 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic-Powered Predictive Inference
May 19, 2025Conformal prediction is a framework for predictive inference with a distribution-free, finite-sample guarantee. However, it tends to provide uninformative prediction sets when calibration data are scarce. This paper introduces Synthetic-powered predictive inference (SPPI), a novel framework that incorporates synthetic data -- e.g., from a generative model -- to improve sample efficiency. At the core of our method is a score transporter: an empirical quantile mapping that aligns nonconformity scores from trusted, real data with those from synthetic data. By carefully integrating the score transporter into the calibration process, SPPI provably achieves finite-sample coverage guarantees without making any assumptions about the real and synthetic data distributions. When the score distributions are well aligned, SPPI yields substantially tighter and more informative prediction sets than standard conformal prediction. Experiments on image classification and tabular regression demonstrate notable improvements in predictive efficiency in data-scarce settings.
Robust Conformal Outlier Detection under Contaminated Reference Data
Feb 07, 2025Conformal prediction is a flexible framework for calibrating machine learning predictions, providing distribution-free statistical guarantees. In outlier detection, this calibration relies on a reference set of labeled inlier data to control the type-I error rate. However, obtaining a perfectly labeled inlier reference set is often unrealistic, and a more practical scenario involves access to a contaminated reference set containing a small fraction of outliers. This paper analyzes the impact of such contamination on the validity of conformal methods. We prove that under realistic, non-adversarial settings, calibration on contaminated data yields conservative type-I error control, shedding light on the inherent robustness of conformal methods. This conservativeness, however, typically results in a loss of power. To alleviate this limitation, we propose a novel, active data-cleaning framework that leverages a limited labeling budget and an outlier detection model to selectively annotate data points in the contaminated reference set that are suspected as outliers. By removing only the annotated outliers in this ``suspicious'' subset, we can effectively enhance power while mitigating the risk of inflating the type-I error rate, as supported by our theoretical analysis. Experiments on real datasets validate the conservative behavior of conformal methods under contamination and show that the proposed data-cleaning strategy improves power without sacrificing validity.
Derandomized Novelty Detection with FDR Control via Conformal E-values
Feb 14, 2023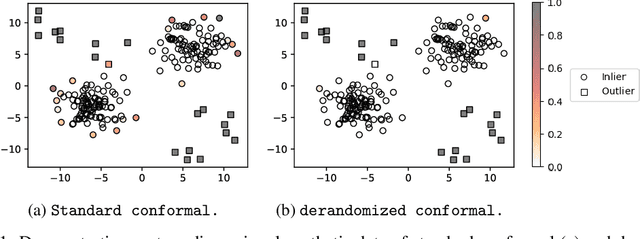
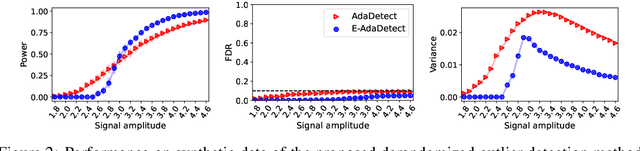
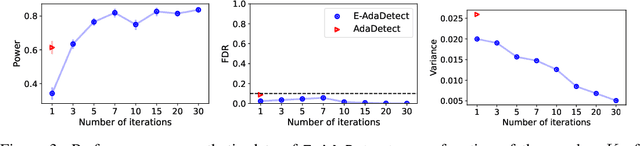
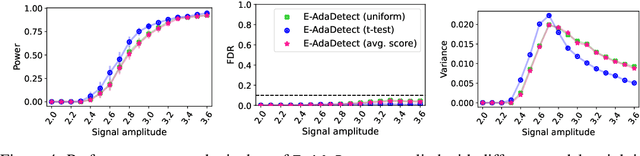
Conformal prediction and other randomized model-free inference techniques are gaining increasing attention as general solutions to rigorously calibrate the output of any machine learning algorithm for novelty detection. This paper contributes to the field by developing a novel method for mitigating their algorithmic randomness, leading to an even more interpretable and reliable framework for powerful novelty detection under false discovery rate control. The idea is to leverage suitable conformal e-values instead of p-values to quantify the significance of each finding, which allows the evidence gathered from multiple mutually dependent analyses of the same data to be seamlessly aggregated. Further, the proposed method can reduce randomness without much loss of power, partly thanks to an innovative way of weighting conformal e-values based on additional side information carefully extracted from the same data. Simulations with synthetic and real data confirm this solution can be effective at eliminating random noise in the inferences obtained with state-of-the-art alternative techniques, sometimes also leading to higher power.