 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Free and Group Conditional Online Conformal Prediction
May 29, 2026Uncertainty quantification (UQ) is critical for the deployment of machine learning predictors in real-world scenarios where the data distribution may shift over time (i.e., data may not be exchangeable). Online conformal prediction (OCP) methods address this issue at the expense of either (i) group-wise error control or (ii) learning-rate independent implementation. Group-conditional coverage is essential for fairness across different collections of data points and for providing finer UQ guarantees. Parameter-free optimization is crucial for robustness to adversarial and unknown data shifts. We propose a parameter-free algorithm for group-conditional OCP and demonstrate that it achieves the best group-conditional coverage guarantees.We evaluate our algorithm on synthetic and real-world data, demonstrating that our method not only improves the reliability of existing parameter-free OCP methods but also provides prediction intervals that are comparable in size to well-tuned group-conditional approaches. By unifying group-conditional coverage with parameter-free online algorithms, our work lays a foundation for fair and robust uncertainty quantification in shifting environments.
Global Sequential Testing for Multi-Stream Auditing
Feb 25, 2026Across many risk-sensitive areas, it is critical to continuously audit the performance of machine learning systems and detect any unusual behavior quickly. This can be modeled as a sequential hypothesis testing problem with $k$ incoming streams of data and a global null hypothesis that asserts that the system is working as expected across all $k$ streams. The standard global test employs a Bonferroni correction and has an expected stopping time bound of $O\left(\ln\frac{k}α\right)$ when $k$ is large and the significance level of the test, $α$, is small. In this work, we construct new sequential tests by using ideas of merging test martingales with different trade-offs in expected stopping times under different, sparse or dense alternative hypotheses. We further derive a new, balanced test that achieves an improved expected stopping time bound that matches Bonferroni's in the sparse setting but that naturally results in $O\left(\frac{1}{k}\ln\frac{1}α\right)$ under a dense alternative. We empirically demonstrate the effectiveness of our proposed tests on synthetic and real-world data.
Identifying Physically Realizable Triggers for Backdoored Face Recognition Networks
Jun 24, 2025


Backdoor attacks embed a hidden functionality into deep neural networks, causing the network to display anomalous behavior when activated by a predetermined pattern in the input Trigger, while behaving well otherwise on public test data. Recent works have shown that backdoored face recognition (FR) systems can respond to natural-looking triggers like a particular pair of sunglasses. Such attacks pose a serious threat to the applicability of FR systems in high-security applications. We propose a novel technique to (1) detect whether an FR network is compromised with a natural, physically realizable trigger, and (2) identify such triggers given a compromised network. We demonstrate the effectiveness of our methods with a compromised FR network, where we are able to identify the trigger (e.g., green sunglasses or red hat) with a top-5 accuracy of 74%, whereas a naive brute force baseline achieves 56% accuracy.
Disentangling Safe and Unsafe Corruptions via Anisotropy and Locality
Jan 30, 2025



State-of-the-art machine learning systems are vulnerable to small perturbations to their input, where ``small'' is defined according to a threat model that assigns a positive threat to each perturbation. Most prior works define a task-agnostic, isotropic, and global threat, like the $\ell_p$ norm, where the magnitude of the perturbation fully determines the degree of the threat and neither the direction of the attack nor its position in space matter. However, common corruptions in computer vision, such as blur, compression, or occlusions, are not well captured by such threat models. This paper proposes a novel threat model called \texttt{Projected Displacement} (PD) to study robustness beyond existing isotropic and global threat models. The proposed threat model measures the threat of a perturbation via its alignment with \textit{unsafe directions}, defined as directions in the input space along which a perturbation of sufficient magnitude changes the ground truth class label. Unsafe directions are identified locally for each input based on observed training data. In this way, the PD threat model exhibits anisotropy and locality. Experiments on Imagenet-1k data indicate that, for any input, the set of perturbations with small PD threat includes \textit{safe} perturbations of large $\ell_p$ norm that preserve the true label, such as noise, blur and compression, while simultaneously excluding \textit{unsafe} perturbations that alter the true label. Unlike perceptual threat models based on embeddings of large-vision models, the PD threat model can be readily computed for arbitrary classification tasks without pre-training or finetuning. Further additional task annotation such as sensitivity to image regions or concept hierarchies can be easily integrated into the assessment of threat and thus the PD threat model presents practitioners with a flexible, task-driven threat specification.
