 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAT-RAG: An Adaptive RAG Model Enhancing Query Efficiency with Topic Filtering and Iterative Reasoning
Oct 16, 2024Recent advancements in QA with LLM, like GPT-4, have shown limitations in handling complex multi-hop queries. We propose AT-RAG, a novel multistep RAG incorporating topic modeling for efficient document retrieval and reasoning. Using BERTopic, our model dynamically assigns topics to queries, improving retrieval accuracy and efficiency. We evaluated AT-RAG on multihop benchmark datasets QA and a medical case study QA. Results show significant improvements in correctness, completeness, and relevance compared to existing methods. AT-RAG reduces retrieval time while maintaining high precision, making it suitable for general tasks QA and complex domain-specific challenges such as medical QA. The integration of topic filtering and iterative reasoning enables our model to handle intricate queries efficiently, which makes it suitable for applications that require nuanced information retrieval and decision-making.
CRL+: A Novel Semi-Supervised Deep Active Contrastive Representation Learning-Based Text Classification Model for Insurance Data
Feb 08, 2023



Financial sector and especially the insurance industry collect vast volumes of text on a daily basis and through multiple channels (their agents, customer care centers, emails, social networks, and web in general). The information collected includes policies, expert and health reports, claims and complaints, results of surveys, and relevant social media posts. It is difficult to effectively extract label, classify, and interpret the essential information from such varied and unstructured material. Therefore, the Insurance Industry is among the ones that can benefit from applying technologies for the intelligent analysis of free text through Natural Language Processing (NLP). In this paper, CRL+, a novel text classification model combining Contrastive Representation Learning (CRL) and Active Learning is proposed to handle the challenge of using semi-supervised learning for text classification. In this method, supervised (CRL) is used to train a RoBERTa transformer model to encode the textual data into a contrastive representation space and then classify using a classification layer. This (CRL)-based transformer model is used as the base model in the proposed Active Learning mechanism to classify all the data in an iterative manner. The proposed model is evaluated using unstructured obituary data with objective to determine the cause of the death from the data. This model is compared with the CRL model and an Active Learning model with the RoBERTa base model. The experiment shows that the proposed method can outperform both methods for this specific task.
Reverse Survival Model (RSM): A Pipeline for Explaining Predictions of Deep Survival Models
Oct 27, 2022The aim of survival analysis in healthcare is to estimate the probability of occurrence of an event, such as a patient's death in an intensive care unit (ICU). Recent developments in deep neural networks (DNNs) for survival analysis show the superiority of these models in comparison with other well-known models in survival analysis applications. Ensuring the reliability and explainability of deep survival models deployed in healthcare is a necessity. Since DNN models often behave like a black box, their predictions might not be easily trusted by clinicians, especially when predictions are contrary to a physician's opinion. A deep survival model that explains and justifies its decision-making process could potentially gain the trust of clinicians. In this research, we propose the reverse survival model (RSM) framework that provides detailed insights into the decision-making process of survival models. For each patient of interest, RSM can extract similar patients from a dataset and rank them based on the most relevant features that deep survival models rely on for their predictions.
Survival Seq2Seq: A Survival Model based on Sequence to Sequence Architecture
Apr 09, 2022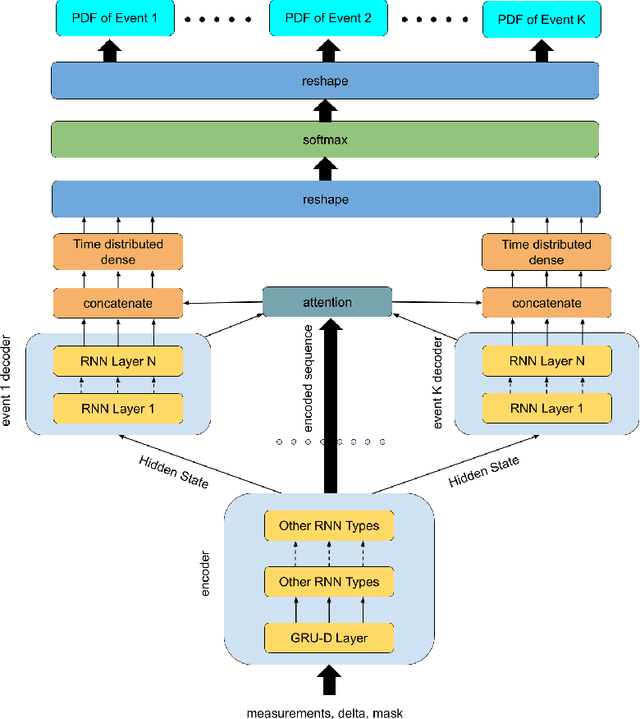
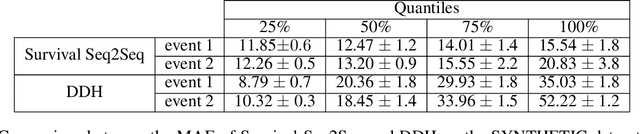
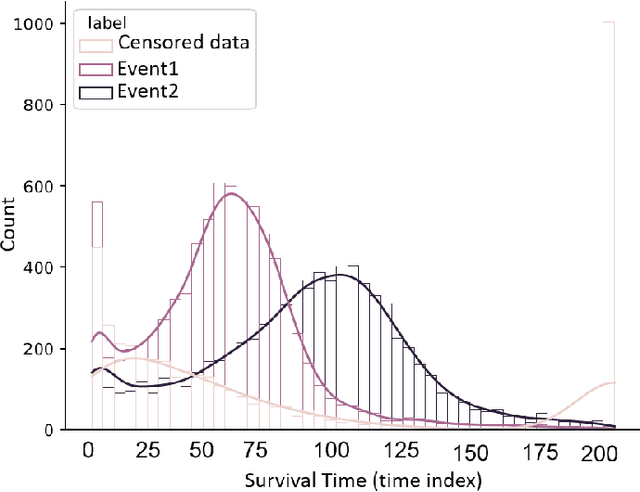
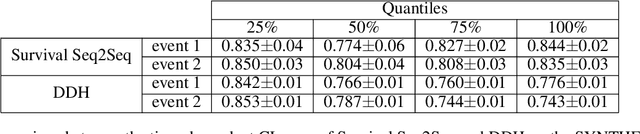
This paper introduces a novel non-parametric deep model for estimating time-to-event (survival analysis) in presence of censored data and competing risks. The model is designed based on the sequence-to-sequence (Seq2Seq) architecture, therefore we name it Survival Seq2Seq. The first recurrent neural network (RNN) layer of the encoder of our model is made up of Gated Recurrent Unit with Decay (GRU-D) cells. These cells have the ability to effectively impute not-missing-at-random values of longitudinal datasets with very high missing rates, such as electronic health records (EHRs). The decoder of Survival Seq2Seq generates a probability distribution function (PDF) for each competing risk without assuming any prior distribution for the risks. Taking advantage of RNN cells, the decoder is able to generate smooth and virtually spike-free PDFs. This is beyond the capability of existing non-parametric deep models for survival analysis. Training results on synthetic and medical datasets prove that Survival Seq2Seq surpasses other existing deep survival models in terms of the accuracy of predictions and the quality of generated PDFs.