 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Representations in RNNs through Multi-task Learning
Jul 15, 2024



Abstract, or disentangled, representations are a promising mathematical framework for efficient and effective generalization in both biological and artificial systems. We investigate abstract representations in the context of multi-task classification over noisy evidence streams -- a canonical decision-making neuroscience paradigm. We derive theoretical bounds that guarantee the emergence of disentangled representations in the latent state of any optimal multi-task classifier, when the number of tasks exceeds the dimensionality of the state space. We experimentally confirm that RNNs trained on multi-task classification learn disentangled representations in the form of continuous attractors, leading to zero-shot out-of-distribution (OOD) generalization. We demonstrate the flexibility of the abstract RNN representations across various decision boundary geometries and in tasks requiring classification confidence estimation. Our framework suggests a general principle for the formation of cognitive maps that organize knowledge to enable flexible generalization in biological and artificial systems alike, and closely relates to representations found in humans and animals during decision-making and spatial reasoning tasks.
What's the Magic Word? A Control Theory of LLM Prompting
Oct 10, 2023Prompt engineering is effective and important in the deployment of LLMs but is poorly understood mathematically. Here, we formalize prompt engineering as an optimal control problem on LLMs -- where the prompt is considered a control variable for modulating the output distribution of the LLM. Within this framework, we ask a simple question: given a sequence of tokens, does there always exist a prompt we can prepend that will steer the LLM toward accurately predicting the final token? We call such an optimal prompt the magic word since prepending the prompt causes the LLM to output the correct answer. If magic words exist, can we find them? If so, what are their properties? We offer analytic analysis on the controllability of the self-attention head where we prove a bound on controllability as a function of the singular values of its weight matrices. We take inspiration from control theory to propose a metric called $k-\epsilon$ controllability to characterize LLM steerability. We compute the $k-\epsilon$ controllability of a panel of large language models, including Falcon-7b, Llama-7b, and Falcon-40b on 5000 WikiText causal language modeling tasks. Remarkably, we find that magic words of 10 tokens or less exist for over 97% of WikiText instances surveyed for each model.
Gradient-Free Neural Network Training via Synaptic-Level Reinforcement Learning
May 29, 2021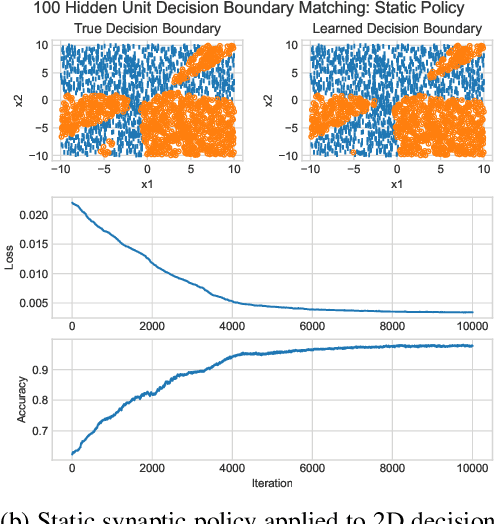

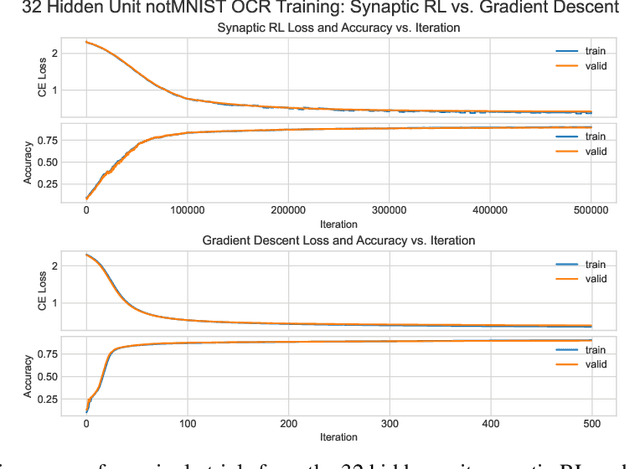
An ongoing challenge in neural information processing is: how do neurons adjust their connectivity to improve task performance over time (i.e., actualize learning)? It is widely believed that there is a consistent, synaptic-level learning mechanism in specific brain regions that actualizes learning. However, the exact nature of this mechanism remains unclear. Here we propose an algorithm based on reinforcement learning (RL) to generate and apply a simple synaptic-level learning policy for multi-layer perceptron (MLP) models. In this algorithm, the action space for each MLP synapse consists of a small increase, decrease, or null action on the synapse weight, and the state for each synapse consists of the last two actions and reward signals. A binary reward signal indicates improvement or deterioration in task performance. The static policy produces superior training relative to the adaptive policy and is agnostic to activation function, network shape, and task. Trained MLPs yield character recognition performance comparable to identically shaped networks trained with gradient descent. 0 hidden unit character recognition tests yielded an average validation accuracy of 88.28%, 1.86$\pm$0.47% higher than the same MLP trained with gradient descent. 32 hidden unit character recognition tests yielded an average validation accuracy of 88.45%, 1.11$\pm$0.79% lower than the same MLP trained with gradient descent. The robustness and lack of reliance on gradient computations opens the door for new techniques for training difficult-to-differentiate artificial neural networks such as spiking neural networks (SNNs) and recurrent neural networks (RNNs). Further, the method's simplicity provides a unique opportunity for further development of local rule-driven multi-agent connectionist models for machine intelligence analogous to cellular automata.