 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNIStainNet: Foundation-Model-Guided Virtual Staining of H&E to IHC
Mar 13, 2026Virtual immunohistochemistry (IHC) staining from hematoxylin and eosin (H&E) images can accelerate diagnostics by providing preliminary molecular insight directly from routine sections, reducing the need for repeat sectioning when tissue is limited. Existing methods improve realism through contrastive objectives, prototype matching, or domain alignment, yet the generator itself receives no direct guidance from pathology foundation models. We present UNIStainNet, a SPADE-UNet conditioned on dense spatial tokens from a frozen pathology foundation model (UNI), providing tissue-level semantic guidance for stain translation. A misalignment-aware loss suite preserves stain quantification accuracy, and learned stain embeddings enable a single model to serve multiple IHC markers simultaneously. On MIST, UNIStainNet achieves state-of-the-art distributional metrics on all four stains (HER2, Ki67, ER, PR) from a single unified model, where prior methods typically train separate per-stain models. On BCI, it also achieves the best distributional metrics. A tissue-type stratified failure analysis reveals that remaining errors are systematic, concentrating in non-tumor tissue. Code is available at https://github.com/facevoid/UNIStainNet.
Sufficient and Necessary Explanations (and What Lies in Between)
Sep 30, 2024As complex machine learning models continue to find applications in high-stakes decision-making scenarios, it is crucial that we can explain and understand their predictions. Post-hoc explanation methods provide useful insights by identifying important features in an input $\mathbf{x}$ with respect to the model output $f(\mathbf{x})$. In this work, we formalize and study two precise notions of feature importance for general machine learning models: sufficiency and necessity. We demonstrate how these two types of explanations, albeit intuitive and simple, can fall short in providing a complete picture of which features a model finds important. To this end, we propose a unified notion of importance that circumvents these limitations by exploring a continuum along a necessity-sufficiency axis. Our unified notion, we show, has strong ties to other popular definitions of feature importance, like those based on conditional independence and game-theoretic quantities like Shapley values. Crucially, we demonstrate how a unified perspective allows us to detect important features that could be missed by either of the previous approaches alone.
Estimating and Controlling for Fairness via Sensitive Attribute Predictors
Jul 25, 2022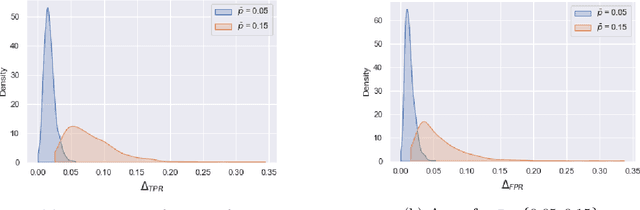
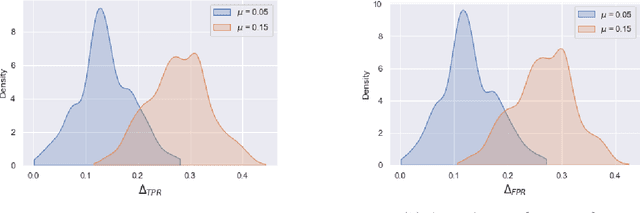
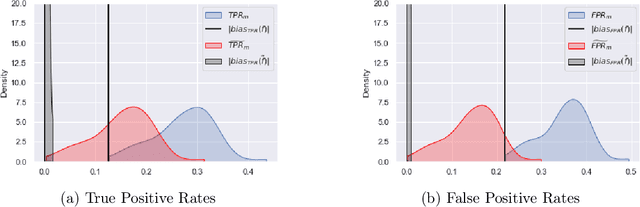
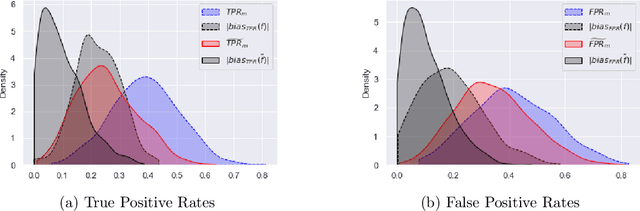
Although machine learning classifiers have been increasingly used in high-stakes decision making (e.g., cancer diagnosis, criminal prosecution decisions), they have demonstrated biases against underrepresented groups. Standard definitions of fairness require access to sensitive attributes of interest (e.g., gender and race), which are often unavailable. In this work we demonstrate that in these settings where sensitive attributes are unknown, one can still reliably estimate and ultimately control for fairness by using proxy sensitive attributes derived from a sensitive attribute predictor. Specifically, we first show that with just a little knowledge of the complete data distribution, one may use a sensitive attribute predictor to obtain upper and lower bounds of the classifier's true fairness metric. Second, we demonstrate how one can provably control for fairness with respect to the true sensitive attributes by controlling for fairness with respect to the proxy sensitive attributes. Our results hold under assumptions that are significantly milder than previous works. We illustrate our results on a series of synthetic and real datasets.