 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Sequential Testing for Multi-Stream Auditing
Feb 25, 2026Across many risk-sensitive areas, it is critical to continuously audit the performance of machine learning systems and detect any unusual behavior quickly. This can be modeled as a sequential hypothesis testing problem with $k$ incoming streams of data and a global null hypothesis that asserts that the system is working as expected across all $k$ streams. The standard global test employs a Bonferroni correction and has an expected stopping time bound of $O\left(\ln\frac{k}α\right)$ when $k$ is large and the significance level of the test, $α$, is small. In this work, we construct new sequential tests by using ideas of merging test martingales with different trade-offs in expected stopping times under different, sparse or dense alternative hypotheses. We further derive a new, balanced test that achieves an improved expected stopping time bound that matches Bonferroni's in the sparse setting but that naturally results in $O\left(\frac{1}{k}\ln\frac{1}α\right)$ under a dense alternative. We empirically demonstrate the effectiveness of our proposed tests on synthetic and real-world data.
Learning Regularization Functionals for Inverse Problems: A Comparative Study
Oct 02, 2025In recent years, a variety of learned regularization frameworks for solving inverse problems in imaging have emerged. These offer flexible modeling together with mathematical insights. The proposed methods differ in their architectural design and training strategies, making direct comparison challenging due to non-modular implementations. We address this gap by collecting and unifying the available code into a common framework. This unified view allows us to systematically compare the approaches and highlight their strengths and limitations, providing valuable insights into their future potential. We also provide concise descriptions of each method, complemented by practical guidelines.
Aligning Explanations with Human Communication
May 21, 2025


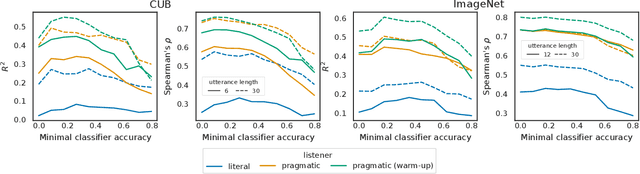
Machine learning explainability aims to make the decision-making process of black-box models more transparent by finding the most important input features for a given prediction task. Recent works have proposed composing explanations from semantic concepts (e.g., colors, patterns, shapes) that are inherently interpretable to the user of a model. However, these methods generally ignore the communicative context of explanation-the ability of the user to understand the prediction of the model from the explanation. For example, while a medical doctor might understand an explanation in terms of clinical markers, a patient may need a more accessible explanation to make sense of the same diagnosis. In this paper, we address this gap with listener-adaptive explanations. We propose an iterative procedure grounded in principles of pragmatic reasoning and the rational speech act to generate explanations that maximize communicative utility. Our procedure only needs access to pairwise preferences between candidate explanations, relevant in real-world scenarios where a listener model may not be available. We evaluate our method in image classification tasks, demonstrating improved alignment between explanations and listener preferences across three datasets. Furthermore, we perform a user study that demonstrates our explanations increase communicative utility.
Multiaccuracy and Multicalibration via Proxy Groups
Mar 05, 2025As the use of predictive machine learning algorithms increases in high-stakes decision-making, it is imperative that these algorithms are fair across sensitive groups. Unfortunately, measuring and enforcing fairness in real-world applications can be challenging due to missing or incomplete sensitive group data. Proxy-sensitive attributes have been proposed as a practical and effective solution in these settings, but only for parity-based fairness notions. Knowing how to evaluate and control for fairness with missing sensitive group data for newer and more flexible frameworks, such as multiaccuracy and multicalibration, remains unexplored. In this work, we address this gap by demonstrating that in the absence of sensitive group data, proxy-sensitive attributes can provably be used to derive actionable upper bounds on the true multiaccuracy and multicalibration, providing insights into a model's potential worst-case fairness violations. Additionally, we show that adjusting models to satisfy multiaccuracy and multicalibration across proxy-sensitive attributes can significantly mitigate these violations for the true, but unknown, sensitive groups. Through several experiments on real-world datasets, we illustrate that approximate multiaccuracy and multicalibration can be achieved even when sensitive group information is incomplete or unavailable.
Disentangling Safe and Unsafe Corruptions via Anisotropy and Locality
Jan 30, 2025



