 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlternators With Noise Models
May 18, 2025Alternators have recently been introduced as a framework for modeling time-dependent data. They often outperform other popular frameworks, such as state-space models and diffusion models, on challenging time-series tasks. This paper introduces a new Alternator model, called Alternator++, which enhances the flexibility of traditional Alternators by explicitly modeling the noise terms used to sample the latent and observed trajectories, drawing on the idea of noise models from the diffusion modeling literature. Alternator++ optimizes the sum of the Alternator loss and a noise-matching loss. The latter forces the noise trajectories generated by the two noise models to approximate the noise trajectories that produce the observed and latent trajectories. We demonstrate the effectiveness of Alternator++ in tasks such as density estimation, time series imputation, and forecasting, showing that it outperforms several strong baselines, including Mambas, ScoreGrad, and Dyffusion.
Implicit Dynamical Flow Fusion (IDFF) for Generative Modeling
Sep 22, 2024



Conditional Flow Matching (CFM) models can generate high-quality samples from a non-informative prior, but they can be slow, often needing hundreds of network evaluations (NFE). To address this, we propose Implicit Dynamical Flow Fusion (IDFF); IDFF learns a new vector field with an additional momentum term that enables taking longer steps during sample generation while maintaining the fidelity of the generated distribution. Consequently, IDFFs reduce the NFEs by a factor of ten (relative to CFMs) without sacrificing sample quality, enabling rapid sampling and efficient handling of image and time-series data generation tasks. We evaluate IDFF on standard benchmarks such as CIFAR-10 and CelebA for image generation. We achieved likelihood and quality performance comparable to CFMs and diffusion-based models with fewer NFEs. IDFF also shows superior performance on time-series datasets modeling, including molecular simulation and sea surface temperature (SST) datasets, highlighting its versatility and effectiveness across different domains.
Latent Dynamical Implicit Diffusion Processes
Jun 12, 2023Latent dynamical models are commonly used to learn the distribution of a latent dynamical process that represents a sequence of noisy data samples. However, producing samples from such models with high fidelity is challenging due to the complexity and variability of latent and observation dynamics. Recent advances in diffusion-based generative models, such as DDPM and NCSN, have shown promising alternatives to state-of-the-art latent generative models, such as Neural ODEs, RNNs, and Normalizing flow networks, for generating high-quality sequential samples from a prior distribution. However, their application in modeling sequential data with latent dynamical models is yet to be explored. Here, we propose a novel latent variable model named latent dynamical implicit diffusion processes (LDIDPs), which utilizes implicit diffusion processes to sample from dynamical latent processes and generate sequential observation samples accordingly. We tested LDIDPs on synthetic and simulated neural decoding problems. We demonstrate that LDIDPs can accurately learn the dynamics over latent dimensions. Furthermore, the implicit sampling method allows for the computationally efficient generation of high-quality sequential data samples from the latent and observation spaces.
Reverse Survival Model (RSM): A Pipeline for Explaining Predictions of Deep Survival Models
Oct 27, 2022The aim of survival analysis in healthcare is to estimate the probability of occurrence of an event, such as a patient's death in an intensive care unit (ICU). Recent developments in deep neural networks (DNNs) for survival analysis show the superiority of these models in comparison with other well-known models in survival analysis applications. Ensuring the reliability and explainability of deep survival models deployed in healthcare is a necessity. Since DNN models often behave like a black box, their predictions might not be easily trusted by clinicians, especially when predictions are contrary to a physician's opinion. A deep survival model that explains and justifies its decision-making process could potentially gain the trust of clinicians. In this research, we propose the reverse survival model (RSM) framework that provides detailed insights into the decision-making process of survival models. For each patient of interest, RSM can extract similar patients from a dataset and rank them based on the most relevant features that deep survival models rely on for their predictions.
