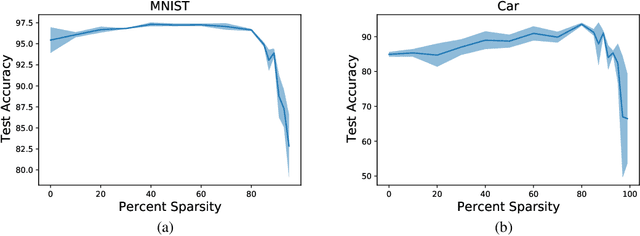
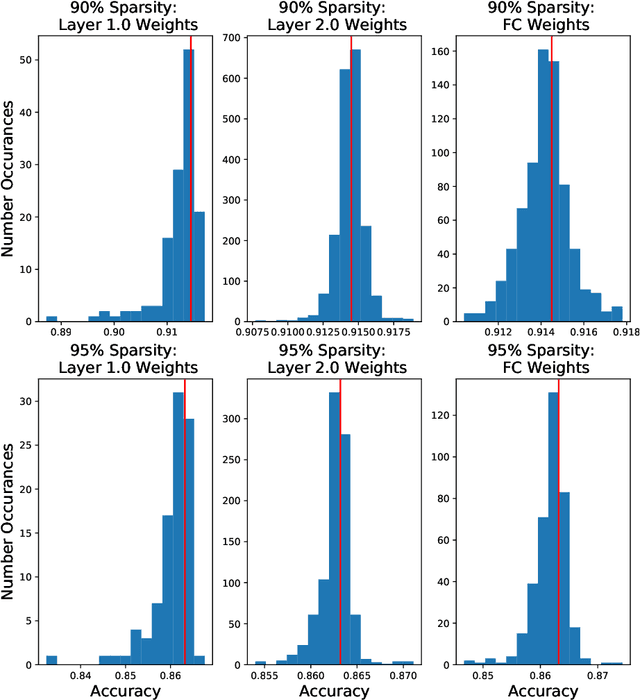
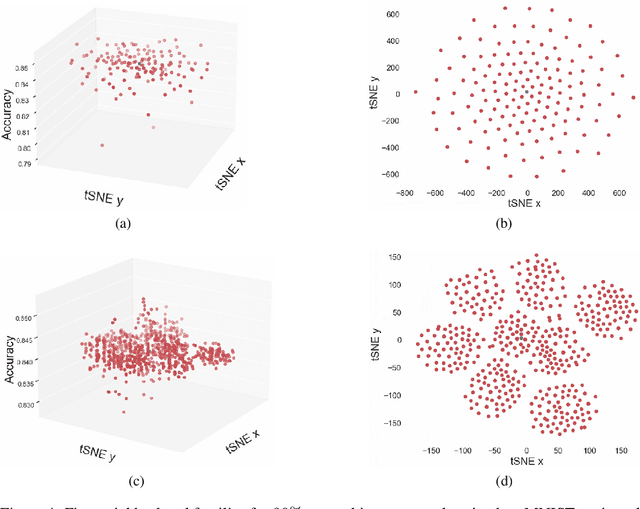
In this paper, we explore an alternate method for synthesizing neural network architectures, inspired by the brain's stochastic synaptic pruning. During a person's lifetime, numerous distinct neuronal architectures are responsible for performing the same tasks. This indicates that biological neural networks are, to some degree, architecture agnostic. However, artificial networks rely on their fine-tuned weights and hand-crafted architectures for their remarkable performance. This contrast begs the question: Can we build artificial architecture agnostic neural networks? To ground this study we utilize sparse, binary neural networks that parallel the brain's circuits. Within this sparse, binary paradigm we sample many binary architectures to create families of architecture agnostic neural networks not trained via backpropagation. These high-performing network families share the same sparsity, distribution of binary weights, and succeed in both static and dynamic tasks. In summation, we create an architecture manifold search procedure to discover families or architecture agnostic neural networks.