Certified Robustness against Sparse Adversarial Perturbations via Data Localization
May 23, 2024



Recent work in adversarial robustness suggests that natural data distributions are localized, i.e., they place high probability in small volume regions of the input space, and that this property can be utilized for designing classifiers with improved robustness guarantees for $\ell_2$-bounded perturbations. Yet, it is still unclear if this observation holds true for more general metrics. In this work, we extend this theory to $\ell_0$-bounded adversarial perturbations, where the attacker can modify a few pixels of the image but is unrestricted in the magnitude of perturbation, and we show necessary and sufficient conditions for the existence of $\ell_0$-robust classifiers. Theoretical certification approaches in this regime essentially employ voting over a large ensemble of classifiers. Such procedures are combinatorial and expensive or require complicated certification techniques. In contrast, a simple classifier emerges from our theory, dubbed Box-NN, which naturally incorporates the geometry of the problem and improves upon the current state-of-the-art in certified robustness against sparse attacks for the MNIST and Fashion-MNIST datasets.
Adversarial Examples Might be Avoidable: The Role of Data Concentration in Adversarial Robustness
Sep 28, 2023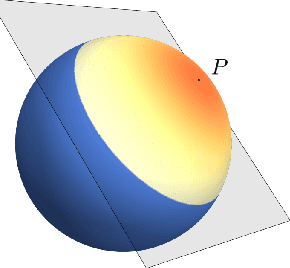
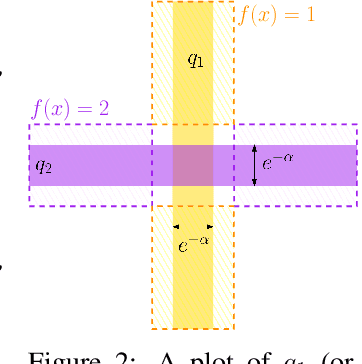
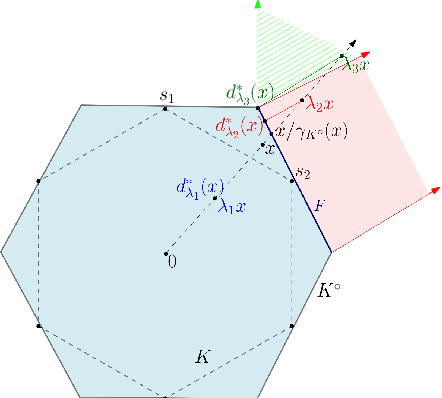
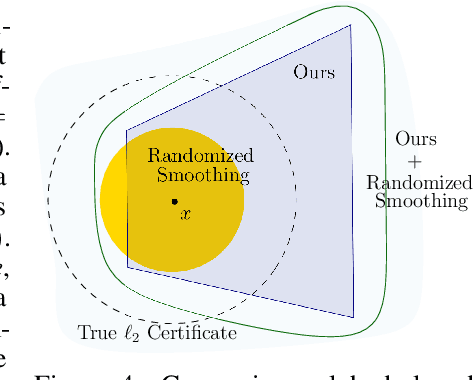
The susceptibility of modern machine learning classifiers to adversarial examples has motivated theoretical results suggesting that these might be unavoidable. However, these results can be too general to be applicable to natural data distributions. Indeed, humans are quite robust for tasks involving vision. This apparent conflict motivates a deeper dive into the question: Are adversarial examples truly unavoidable? In this work, we theoretically demonstrate that a key property of the data distribution -- concentration on small-volume subsets of the input space -- determines whether a robust classifier exists. We further demonstrate that, for a data distribution concentrated on a union of low-dimensional linear subspaces, exploiting data structure naturally leads to classifiers that enjoy good robustness guarantees, improving upon methods for provable certification in certain regimes.
