 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating and Controlling for Fairness via Sensitive Attribute Predictors
Paper and Code
Jul 25, 2022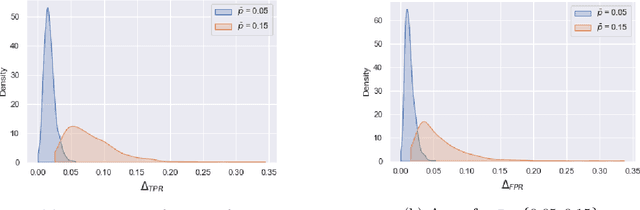
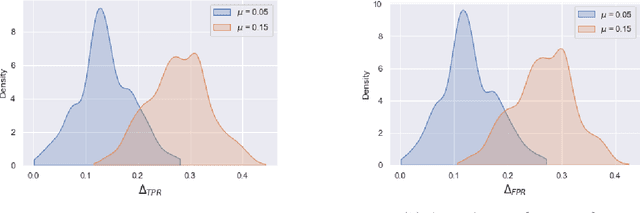
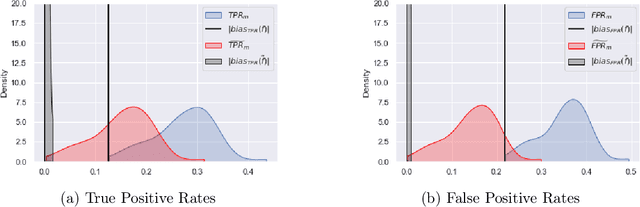
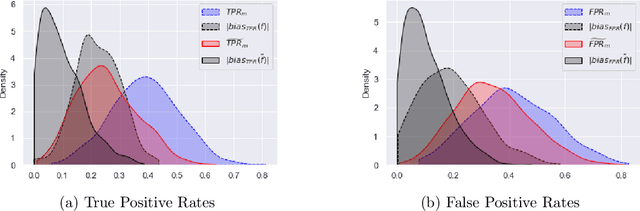
Although machine learning classifiers have been increasingly used in high-stakes decision making (e.g., cancer diagnosis, criminal prosecution decisions), they have demonstrated biases against underrepresented groups. Standard definitions of fairness require access to sensitive attributes of interest (e.g., gender and race), which are often unavailable. In this work we demonstrate that in these settings where sensitive attributes are unknown, one can still reliably estimate and ultimately control for fairness by using proxy sensitive attributes derived from a sensitive attribute predictor. Specifically, we first show that with just a little knowledge of the complete data distribution, one may use a sensitive attribute predictor to obtain upper and lower bounds of the classifier's true fairness metric. Second, we demonstrate how one can provably control for fairness with respect to the true sensitive attributes by controlling for fairness with respect to the proxy sensitive attributes. Our results hold under assumptions that are significantly milder than previous works. We illustrate our results on a series of synthetic and real datasets.