State-of-the-art machine learning systems are vulnerable to small perturbations to their input, where ``small'' is defined according to a threat model that assigns a positive threat to each perturbation. Most prior works define a task-agnostic, isotropic, and global threat, like the $\ell_p$ norm, where the magnitude of the perturbation fully determines the degree of the threat and neither the direction of the attack nor its position in space matter. However, common corruptions in computer vision, such as blur, compression, or occlusions, are not well captured by such threat models. This paper proposes a novel threat model called \texttt{Projected Displacement} (PD) to study robustness beyond existing isotropic and global threat models. The proposed threat model measures the threat of a perturbation via its alignment with \textit{unsafe directions}, defined as directions in the input space along which a perturbation of sufficient magnitude changes the ground truth class label. Unsafe directions are identified locally for each input based on observed training data. In this way, the PD threat model exhibits anisotropy and locality. Experiments on Imagenet-1k data indicate that, for any input, the set of perturbations with small PD threat includes \textit{safe} perturbations of large $\ell_p$ norm that preserve the true label, such as noise, blur and compression, while simultaneously excluding \textit{unsafe} perturbations that alter the true label. Unlike perceptual threat models based on embeddings of large-vision models, the PD threat model can be readily computed for arbitrary classification tasks without pre-training or finetuning. Further additional task annotation such as sensitivity to image regions or concept hierarchies can be easily integrated into the assessment of threat and thus the PD threat model presents practitioners with a flexible, task-driven threat specification.
Sufficient and Necessary Explanations (and What Lies in Between)
Sep 30, 2024As complex machine learning models continue to find applications in high-stakes decision-making scenarios, it is crucial that we can explain and understand their predictions. Post-hoc explanation methods provide useful insights by identifying important features in an input $\mathbf{x}$ with respect to the model output $f(\mathbf{x})$. In this work, we formalize and study two precise notions of feature importance for general machine learning models: sufficiency and necessity. We demonstrate how these two types of explanations, albeit intuitive and simple, can fall short in providing a complete picture of which features a model finds important. To this end, we propose a unified notion of importance that circumvents these limitations by exploring a continuum along a necessity-sufficiency axis. Our unified notion, we show, has strong ties to other popular definitions of feature importance, like those based on conditional independence and game-theoretic quantities like Shapley values. Crucially, we demonstrate how a unified perspective allows us to detect important features that could be missed by either of the previous approaches alone.
Pivotal Auto-Encoder via Self-Normalizing ReLU
Jun 23, 2024



Sparse auto-encoders are useful for extracting low-dimensional representations from high-dimensional data. However, their performance degrades sharply when the input noise at test time differs from the noise employed during training. This limitation hinders the applicability of auto-encoders in real-world scenarios where the level of noise in the input is unpredictable. In this paper, we formalize single hidden layer sparse auto-encoders as a transform learning problem. Leveraging the transform modeling interpretation, we propose an optimization problem that leads to a predictive model invariant to the noise level at test time. In other words, the same pre-trained model is able to generalize to different noise levels. The proposed optimization algorithm, derived from the square root lasso, is translated into a new, computationally efficient auto-encoding architecture. After proving that our new method is invariant to the noise level, we evaluate our approach by training networks using the proposed architecture for denoising tasks. Our experimental results demonstrate that the trained models yield a significant improvement in stability against varying types of noise compared to commonly used architectures.
I Bet You Did Not Mean That: Testing Semantic Importance via Betting
May 29, 2024



Recent works have extended notions of feature importance to \emph{semantic concepts} that are inherently interpretable to the users interacting with a black-box predictive model. Yet, precise statistical guarantees, such as false positive rate control, are needed to communicate findings transparently and to avoid unintended consequences in real-world scenarios. In this paper, we formalize the global (i.e., over a population) and local (i.e., for a sample) statistical importance of semantic concepts for the predictions of opaque models, by means of conditional independence, which allows for rigorous testing. We use recent ideas of sequential kernelized testing (SKIT) to induce a rank of importance across concepts, and showcase the effectiveness and flexibility of our framework on synthetic datasets as well as on image classification tasks using vision-language models such as CLIP.
Certified Robustness against Sparse Adversarial Perturbations via Data Localization
May 23, 2024



Recent work in adversarial robustness suggests that natural data distributions are localized, i.e., they place high probability in small volume regions of the input space, and that this property can be utilized for designing classifiers with improved robustness guarantees for $\ell_2$-bounded perturbations. Yet, it is still unclear if this observation holds true for more general metrics. In this work, we extend this theory to $\ell_0$-bounded adversarial perturbations, where the attacker can modify a few pixels of the image but is unrestricted in the magnitude of perturbation, and we show necessary and sufficient conditions for the existence of $\ell_0$-robust classifiers. Theoretical certification approaches in this regime essentially employ voting over a large ensemble of classifiers. Such procedures are combinatorial and expensive or require complicated certification techniques. In contrast, a simple classifier emerges from our theory, dubbed Box-NN, which naturally incorporates the geometry of the problem and improves upon the current state-of-the-art in certified robustness against sparse attacks for the MNIST and Fashion-MNIST datasets.
What's in a Prior? Learned Proximal Networks for Inverse Problems
Oct 22, 2023



Proximal operators are ubiquitous in inverse problems, commonly appearing as part of algorithmic strategies to regularize problems that are otherwise ill-posed. Modern deep learning models have been brought to bear for these tasks too, as in the framework of plug-and-play or deep unrolling, where they loosely resemble proximal operators. Yet, something essential is lost in employing these purely data-driven approaches: there is no guarantee that a general deep network represents the proximal operator of any function, nor is there any characterization of the function for which the network might provide some approximate proximal. This not only makes guaranteeing convergence of iterative schemes challenging but, more fundamentally, complicates the analysis of what has been learned by these networks about their training data. Herein we provide a framework to develop learned proximal networks (LPN), prove that they provide exact proximal operators for a data-driven nonconvex regularizer, and show how a new training strategy, dubbed proximal matching, provably promotes the recovery of the log-prior of the true data distribution. Such LPN provide general, unsupervised, expressive proximal operators that can be used for general inverse problems with convergence guarantees. We illustrate our results in a series of cases of increasing complexity, demonstrating that these models not only result in state-of-the-art performance, but provide a window into the resulting priors learned from data.