Understanding Noise-Augmented Training for Randomized Smoothing
May 08, 2023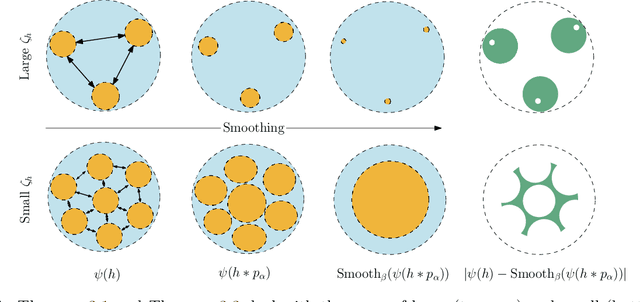
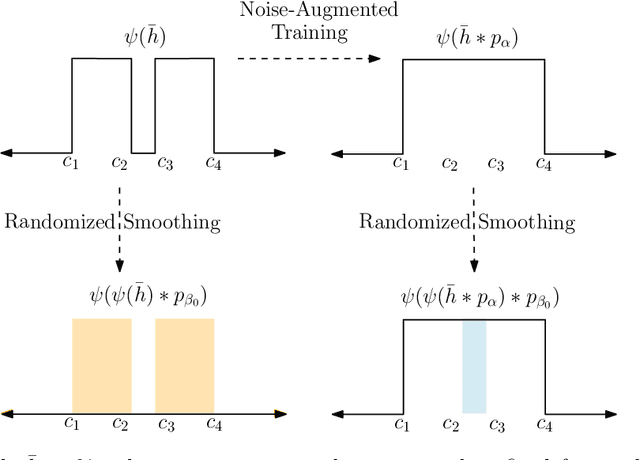
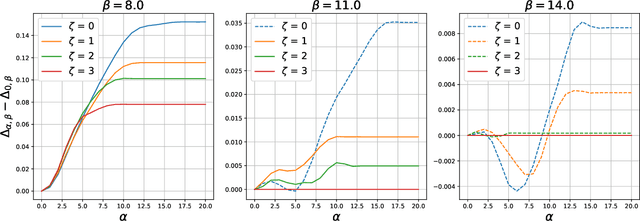
Randomized smoothing is a technique for providing provable robustness guarantees against adversarial attacks while making minimal assumptions about a classifier. This method relies on taking a majority vote of any base classifier over multiple noise-perturbed inputs to obtain a smoothed classifier, and it remains the tool of choice to certify deep and complex neural network models. Nonetheless, non-trivial performance of such smoothed classifier crucially depends on the base model being trained on noise-augmented data, i.e., on a smoothed input distribution. While widely adopted in practice, it is still unclear how this noisy training of the base classifier precisely affects the risk of the robust smoothed classifier, leading to heuristics and tricks that are poorly understood. In this work we analyze these trade-offs theoretically in a binary classification setting, proving that these common observations are not universal. We show that, without making stronger distributional assumptions, no benefit can be expected from predictors trained with noise-augmentation, and we further characterize distributions where such benefit is obtained. Our analysis has direct implications to the practical deployment of randomized smoothing, and we illustrate some of these via experiments on CIFAR-10 and MNIST, as well as on synthetic datasets.
On Utilizing Relationships for Transferable Few-Shot Fine-Grained Object Detection
Dec 01, 2022
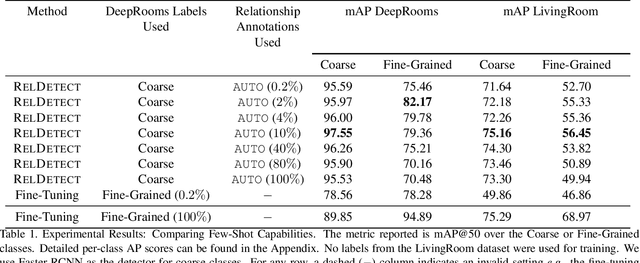
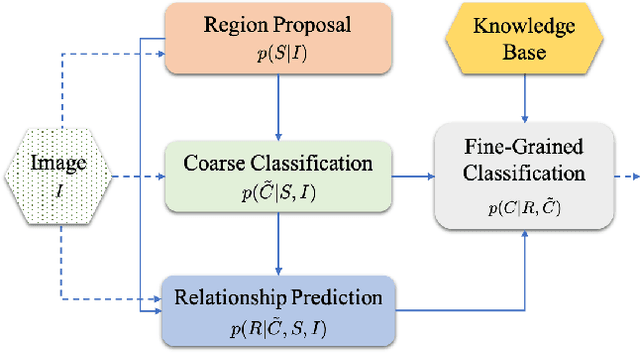
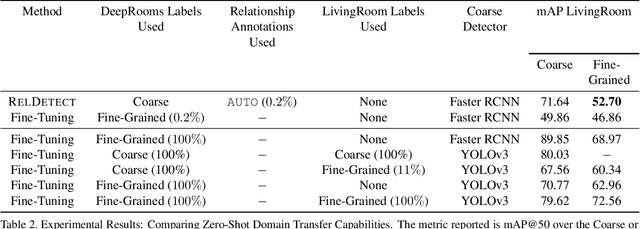
State-of-the-art object detectors are fast and accurate, but they require a large amount of well annotated training data to obtain good performance. However, obtaining a large amount of training annotations specific to a particular task, i.e., fine-grained annotations, is costly in practice. In contrast, obtaining common-sense relationships from text, e.g., "a table-lamp is a lamp that sits on top of a table", is much easier. Additionally, common-sense relationships like "on-top-of" are easy to annotate in a task-agnostic fashion. In this paper, we propose a probabilistic model that uses such relational knowledge to transform an off-the-shelf detector of coarse object categories (e.g., "table", "lamp") into a detector of fine-grained categories (e.g., "table-lamp"). We demonstrate that our method, RelDetect, achieves performance competitive to finetuning based state-of-the-art object detector baselines when an extremely low amount of fine-grained annotations is available ($0.2\%$ of entire dataset). We also demonstrate that RelDetect is able to utilize the inherent transferability of relationship information to obtain a better performance ($+5$ mAP points) than the above baselines on an unseen dataset (zero-shot transfer). In summary, we demonstrate the power of using relationships for object detection on datasets where fine-grained object categories can be linked to coarse-grained categories via suitable relationships.
