 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Regularization Properties of Structured Dropout
Paper and Code
Oct 30, 2019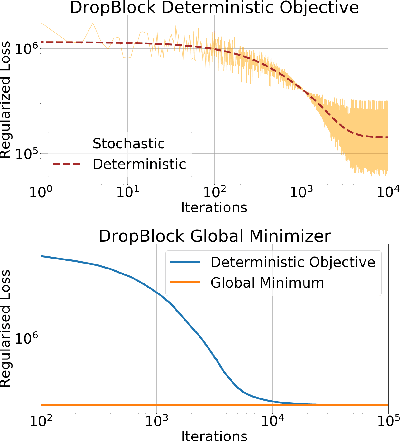
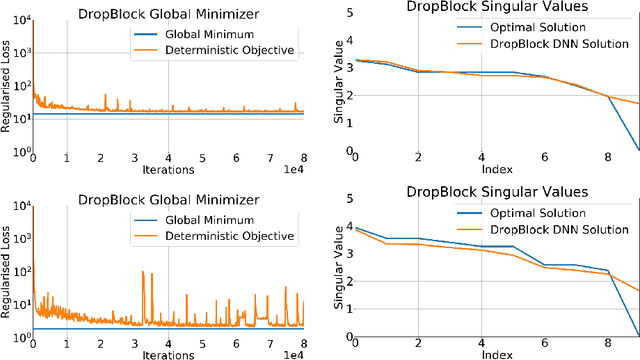
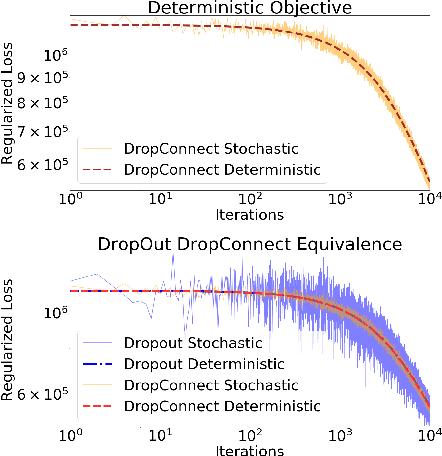
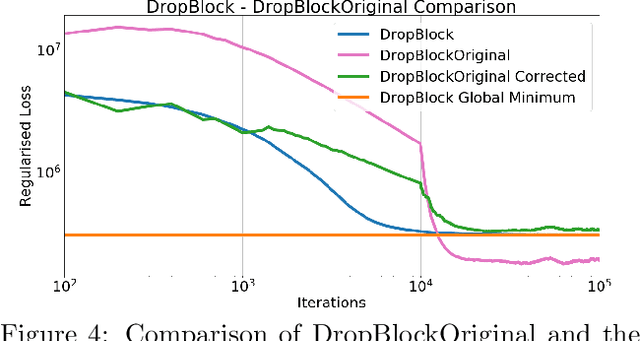
Dropout and its extensions (eg. DropBlock and DropConnect) are popular heuristics for training neural networks, which have been shown to improve generalization performance in practice. However, a theoretical understanding of their optimization and regularization properties remains elusive. Recent work shows that in the case of single hidden-layer linear networks, Dropout is a stochastic gradient descent method for minimizing a regularized loss, and that the regularizer induces solutions that are low-rank and balanced. In this work we show that for single hidden-layer linear networks, DropBlock induces spectral k-support norm regularization, and promotes solutions that are low-rank and have factors with equal norm. We also show that the global minimizer for DropBlock can be computed in closed form, and that DropConnect is equivalent to Dropout. We then show that some of these results can be extended to a general class of Dropout-strategies, and, with some assumptions, to deep non-linear networks when Dropout is applied to the last layer. We verify our theoretical claims and assumptions experimentally with commonly used network architectures.