Deep Discriminative Direct Decoders for High-dimensional Time-series Analysis
May 22, 2022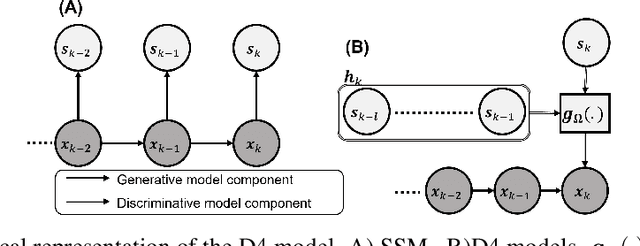
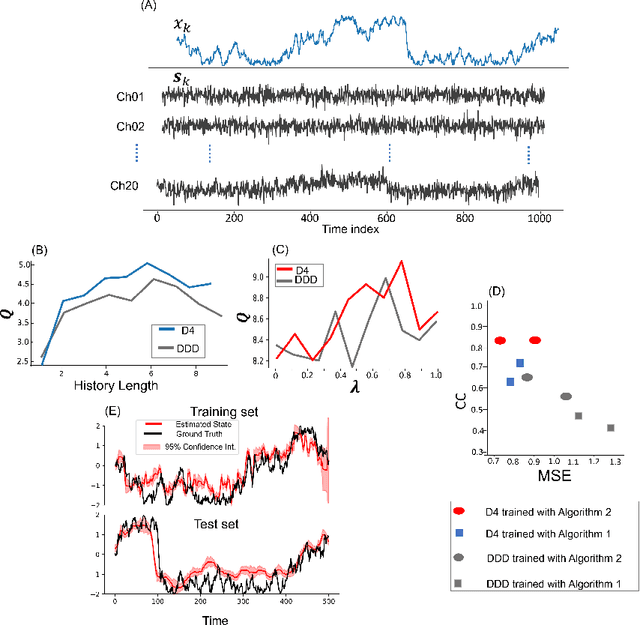
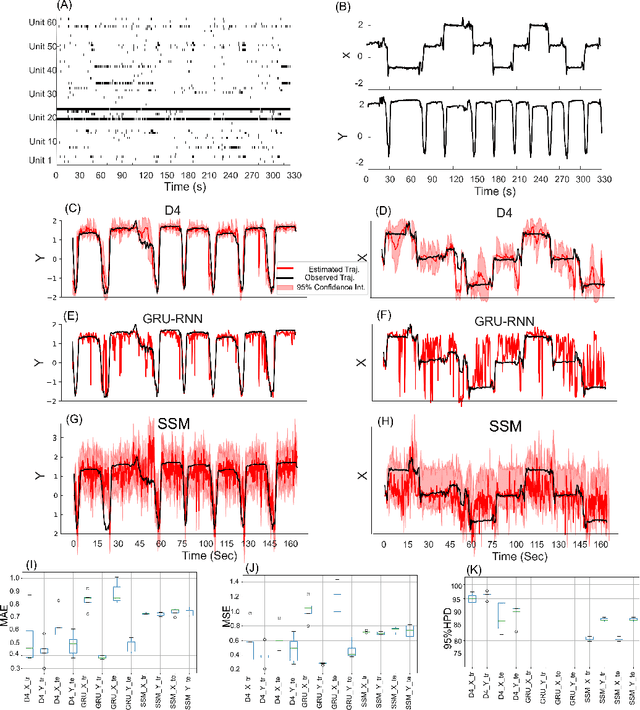
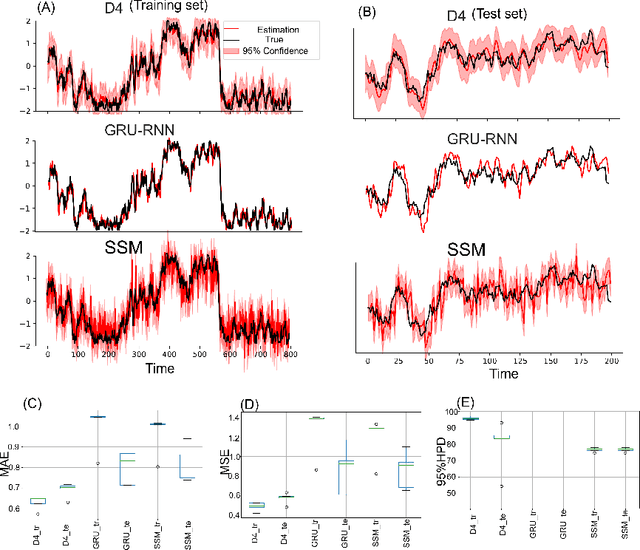
Dynamical latent variable modeling has been significantly invested over the last couple of decades with established solutions encompassing generative processes like the state-space model (SSM) and discriminative processes like a recurrent or a deep neural network (DNN). These solutions are powerful tools with promising results; however, surprisingly they were never put together in a unified model to analyze complex multivariate time-series data. A very recent modeling approach, called the direct discriminative decoder (DDD) model, proposes a principal solution to combine SMM and DNN models, with promising results in decoding underlying latent processes, e.g. rat movement trajectory, through high-dimensional neural recordings. The DDD consists of a) a state transition process, as per the classical dynamical models, and b) a discriminative process, like DNN, in which the conditional distribution of states is defined as a function of the current observations and their recent history. Despite promising results of the DDD model, no training solutions, in the context of DNN, have been utilized for this model. Here, we propose how DNN parameters along with an optimal history term can be simultaneously estimated as a part of the DDD model. We use the D4 abbreviation for a DDD with a DNN as its discriminative process. We showed the D4 decoding performance