A Game Theoretic Analysis of Additive Adversarial Attacks and Defenses
Sep 14, 2020


Research in adversarial learning follows a cat and mouse game between attackers and defenders where attacks are proposed, they are mitigated by new defenses, and subsequently new attacks are proposed that break earlier defenses, and so on. However, it has remained unclear as to whether there are conditions under which no better attacks or defenses can be proposed. In this paper, we propose a game-theoretic framework for studying attacks and defenses which exist in equilibrium. Under a locally linear decision boundary model for the underlying binary classifier, we prove that the Fast Gradient Method attack and the Randomized Smoothing defense form a Nash Equilibrium. We then show how this equilibrium defense can be approximated given finitely many samples from a data-generating distribution, and derive a generalization bound for the performance of our approximation.
On the Regularization Properties of Structured Dropout
Oct 30, 2019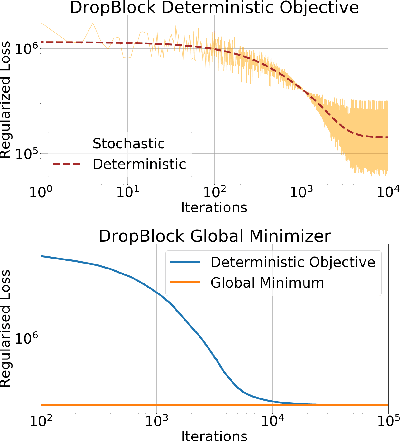
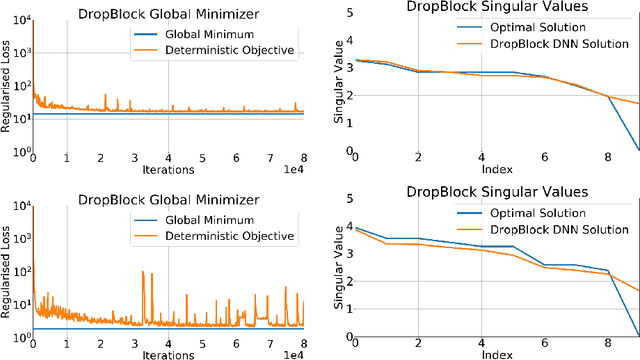
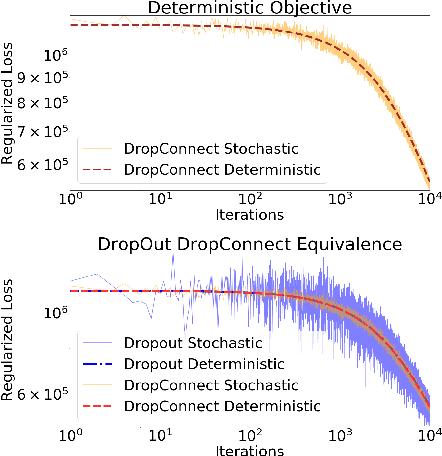
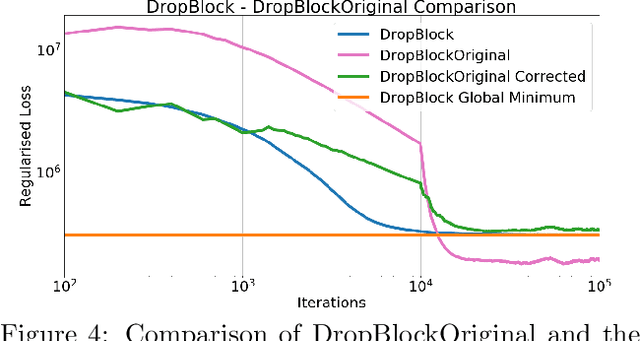
Dropout and its extensions (eg. DropBlock and DropConnect) are popular heuristics for training neural networks, which have been shown to improve generalization performance in practice. However, a theoretical understanding of their optimization and regularization properties remains elusive. Recent work shows that in the case of single hidden-layer linear networks, Dropout is a stochastic gradient descent method for minimizing a regularized loss, and that the regularizer induces solutions that are low-rank and balanced. In this work we show that for single hidden-layer linear networks, DropBlock induces spectral k-support norm regularization, and promotes solutions that are low-rank and have factors with equal norm. We also show that the global minimizer for DropBlock can be computed in closed form, and that DropConnect is equivalent to Dropout. We then show that some of these results can be extended to a general class of Dropout-strategies, and, with some assumptions, to deep non-linear networks when Dropout is applied to the last layer. We verify our theoretical claims and assumptions experimentally with commonly used network architectures.