in both simulation and (relatively) high-dimensional neural data. In both datasets, D4 performance surpasses the state-of-art decoding solutions, including those of SSM and DNNs. The key success of DDD and potentially D4 is efficient utilization of the recent history of observation along with the state-process that carries long-term information, which is not addressed in either SSM or DNN solutions. We argue that D4 can be a powerful tool for the analysis of high-dimensional time-series data.
Survival Seq2Seq: A Survival Model based on Sequence to Sequence Architecture
Apr 09, 2022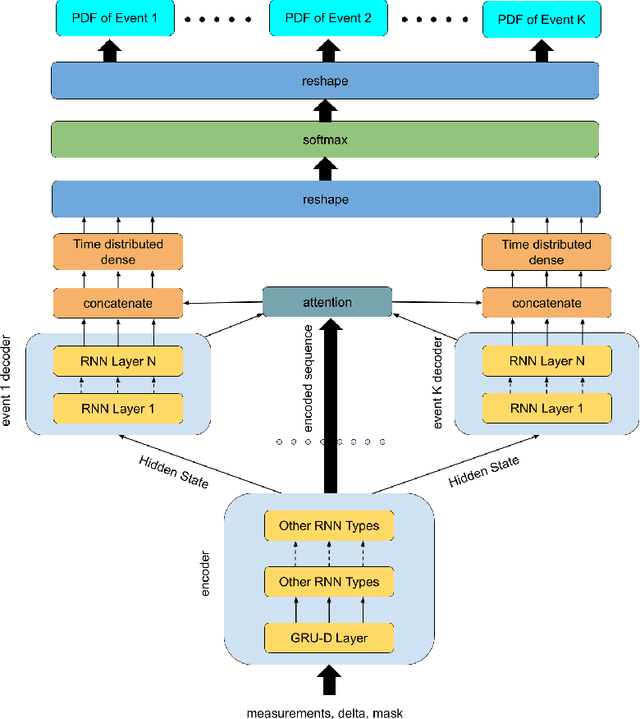
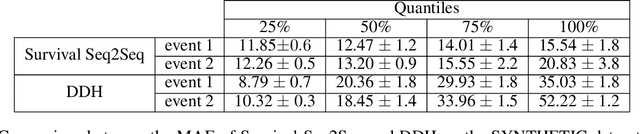
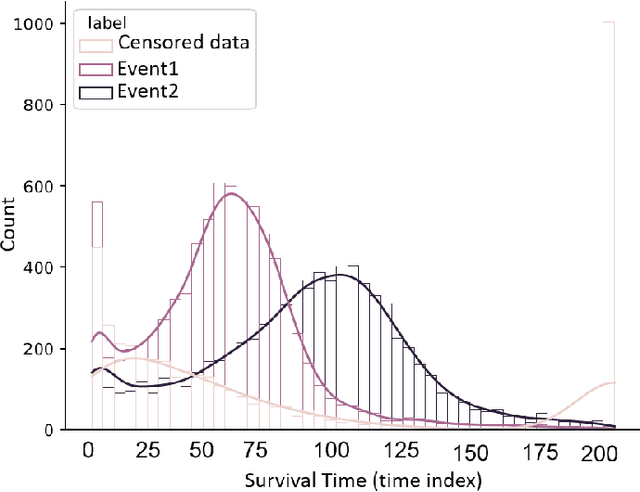
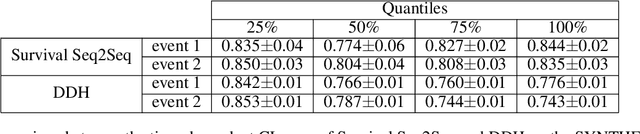
This paper introduces a novel non-parametric deep model for estimating time-to-event (survival analysis) in presence of censored data and competing risks. The model is designed based on the sequence-to-sequence (Seq2Seq) architecture, therefore we name it Survival Seq2Seq. The first recurrent neural network (RNN) layer of the encoder of our model is made up of Gated Recurrent Unit with Decay (GRU-D) cells. These cells have the ability to effectively impute not-missing-at-random values of longitudinal datasets with very high missing rates, such as electronic health records (EHRs). The decoder of Survival Seq2Seq generates a probability distribution function (PDF) for each competing risk without assuming any prior distribution for the risks. Taking advantage of RNN cells, the decoder is able to generate smooth and virtually spike-free PDFs. This is beyond the capability of existing non-parametric deep models for survival analysis. Training results on synthetic and medical datasets prove that Survival Seq2Seq surpasses other existing deep survival models in terms of the accuracy of predictions and the quality of generated PDFs.
Gradient-Free Neural Network Training via Synaptic-Level Reinforcement Learning
May 29, 2021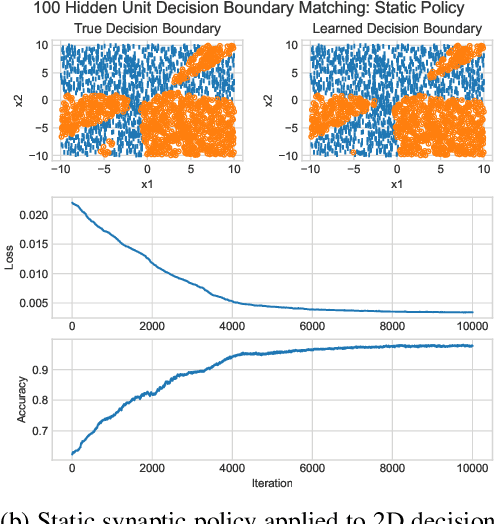

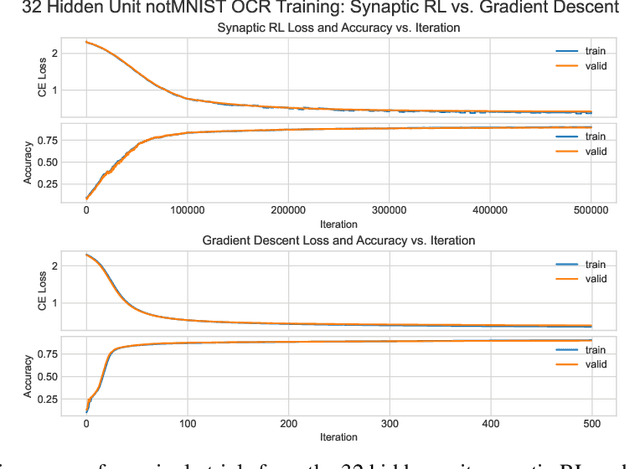
An ongoing challenge in neural information processing is: how do neurons adjust their connectivity to improve task performance over time (i.e., actualize learning)? It is widely believed that there is a consistent, synaptic-level learning mechanism in specific brain regions that actualizes learning. However, the exact nature of this mechanism remains unclear. Here we propose an algorithm based on reinforcement learning (RL) to generate and apply a simple synaptic-level learning policy for multi-layer perceptron (MLP) models. In this algorithm, the action space for each MLP synapse consists of a small increase, decrease, or null action on the synapse weight, and the state for each synapse consists of the last two actions and reward signals. A binary reward signal indicates improvement or deterioration in task performance. The static policy produces superior training relative to the adaptive policy and is agnostic to activation function, network shape, and task. Trained MLPs yield character recognition performance comparable to identically shaped networks trained with gradient descent. 0 hidden unit character recognition tests yielded an average validation accuracy of 88.28%, 1.86$\pm$0.47% higher than the same MLP trained with gradient descent. 32 hidden unit character recognition tests yielded an average validation accuracy of 88.45%, 1.11$\pm$0.79% lower than the same MLP trained with gradient descent. The robustness and lack of reliance on gradient computations opens the door for new techniques for training difficult-to-differentiate artificial neural networks such as spiking neural networks (SNNs) and recurrent neural networks (RNNs). Further, the method's simplicity provides a unique opportunity for further development of local rule-driven multi-agent connectionist models for machine intelligence analogous to cellular automata.
Amazon Product Recommender System
Jan 30, 2021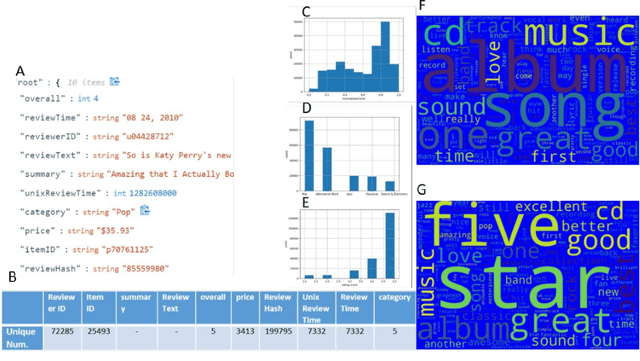
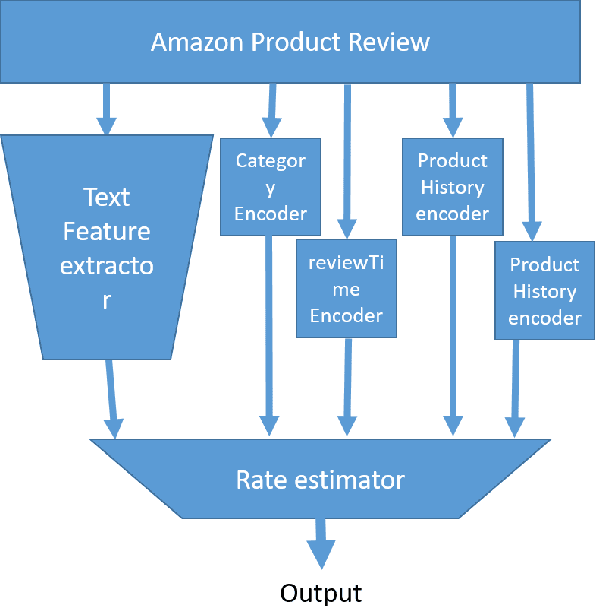
The number of reviews on Amazon has grown significantly over the years. Customers who made purchases on Amazon provide reviews by rating the product from 1 to 5 stars and sharing a text summary of their experience and opinion of the product. The ratings of a product are averaged to provide an overall product rating. We analyzed what ratings score customers give to a specific product (a music track) in order to build a recommender model for digital music tracks on Amazon. We test various traditional models along with our proposed deep neural network (DNN) architecture to predict the reviews rating score. The Amazon review dataset contains 200,000 data samples; we train the models on 70% of the dataset and test the performance of the models on the remaining 30% of the dataset.